







文章目录
- (一)概率论数理统计中的概念
- (二)统计分析的常见指标
- (三)统计分析的特点
- (四)统计分析的基本步骤
- (四)数据统计分析pandas工具使用(共12节入门教程)
-
- pandas学习笔记(一):对象创建(Object creation)
- pandas学习笔记(二):查看数据(Viewing data)
- pandas学习笔记(三):选择(Selection)
- pandas学习笔记(四):数据缺失(Missing data)
- pandas学习笔记(五):操作(Operations)
- pandas学习笔记(六):合并(Operations)
- pandas学习笔记(七):分组(Grouping)
- pandas学习笔记(八):重塑(Reshaping)
- pandas学习笔记(九):时间序列(Time series)
- pandas学习笔记(十):分类(Categoricals)
- pandas学习笔记(十一):绘图(Plotting)
- pandas学习笔记(十二):数据的输入与输出(Getting data in/out)
- 附:参考资料
(一)概率论数理统计中的概念
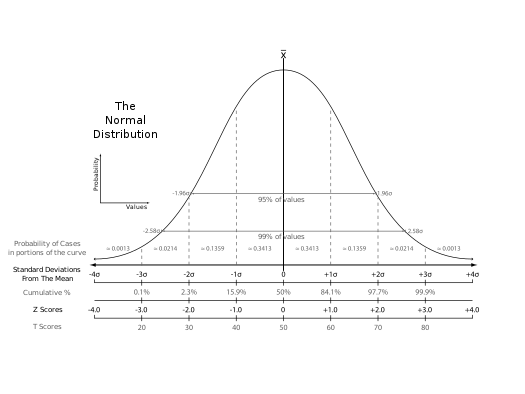
(1)随机分布
随机变量(random variable) 表示随机试验各种结果的实值单值函数。随机事件不论与数量是否直接有关,都可以数量化,即都能用数量化的方式表达。
按照随机变量可能取得的值,可以把它们分为两种基本类型
- 1、离散型随机变量,即在一定区间内变量取值为有限个,或数值可以一一列举出来。例如某地区某年人口的出生数、死亡数,某药治疗某病病人的有效数、无效数等。
- 2、连续型随机变量,即在一定区间内变量取值有无限个,或数值无法一一列举出来。例如某地区男性健康成人的身长值、体重值,一批传染性肝炎患者的血清转氨酶测定值等。

(2)统计分布
统计分布(frequency distribution)亦称“次数(频数)分布(分配)” 。在统计分组的基础上,将总体中的所有单位按组归类整理,形成总体单位在各组间的分布。
分布在各组中的单位数叫做次数或频数。各组次数与总次数(全部总体单位数)之比,称为比率或频率。将各组别与次数依次编排而成的数列就叫做统计分布数列,简称分布数列或分配数列。
(二)统计分析的常见指标
(1)均值,方差,标准差,中位数,众数
- 均值:平均数,统计学术语,是表示一组数据集中趋势的量数,是指在一组数据中所有数据之和再除以这组数据的个数。
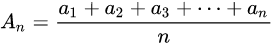
- 方差:方差是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。

- 标准差:标准差(Standard Deviation) ,是离均差平方的算术平均数的平方根,用σ表示。在概率统计中最常使用作为统计分布程度上的测量。标准差是方差的算术平方根。 标准差能反映一个数据集的离散程度。平均数相同的两组数据,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









