







 本文介绍了多种经典的卷积神经网络架构,包括LeNet、AlexNet、VGG-Net、Inception系列、ResNet、DenseNet及轻量化网络等。详细解析了各网络的结构特点、优势与应用场景。
本文介绍了多种经典的卷积神经网络架构,包括LeNet、AlexNet、VGG-Net、Inception系列、ResNet、DenseNet及轻量化网络等。详细解析了各网络的结构特点、优势与应用场景。
目录
1. LeNet介绍
LeNet-5虽然提出的时间比较早,但它是一个非常成功 的神经网络模型,LeNet-5的网络结构如图所示。
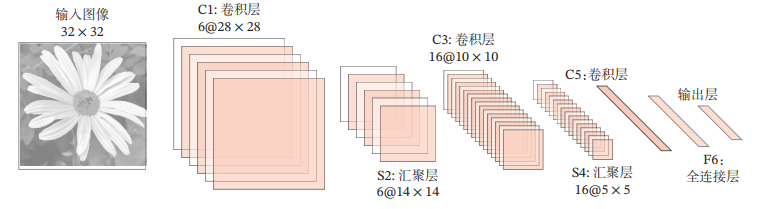
1.1 结构:LeNet-5 共包含 8 层
整体上是:输入层>卷积层>池化层+激活函数>卷积层>池化层+激活函数>卷积层>全连接层>输出层
输入层:N 个 32x32 的训练样本
输入图像大小为 32x32,比 MNIST 数据库中的字母大,这样做的原因是希望潜在的明显特征,如笔画断点或角点能够出现在最高层特征监测子感受野的中心。
(1) C1层是卷积层,使用6个5×5的卷积核,得到6组大小为28×28 = 784 的特征映射。因此,C1 层的神经元数量为 6 × 784 = 4 704,可训练参数数量为 6 × 25 + 6 = 156,连接数为156 × 784 = 122 304(包括偏置在内,下同)。
(2) S2 层为汇聚层,采样窗口为 2 × 2,使用平均汇聚,并使用一个非线性函数。神经元个数为 6 × 14 × 14 = 1 176,可训练参数数量为 6 × (1 + 1) = 12,连接数为6 × 196 × (4 + 1) = 5 880。
(3) C3 层为卷积层,LeNet-5 中用一个连接表来定义输入和输出特征映 射之间的依赖关系。共使用 60 个 5 × 5 的卷积核,得到 16 组大 小为 10 × 10 的特征映射。 神经元数量为 16 × 100 = 1 600,可训练参数数量为 (60 × 25) + 16 = 1 516,连接数为100 × 1 516 = 151 600。
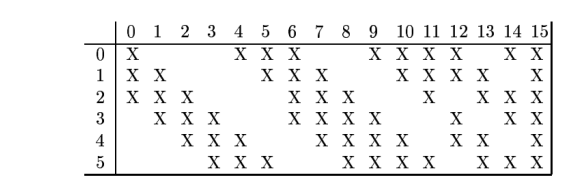
LeNet-5中C3层的连接表
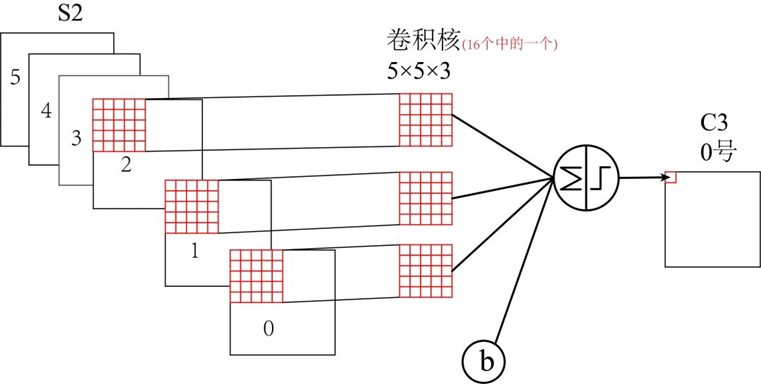 (4) S4层是一个汇聚层,采样窗口为2 × 2,得到16个5 × 5大小的特征映 射,可训练参数数量为16 × 2 = 32,连接数为16 × 25 × (4 + 1) = 2 000。
(4) S4层是一个汇聚层,采样窗口为2 × 2,得到16个5 × 5大小的特征映 射,可训练参数数量为16 × 2 = 32,连接数为16 × 25 × (4 + 1) = 2 000。
(5) C5 层是一个卷积层,使用 120 × 16 = 1 920 个 5 × 5 的卷积核,得到 120 组大小为 1 × 1 的特征映射。C5 层的神经元数量为 120,可训练参数数量为 1 920 × 25 + 120 = 48 120,连接数为120 × (16 × 25 + 1) = 48 120。
(6) F6层是一个全连接层,有84个神经元,可训练参数数量为84 × (120 + 1) = 10 164.连接数和可训练参数个数相同,为10 164。
(7) 输出层:输出层由10个径向基函数(Radial Basis Function,RBF)组 成,输入图像大小:1x84,输出特征图数量:1x10
1.2 代码实现
 https://blog.csdn.net/beilizhang/article/details/114483822
https://blog.csdn.net/beilizhang/article/details/1144838222. Alext Net
AlexNet是第一个现代深度卷积网络模型,其首次 使用了很多现代深度卷积网络的技术方法,比如使用 GPU 进行并行训练,采用 了 ReLU 作为非线性激活函数,使用 Dropout 防止过拟合,使用数据增强来提高 模型准确率等。AlexNet赢得了2012年ImageNet图像分类竞赛的冠军。
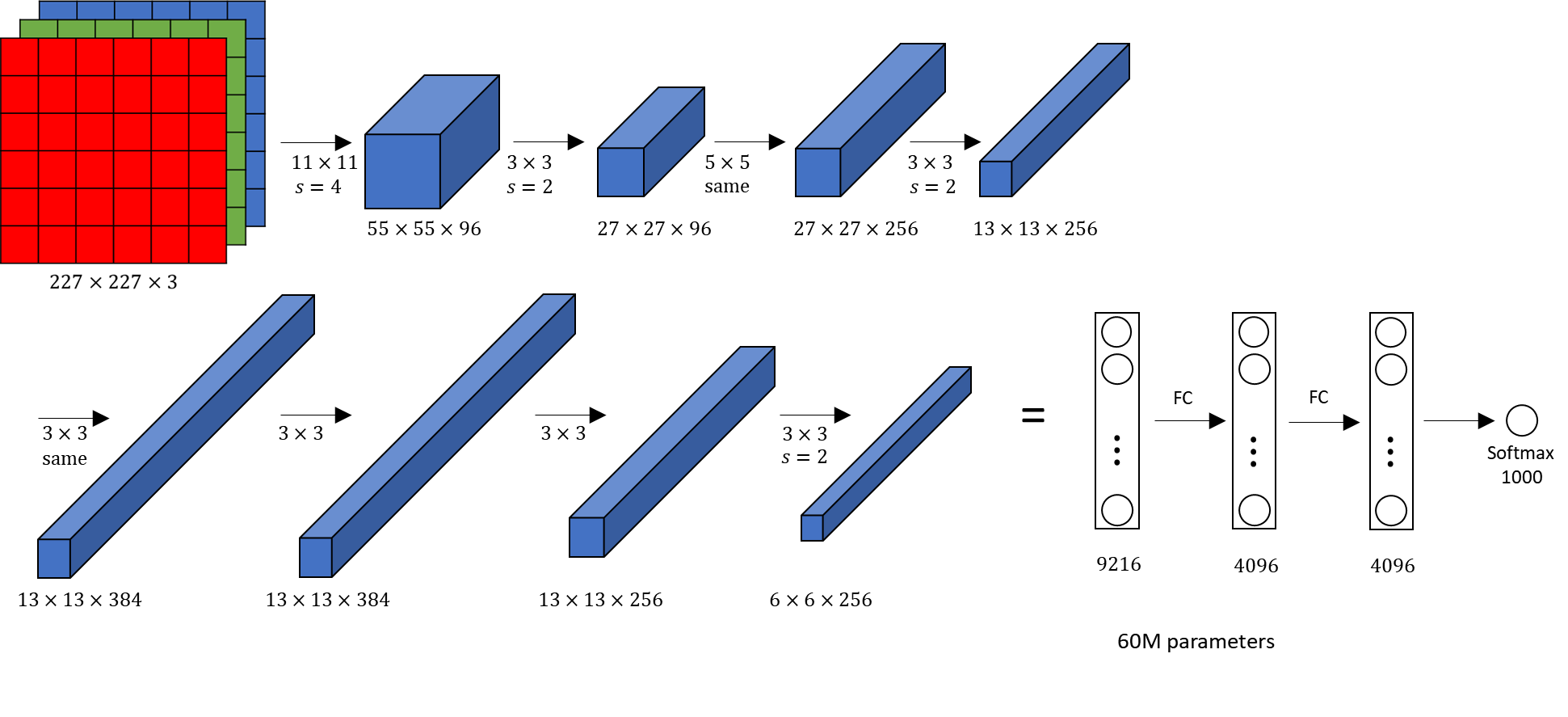 输入为224 × 224 × 3的图像,为后续处理方便,普遍改为227*227*3,输出为1 000个类别的条件概率。5个卷积层,3个池化层,3个全连接层
输入为224 × 224 × 3的图像,为后续处理方便,普遍改为227*227*3,输出为1 000个类别的条件概率。5个卷积层,3个池化层,3个全连接层
2.1 Alex Net 结构
第一层
卷积层1 为:11*11*3,有96个5*5卷积核,stride = 4,卷积层后跟ReLU,因此输出的尺寸为 (227-11)/4+1=55,因此其输出的每个特征图 为 55*55*96,同时后面经过LRN层处理,尺寸不变;
最大池化层1,池化核大小为3*3,stride = 2,Feature Map=(55-3)/2+1=27,因此特征图的大小为:27*27*96。
由于双gpu处理,故每组数据有27*27*48个特征图,共两组数据,分别在两个gpu中进行运算。
第二层
卷积层2,输入为上层输出:27*27*96,256个5*5卷积核,pad = 2, stride = 1; Feature Map= (27+2*2-5)/1+1=27,同时后面经过LRN层处理,尺寸不变;
最大池化层2,池化核大小为3*3,stride = 2,Feature Map=(27-3)/2+1=13,输出特征图13*13*256,双GPU,每组13*13*128。
第三层
卷积层3, 输入为第二层的输出13*13*128,384 个3*3卷积, padding = 1,stride=1,Feature Map= (13+2*1-3)/1+1=13 ,输出特征图13*13*384,每组13*13*192。
第四层
卷积层4 ,输入为第三层的输出13*13*192,384个3*3卷积核, padding = 1,stride=1,Feature Map= (13+2*1-3)/1+1=13 ,输出特征图13*13*384,每组13*13*192。
第五层
卷积层 5, 输入为第四层的输出13*13*192,256个3*3卷积核,padding = 1,stride = 1,Feature Map= (13+2*1-3)/1+1=13
最大池化3,然池化核大小为3*3,stride = 2,Feature Map=(13-3)/2+1=6,输出特征图6*6*256,每组6*6*128。
第六层 全连接层,4096 个神经元+ ReLU
第七层 全连接层,4096 个神经元+ ReLU
第八层 全连接层,1000个神经元
2.2 代码实现
3. VGG-Net
3.1 网络结构
VGG Net由牛津大学的视觉几何组(Visual Geometry Group)和 Google DeepMind公司的研究员一起研发的的深度卷积神经网络,VGGNet 探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠 3x3 的小型卷积核和 2x2 的最大池化层,VGGNet 成功地构筑了 16~19 层深的卷积神经网络,主要的贡献是展示出网络的深度(depth)是算法优良性能的关键部分。
VGG16包含了16个隐藏层(13个卷积层+3个全连接层),如图中的D列所示
VGG19包含了19个隐藏层(16个卷积层+3个全连接层),如图中的E列所示
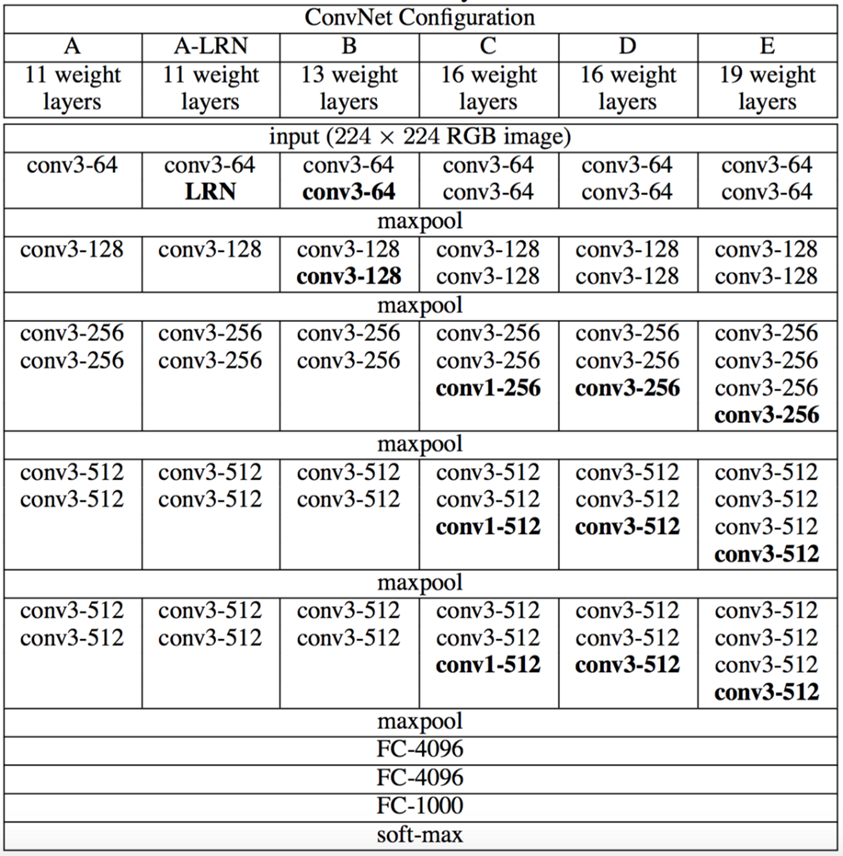
- 输入尺寸为 224 x 224 x 3 的图片,用64个3x3的卷积核作两次卷积和ReLU,卷积后的尺寸变为 224 x 224 x 64。
- 池化层,使用最大池化,池化单元大小为2x2,池化后尺寸变为112 x 112 x 64。
- 输入尺寸为112 x 112 x 64,使用128个3x3的卷积核作两次卷积和ReLU,尺寸改变为112 x 112 x 128。
- 池化层,使用最大池化,池化单元大小为2x2,池化后尺寸变为56 x 56 x 128。
- 输入尺寸为56 x 56 x 128,使用256个的卷积核作三次卷积和ReLU,尺寸改变为 56 x 56 x 256。
- 池化层,使用最大池化,池化单元大小为2x2,池化后尺寸变为28 x 28 x 256。
- 输入尺寸为28 x 28 x 256,使用512个的3x3卷积核作三次卷积和ReLU,尺寸改变为28 x 28 x 512。
- 池化层,使用最大池化,池化单元大小为2x2,池化后尺寸变为14 x 14 x 512。
- 输入尺寸为14 x 14 x 512,使用512个的3x3卷积核作三次卷积和ReLU,尺寸改变为14 x 14 x 512。
- 池化层,使用最大池化,池化单元大小为2x2,池化后尺寸变为7 x 7x 512
- 与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)。
- 通过softmax输出1000个预测结果。
改进点:
1.使用3x3小卷积核。为什么要采用三个3x3卷积,而不直接使用一个7x7卷积呢?主要有两个好处:
1)三个卷积可以进行三次非线性变换,而这种非线性变换能有效提升不同信息的判别性(差异);2)减小网络参数量。
2. 增加网络深度。增加网络深度的好处就是能够增加网络的非线性映射次数,使得网络能够提取具有更好的判决信息的特征,从而提升网络性能。因为使用了3x3卷积,使得网络参数量并不会随着网络的深度增加而急剧上升。除此之外,VGGNet还使用了1x1卷积,目的也是增加非线性映射次数 。
3.2 代码实现
4 Inception网络
4.1 为什么提出Inception
提高网络最简单粗暴的方法就是提高网络的深度和宽度,即增加隐层和以及各层神经元数目。但这种简单粗暴的方法存在一些问题:
- 会导致更大的参数空间,更容易过拟合
- 需要更多的计算资源
- 网络越深,梯度容易消失,优化困难(这时还没有提出BN时,网络的优化极其困难)
Inception系列模型提出的初衷主要为了解决CNN分类模型的两个问题,其一是如何使得网络深度增加的同时能使得模型的分类性能随着增加,而非像简单的VGG网络那样达到一定深度后就陷入了性能饱和的困境(Resnet针对的也是此一问题);其二则是如何在保证分类网络分类准确率提升或保持不降的同时使得模型的计算开销与内存开销充分地降低。
4.2 Inception-v1
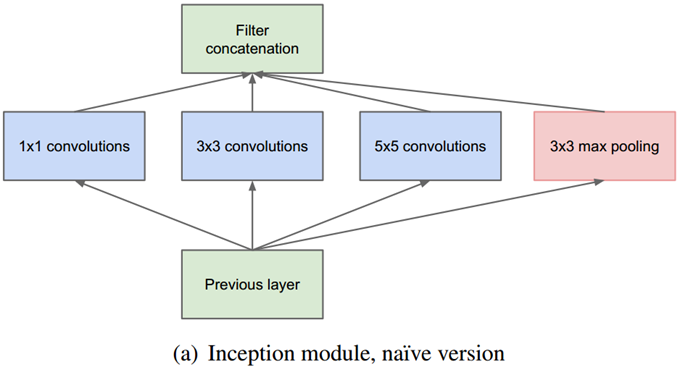
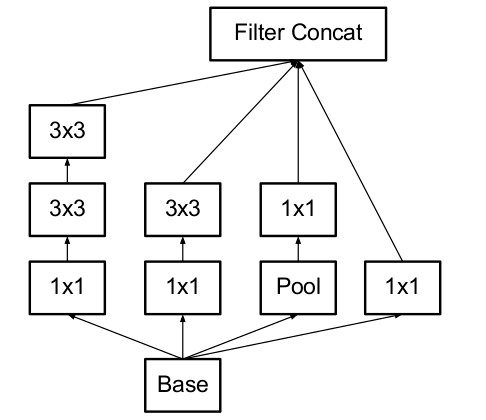
结构a有四个通道,有1*1、3*3、5*5卷积核,首先通过1x1卷积来降低通道数把信息聚集一下,再进行不同尺度的特征提取以及池化,得到多个尺度的信息,最后将特征进行叠加输出。采用大小不同的卷积核,意味着感受野的大小不同,就可以得到不同尺度的特征;采用比较大的卷积核即5*5,因为有些相关性可能隔的比较远,用大的卷积核才能学到此特征。
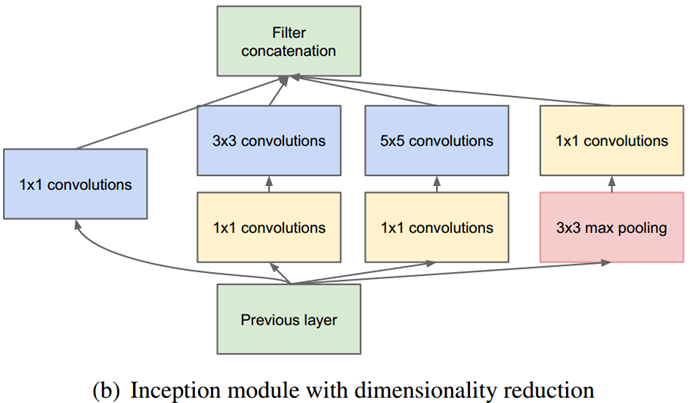
a 结构有个缺点,5*5的卷积核的计算量太大。作者想到了b结构,用1*1的卷积核进行降维。
这个1*1的卷积核,它的作用就是:降低维度,减少计算瓶颈;增加网络层数,提高网络的表达能力。
在Inception结构中,大量采用了1x1的矩阵作用:
1)对数据进行降维;2)引入更多的非线性,提高泛化能力,因为卷积后要经过ReLU激活函数。
4.3 Inception-v2
这篇论文主要思想在于提出了Batch Normalization,其次就是稍微改进了一下Inception。
1. 提出 Batch Normalization
对于一个神经网络,第n层的输入就是第n-1层的输出,在训练过程中,每训练一轮参数就会发生变化,对于一个网络相同的输入,但n-1层的输出却不一样,这就导致第n层的输入也不一样,为了解决这个问题提出的BN
BN层的计算流程是:计算样本均;计算样本方差;样本数据标准化处理;进行平移和缩放处理。
作用:加速网络训练;防止梯度消失,网络具有更好的泛化能力。
2. Inception V2 网络训练的技巧有:
使用更高的学习率;删除dropout层、LRN 层;减小L2 正则化的系数;
更快的衰减学习率;减少图片的形变。
4.4 Inception v3
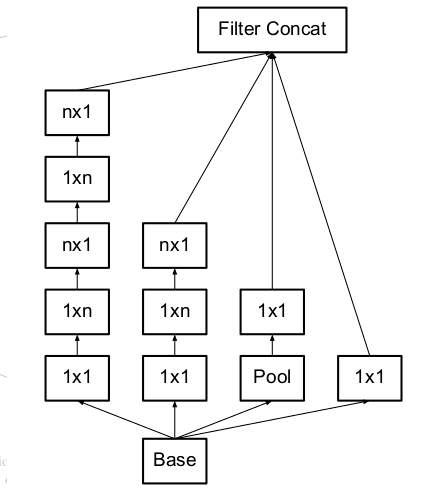
1. 分解卷积核尺寸:分解为对称的小的卷积核;分解为不对称的卷积核。
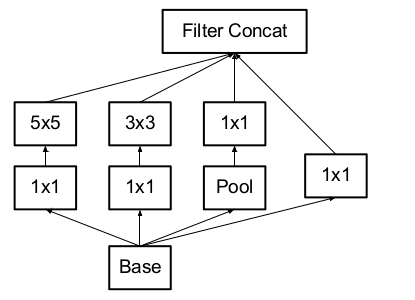
不对称分解方法有几个优点:
节约了大量的参数;增加一层非线性,提高模型的表达能力;可以处理更丰富的空间特征,增加特征的多样性
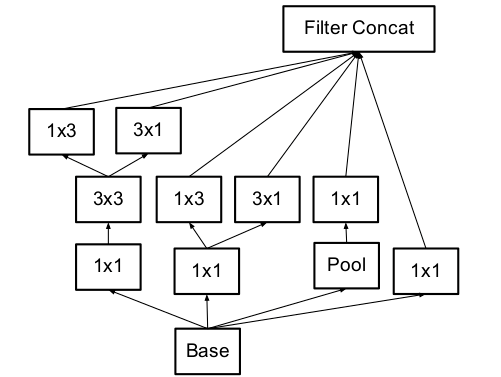
2. 使用辅助分类器优势:
Inception v1引进辅助的分类器去提高非常深的网络的收敛。引进辅助分类器的原始动机是加大梯度向更前层的流动(缓解梯度vanishing),从而加速训练过程中的收敛
把梯度有效的传递回去,不会有梯度消失问题,加快了训练;中间层的特征也有意义,空间位置特征比较丰富,有利于提成模型的判别力。
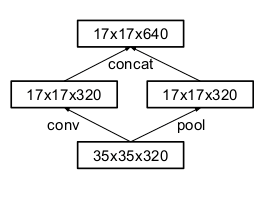
3.改变降低特征图尺寸的方式
传统的卷积神经网络,当有pooling时(pooling层会大量的损失信息),会在之前增加特征图的厚度(就是双倍增加滤波器的个数),来保持网络的表达能力,但是计算量会大大增加。
作者改进成两个通道,一个是卷积层,一个是pooling层,两个通道生成的特征图大小一样,concat在一起即可。
4.5 Inception-v4

Stem中使用了Inception V3中使用的并行结构、不对称卷积核结构,可以在保证信息损失足够小的情况下,使得计算量降低。结构中1*1的卷积核也用来降维,并且也增加了非线性。
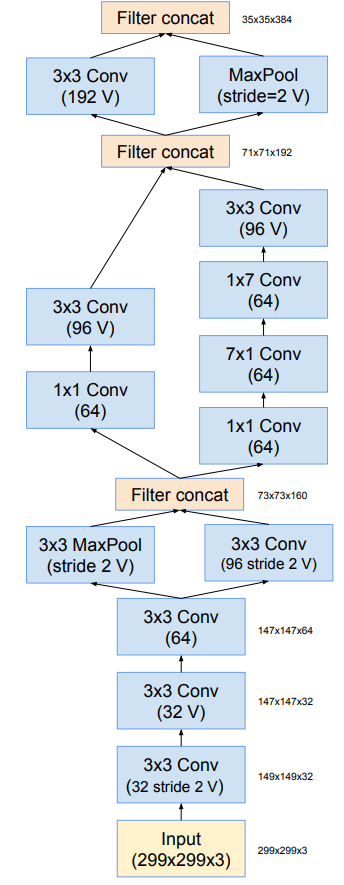
Inception-A/B/C模块
三种Inception block的个数分别为4、7、3个,而V3中为3、5、2个,因此新的Inception层次更深、结构更复杂,feature map的channel更多,为了降低计算量,在Inception-A和Inception-B后面分别添加了Reduction-A和Reduction-B的结构,用来降低计算量。
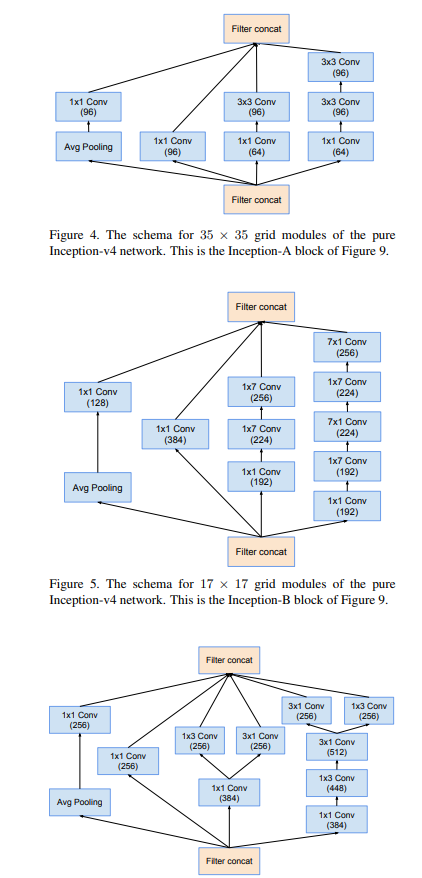
redution-A/B模块
这两种结构中,卷积的步长(stride)为2,并且都是用了valid padding,来降低feature map的尺寸。结构中同样是用并行、不对称卷积和1*1的卷积来降低计算量
5 残差网络ResNet
残差网络(Residual Network,ResNet) 通过给非线性的卷积层增加直连边 (Shortcut Connection)(也称为残差连接(Residual Connection))的方式来 提高信息的传播效率.
5.1 ResNet解决的是什么问题?
ResNets要解决的是深度神经网络的“退化”问题。
随着网络层级的不断增加,模型精度不断得到提升,而当网络层级增加到一定的数目以后,训练精度和测试精度迅速下降,这说明当网络变得很深以后,深度网络就变得更加难以训练了。随着网络深度的不断增大,所引入的激活函数也越来越多,数据被映射到更加离散的空间,此时已经难以让数据回到原点(恒等变换)。
残差网络通过给非线性的卷积层增加直连边(Shortcut Connection)(也称为残差连接)的方式来提高信息的传播效率。
梯度消失和梯度爆炸都有一定的缓解方法,比如换成使用ReLU函数作为激活函数,或者是在每层输入之后添加正则化层。但是即使用了正则化等手段,随着层数加深,但神经网络在训练集的准确度仍然会发生饱和甚至精度下降的问题。这个问题无法解释为过拟合,因为过拟合是在训练集上的准确率很高,在测试集上要低。而现在是神经网络在训练集上的准确率都下降了。研究者把这种现象称之为网络退化。
5.2 如何解决退化问题
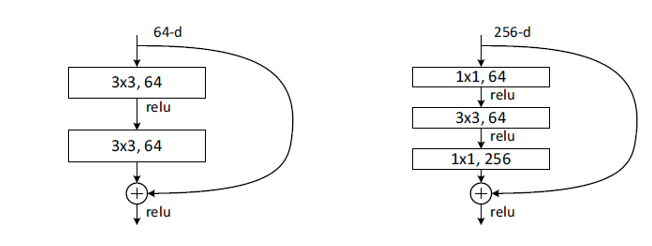
残差块:残差单元可以以跳层连接的形式实现,即将单元的输入直接与单元输出加在一起,然后再激活。因此残差网络可以轻松地用主流的自动微分深度学习框架实现,直接使用BP算法更新参数
假设在一个深度网络中,我们期望一个非线性单元(可以为一层或多层的卷积层)𝑓(𝒙; 𝜃) 去逼近一个目标函数为 ℎ(𝒙).如果将目标函数拆分成两部分:恒等函数(Identity Function)𝒙 和残差函数(Residue Function)ℎ(𝒙) – 𝒙。
目标函数为:ℎ(𝒙) = 𝒙+ (ℎ(𝒙) − 𝒙)
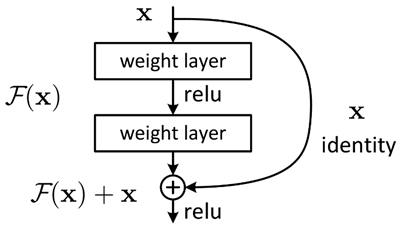
第一条直接向下传递的网络:试图从 x 中直接学习残差 F(x)
第二条捷径网络:输入 x
整合:将残差和x相加,即 H(x)=F(x)+x,也就是所要求的映射 H(x)
好处:只有一条通路的反向传播,会做连乘导致梯度消失,但现在有两条路,会变成求和的形式,避免梯度消失。后面的层可以看见输入,不至于因为信息损失而失去学习能力。
如果连乘的方式会造成梯度消失的话,那么连加。传统的网络每次学习会学习 x->f(x) 的完整映射,那么 ResNet 只学习残差的映射。
5.3 残差结构为什么有效?
自适应深度:网络退化问题就体现了多层网络难以拟合恒等映射这种情况,但使用了残差结构之后,拟合恒等映射变得很容易,直接把网络参数全学习到为0,只留下那个恒等映射的跨层连接即可。
“差分放大器”:假设最优H(x)更接近恒等映射,那么网络更容易发现除恒等映射之外微小的波动
模型集成:整个ResNet类似于多个网络的集成,原因是删除ResNet的部分网络结点不影响整个网络的性能
缓解梯度消失:针对一个残差结构对输入x求导就可以知道,由于跨层连接的存在,总梯度在F(x)对x的导数基础上还会加1。
6. DenseNet
模型介绍
在深度学习网络中,随着网络深度的加深,梯度消失问题会愈加明显,目前很多论文都针对这个问题提出了解决方案,比如ResNet,Highway Networks,Stochastic depth,FractalNets等,尽管这些算法的网络结构有差别,但是核心都在于:create short paths from early layers to later layers。那么作者是怎么做呢?延续这个思路,那就是在保证网络中层与层之间最大程度的信息传输的前提下,直接将所有层连接起来!
ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个 L 层的网络,DenseNet共包含 L(L+1)/2 个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
模型结构

为确保网络中各层之间的信息流动最大化,将所有层(具有匹配的特征图大小)直接连接起来,每一层从所有前面的层获得额外的输入,并将自己的特征映射传递给所有后面的层,在传统的工层网络 中引入了 L连接,而在 DenseNet 中引入了L(L +1)/2连接。
模型特性
缓解了梯度消失的问题
加强了特征的传播,鼓励重复利用特征.
极大地减少了参数个数
具有正则化的效果,即使在较少的训练集上,也可以减少过拟合的现象。
7 轻量化网络部分
7.1 SqueezeNet&SqueezeNext
模型介绍
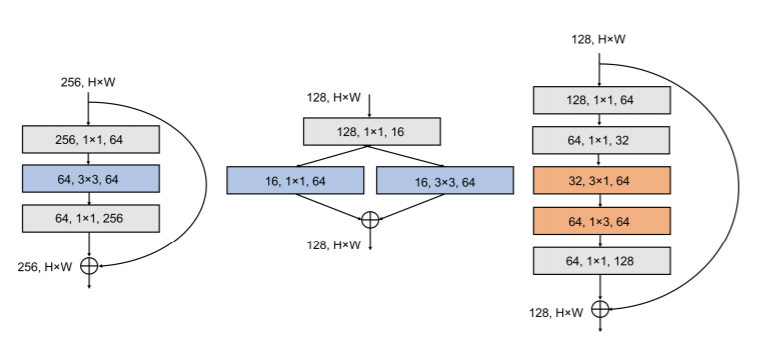
2016年,landola等提出了SqueezeNet轻量化网络,Fire module中主要包含了Squeeze层和Expand层,其中Squeeze层采用1 X 1的卷积核来减少参数量,Expand层则采用1 X 1和3 x 3卷积核分别得到对应特征图后进行拼接,由此得到Fire module的输出。利用卷积层、Fire module和池化层构建的SqueezeNet 模型大小只有4.8MB
2018 年,Gholam等基于SqueezeNet提出了改进版的SqueezeNext轻量化网络,其主要采用了如下图下部分所示的模块结构。该结构中采用通道数减半的两层Squeeze层对输入进行处理,然后通过3x 1和1 X 3搭配的低秩卷积核进行卷积,之后利用一个卷积层实现数据维度匹配。此外SqueezeNext借鉴ResNet网络结构思想实现了shortcut 连接


模型特性
SqueezeNet
使用1 X 1卷积核代3 x 3卷积核,减少参数量
通过squeeze layer限制通道数量,减少参数量;
借鉴Inception思想,将1 X 1和3 x 3卷积后结果进行concat; 为了使其feature map的size相同3 x 3卷积核进行了padding;
减少池化层,并将池化操作延后,给卷积层带来更大的激活层,保留更多地信息,提高准确率:
使用全局平均池化代替全连接层
SqueezeNext
(1)Low Rank Filters
将3*3卷积分解为:3*1+1*3,实现低秩滤波器从而减少网络参数。
(2)SqueezeNext Block
提出了如图所示先利用两个1*1卷积核进行降维减少输入通道数,再通过两个低秩滤波器,最后通过再升维。
(3)shortcut
引入了万能提升网络效果的shortcut策略。
7.2 Ghostnet
Ghostnet出自华为诺亚方舟实验室,传统的深度学习网络中存在着大量冗余,但是对模型的精度至关重要的特征图。这些特征图是由卷积操作得到,又输入到下一个卷积层进行运算,这个过程包含大量的网络参数,消耗了大量的计算资源。
作者考虑到这些feature map层中的冗余信息可能是一个成功模型的重要组成部分,正是因为这些冗余信息才能保证输入数据的全面理解,所以作者在设计轻量化模型的时候并没有试图去除这些冗余feature map,而是尝试使用更低成本的计算量来获取这些冗余feature map。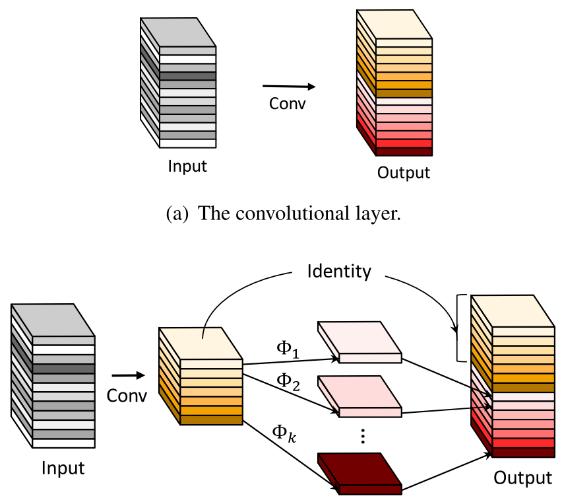
Ghost卷积部分将传统卷积操作分为两部分:
第一步,使用少量卷积核进行卷积操作(比如正常用64个,这里就用32个,从而减少一半计算量)
第二步,使用3×3或5×5的卷积核进行逐通道卷积操作(Cheap operations)
最终将第一部分作为一份恒等映射(Identity),与第二步的结果进行Concat操作
GhostBottleneck部分有两种结构:
- stride=1,不进行下采样时,直接进行两个Ghost卷积操作
- stride=2,进行下采样时,多出来一个步长为2的深度卷积操作
7.3 MobileNetV3
MobileNetV3,是谷歌在2019年3月21日提出的轻量化网络架构,在前两个版本的基础上,加入神经网络架构搜索(NAS)和h-swish激活函数,并引入SE通道注意力机制,性能和速度都表现优异,受到学术界和工业界的追捧。
主要特点:
论文推出两个版本:Large 和 Small,分别适用于不同的场景
网络的架构基于NAS实现的MnasNet(效果比MobileNetV2好),由NAS搜索获取参数
引入MobileNetV1的深度可分离卷积
引入MobileNetV2的具有线性瓶颈的倒残差结构
引入基于squeeze and excitation结构的轻量级注意力模型(SE)
使用了一种新的激活函数h-swish(x)
网络结构搜索中,结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt
修改了MobileNetV2网络端部最后阶段
模型概述:
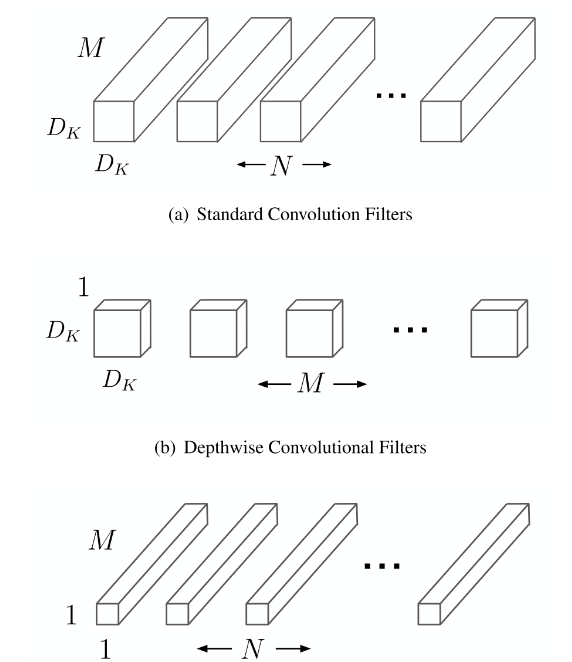
Mobilenetv1提出了深度可分离卷积,就是将普通卷积拆分成为一个深度卷积(Depthwise Convolutional Filters)和一个逐点卷积(Pointwise Convolution):
Depthwise Convolutional Filters:将卷积核拆分成为单通道形式,在不改变输入特征图像深度的情况下,对每一通道进行卷积操作,这样就得到了和输入特征图通道数一致的输出特征图,这样就会有一个问题,通道数太少,特征图的维度太少,能获取到足够的有效信息吗?
Pointwise Convolution:逐点卷积就是1×1卷积,主要作用就是对特征图进行升维和降维,在深度卷积的过程中,假设得到了8×8×3的输出特征图,我们用256个1×1×3的卷积核对输入特征图进行卷积操作,输出的特征图和标准的卷积操作一样都是8×8×256了
逆残差结构

深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道,如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要“扩张”通道。
既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征,这样不管输入通道数是多少,经过第一个PW逐点卷积升维之后,深度卷积都是在相对的更高6倍维度上进行工作。
Inverted residuals:为了像Resnet一样复用特征,引入了shortcut结构,采用了 1×1 -> 3 ×3 -> 1 × 1 的模式,但是不同点是:
ResNet 先降维 (0.25倍)、卷积、再升维
Mobilenetv2 则是 先升维 (6倍)、卷积、再降维
SE通道注意力

SE通道注意力出自论文:《Squeeze-and-excitation networks.》,主要是探讨了卷积神经网络中信息特征的构造问题,而作者提出了一种称为“Squeeze-Excitation(SE)”的组件:
SE组件的作用是:可以通过显示地建模通道之间的相互依存关系来增强通道级的特征响应(说白了就是学习一组权重,将这组权重赋予到每一个通道来进一步改善特征表示),使得重要特征得到加强,非重要特征得到弱化
具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征
7.4 ShuffleNet 网络结构
当前先进的轻量化网络大都使用深度可分离卷积或者组卷积,以降低网络的计算量,但这两种操作都无法改变特征的通道数,因此还需要使用1×1 卷积来促进通道之间信息的融合并改变通道至指定维度。因此,轻量化网络中1×1 卷积占据了大量的计算,并且致使通道之间充满约束,一定程度上降低了模型的精度。
为了进一步降低计算量,ShuffleNet 提出了通道混洗来完成通道之间信息的融合
各部分的 feature map 的channel进行有序的打乱,构成新的 feature map,以解决 group convolution 带来的“信息流通不畅”问题。
创新点:利用 group convolution 和 channel shuffle 着两个操作来设计卷积神经网络模型,以减少模型使用的参数数量
四条轻量化网络设计准则,对输入输出通道、分组卷积组数、网络碎片化程度、逐元素操作对不同硬件上的速度和内存访问量MAC(Memory Access Cost)的影响进行了详细分析:
准则一:输入输出通道数相同时,内存访问量MAC最小
Mobilenetv2就不满足,采用了拟残差结构,输入输出通道数不相等
准则二:分组数过大的分组卷积会增加MAC
Shufflenetv1就不满足,采用了分组卷积(GConv)
准则三:碎片化操作(多通路,把网络搞的很宽)对并行加速不友好
Inception系列的网络
准则四:逐元素操作(Element-wise,例如ReLU、Shortcut-add等)带来的内存和耗时不可忽略
Shufflenetv1就不满足,采用了add操作
Shufflenetv2有两个结构:basic unit和unit from spatial down sampling(2×)
basic unit:输入输出通道数不变,大小也不变
unit from spatial down sample :输出通道数扩大一倍,大小缩小一倍(降采样)
为了解决GConv(Group Convolution)导致的不同group之间没有信息交流,只在同一个group内进行特征提取的问题,Shufflenetv2设计了channel shuffle 操作进行通道重排,跨group信息交流
v2 提出了 Channel Split 操作,如 (c ) 所示,将输入特征分成两部分,一部分进行真正的深度可分离计算,将计算结果与另一部分进行通道 Concat,最后进行通道的混洗操作,完成信息的互通。同时,整个过程没有使用到 1×1 组卷积,也避免了逐点相加的操作。在需要降采样与通道翻倍时,ShuffleNet v2 去掉了 Channel Split 操作,这样最后 Concat 时通道数会翻倍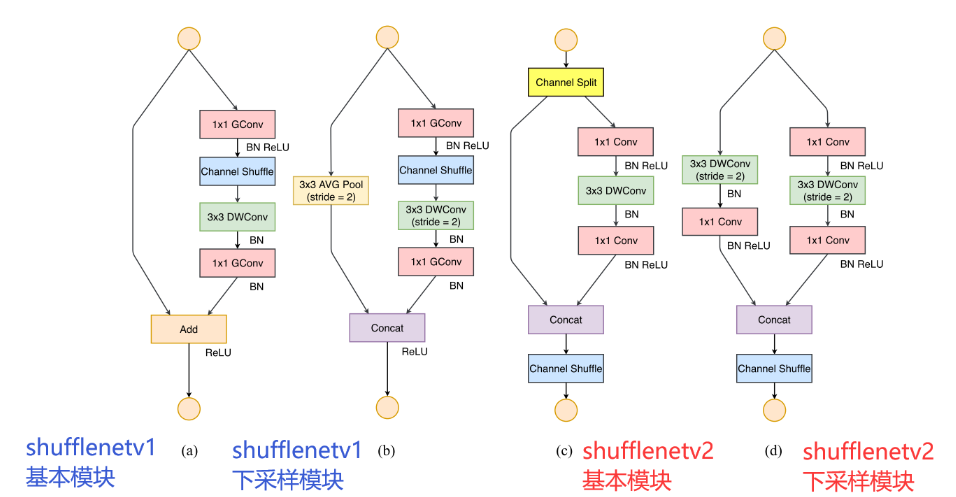
7.5 Xception
模型介绍
Xception是谷歌于 2017 年在 Inception V3的基础上,基于空间相关性和通道相关性设计的轻量化网络结构,虽然深度可分离卷积可大幅减少计算量,又能保持较高的分类精度,但是存在计算零散的问题,Xception的设计理念就是为了解决这一问题。
模型结构

Xception模块与深度可分离卷积的不同之处在于:
1)深度可分离卷积先进行同一平面卷积得到空间相关性,再在不同通道之间进行卷积得到通道相关性,而Xception模块采用相反的方法,先得到通道之间的相关性,再学习空间相关性;
2)Xception在空间相关性和通道相关性的学习过程中未使用激活函数,实验证明这一改进有效地加快了收敛速度,提升了网络性能。
Xception 网络基于残差网络进行构建,但将其中的卷积层换成了Xception模块。如上图所示Xception 网络被分为输入流部分、中间流部分和输出流部分,其中,ReLU表示激活函数SeparableConv表示深度可分离卷积,Maxpool表示最大值池化操作。输入流部分通过下采样模块来降低特征图的空间维度,中间流部分通过优化网络特征提取来学习关联关系,输出流部分将特征进行汇总输出,最终由全连接层进行表达。
模型特性
Xception作为Inception v3的改进,主要是在Inception v3的基础上引入了depthwise separable convolution,在基本不增加网络复杂度的前提下提高了模型的效果。


















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









