







JVM内存结构和Java内存模型都是面试的热点问题,名字看感觉都差不多,网上有些博客也都把这两个概念混着用,实际上他们之间差别还是挺大的。
通俗点说,JVM内存结构是与JVM的内部存储结构相关,而Java内存模型是与多线程编程相关,本文针对这两个总是被混用的概念展开讲解。
JVM内存结构
JVM构成
说到JVM内存结构,就不会只是说内存结构的5个分区,而是会延展到整个JVM相关的问题,所以先了解下JVM的构成。
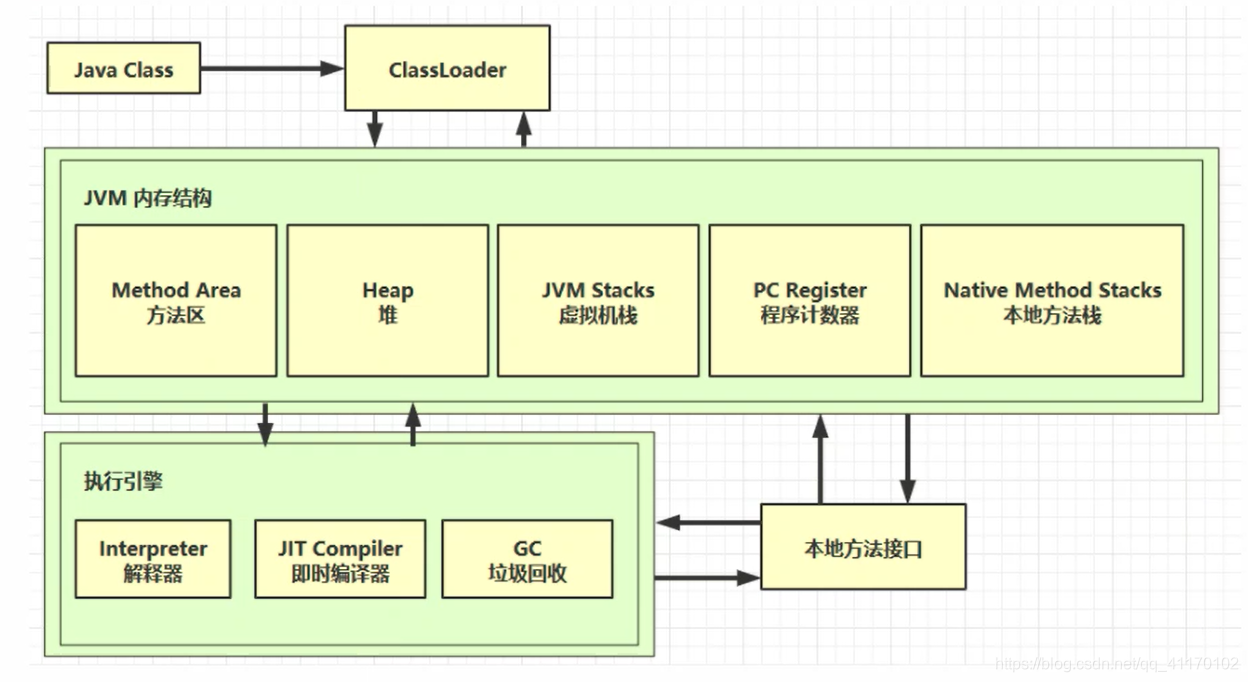
- Java源代码编译成Java Class文件后通过类加载器ClassLoader加载到JVM中
- 类存放在方法区中
- 类创建的对象存放在堆中
- 堆中对象的调用方法时会使用到虚拟机栈,本地方法栈,程序计数器
- 方法执行时每行代码由解释器逐行执行
- 热点代码由JIT编译器即时编译
- 垃圾回收机制回收堆中资源
- 和操作系统打交道需要调用本地方法接口
JVM内存结构
程序计数器
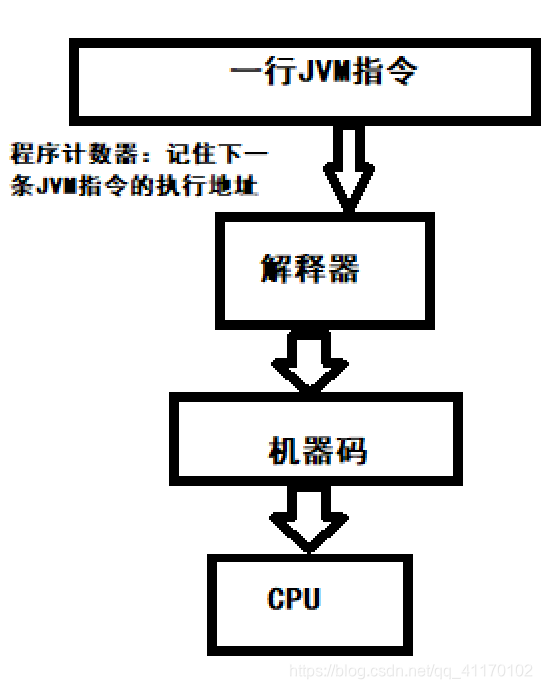
(通过移位寄存器实现)
- 程序计数器是线程私有的,每个线程单独持有一个程序计数器
- 程序计数器不会内存溢出
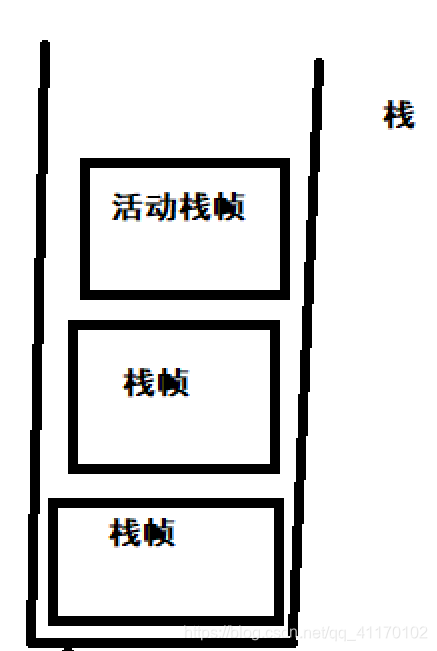
虚拟机栈
-
栈:线程运行需要的内存空间
-
栈帧:每一个方法运行需要的内存(包括参数,局部变量,返回地址等信息)
-
每个线程只有一 个活动栈帧(栈顶的栈帧),对应着正在执行的代码
-
常见问题解析
-
垃圾回收是否涉及栈内存:不涉及,垃圾回收只涉及堆内存
-
栈内存分配越大越好吗:内存一定时,栈内存越大,线程数就越少,所以不应该过大
-
方法内的局部变量是否是线程安全的:
- 普通局部变量是安全的
- 静态的局部变量是不安全的
- 对象类型的局部变量被返回了是不安全的
- 基本数据类型局部变量被返回时安全的
- 参数传入对象类型变量是不安全的
- 参数传入基本数据类型变量时安全的
-
栈内存溢出(StackOverflowError)
-
栈帧过多
- 如递归调用没有正确设置结束条件
-
栈帧过大
- json数据转换 对象嵌套对象 (用户类有部门类属性,部门类由用户类属性)
-
线程运行诊断
-
CPU占用过高(定位问题)
- ‘top’命令获取进程编号,查找占用高的进程
- ‘ps H -eo pid,tid,%cpu | grep 进程号’ 命令获取线程的进程id,线程id,cpu占用
- 将查看到的占用高的线程的线程号转化成16进制的数 :如6626->19E2
- ‘ jstack 进程id ’获取进程栈信息, 查找‘nid=0X19E2’的线程
- 问题线程的最开始‘#数字’表示出现问题的行数,回到代码查看
-
程序运行很长时间没有结果(死锁问题)
- ‘ jstack 进程id ’获取进程栈信息
- 查看最后20行左右有无‘Fount one Java-level deadlock’
- 查看下面的死锁的详细信息描述和问题定位
- 回到代码中定位代码进行解决
-
-
-
本地方法栈
- 本地方法栈为虚拟机使用到的 Native 方法服务
- Native 方法是 Java 通过 JNI 直接调用本地 C/C++ 库,可以认为是 Native 方法相当于 C/C++ 暴露给 Java 的一个接口
- 如notify,hashcode,wait等都是native方法
堆
-
通过new关键字创建的对象都会使用堆内存
-
堆是线程共享的
-
堆中有垃圾回收机制
-
堆内存溢出(OutOfMemoryError)
- 死循环创建对象
-
堆内存诊断
-
命令行方式
- ‘jps’获取运行进程号
- ‘jmap -heap 进程号’查看当前时刻的堆内存信息
-
jconsole
- 命令行输入jconsole打开可视化的界面连接上进程
- 可视化的检测连续的堆内存信息
-
jvisualvm
- 命令行输入jvisualvm打开可视化界面选择进程
- 可视化的查看堆内存信息
-
方法区
- 方法区只是一种概念上的规范,具体的实现各种虚拟机和不同版本不相同
- HotSpot1.6 使用永久代作为方法区的实现
- HotSpot1.8使用本地内存的元空间作为方法区的实现(但StringTable还是放在堆中)
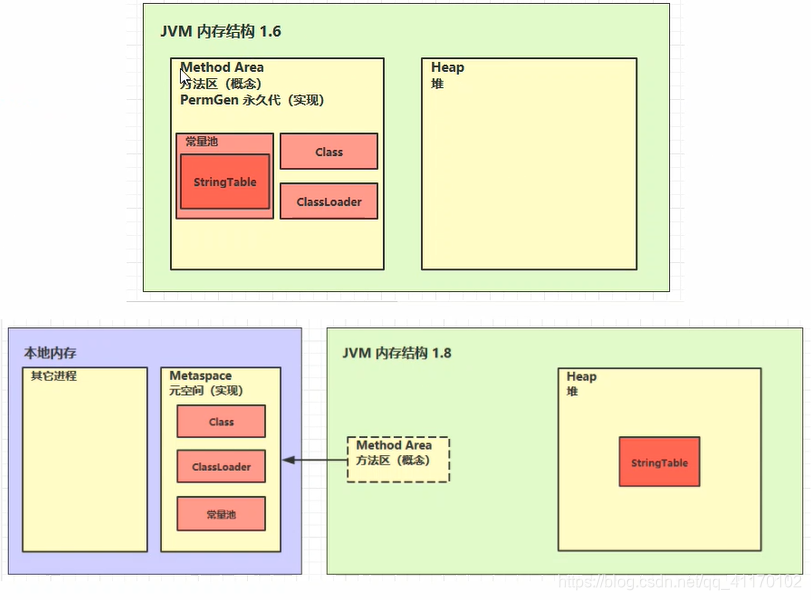
- 常见问题
-
StringTable特性
-
常量池中的字符串仅是字符,第一次使用时才变为对象
-
利用串池机制,避免重复创建字符串
-
字符串常量拼接原理是StringBuilder(1.8)
-
字符串常量拼接原理是编译器优化
-
StringTable在1.6中存放在永久代,在1.8中存放在堆空间
-
intern方法主动将串池中没有的字符串对象放入串池
-
1.8中:尝试放入串池,如果有就不放入,只返回一个引用;如果没有就放入串池,同时返回常量池中对象引用
-
1.6中:尝试放入串池,如果有就不放入,只返回一个引用;如果没有就复制一个放进去(本身不放入),同时返回常量池中的对象引用
-
字符串常量池分析(1.8环境)
String s1 = "a"; String s2 = "b"; String s3 = "a"+"b"; String s4 = s1+s2; String s5 = "ab"; String s6 = s4.intern(); System.out.println(s3==s4);// s3在常量池中,s4在堆上(intern尝试s4放入常量池,因为ab存在了就拒绝放入返回ab引用给s6,s4还是堆上的) System.out.println(s3==s5);// s3在常量池中,s4也在常量池中(字符串编译期优化) System.out.println(s3==s6);// s3在常量池中,s6是s4的intern返回常量池中ab的引用,所以也在常量池中 String x2 = new String("c")+new String("d"); String x1 = "cd"; x2.intern(); System.out.println(x1==x2);//x2调用intern尝试放入常量池,但常量池中已经有cd了,所以只是返回一个cd的引用,而x2还是堆上的引用
-
-
-
JVM调优三大参数(如: java -Xms128m -Xmx128m -Xss256k -jar xxxx.jar)
- -Xss:规定了每个线程虚拟机栈的大小(影响并发线程数大小)
- -Xms:堆大小的初始值(超过初始值会扩容到最大值)
- -Xmx:堆大小的最大值(通常初始值和最大值一样,因为扩容会导致内存抖动,影响程序运行稳定性)
-
JVM内存结构中堆和栈的区别
- 管理方式:栈自动释放,堆需要GC
- 空间大小:栈比堆小
- 碎片:栈产生的碎片远少于堆
- 分配方式:栈支持静态分配和动态分配,堆只支持动态分配
- 效率:栈的效率比堆高
-
GC垃圾回收机制
1. 垃圾判别方法
引用计数算法
-
判断对象的引用数量来决定对象是否可以被回收
-
每个对象实例都有一个引用计数器,被引用则+1,完成引用则-1
-
优点:执行效率高,程序执行受影响小
-
缺点:无法检测出循环引用的情况,导致内存泄露
可达性分析算法
-
Java虚拟机中的垃圾回收器采用可达性分析来探索所有存活对象
-
扫描堆中的对象,看是否能沿着GC Root对象为起点的引用链找到该对象,找不到则可以回收
-
哪些对象可以作为GC Root
-
通过System Class Loader或者Boot Class Loader加载的class对象,通过自定义类加载器加载的class不一定是GC Root
-
虚拟机栈中的引用的对象
-
本地方法栈中JNI(natice方法)的引用的对象
-
方法区中的常量引用的对象
-
方法区中的类静态属性引用的对象
-
处于激活状态的线程
-
正在被用于同步的各种锁对象
-
GC保留的对象,比如系统类加载器等。
-
2. 垃圾回收算法
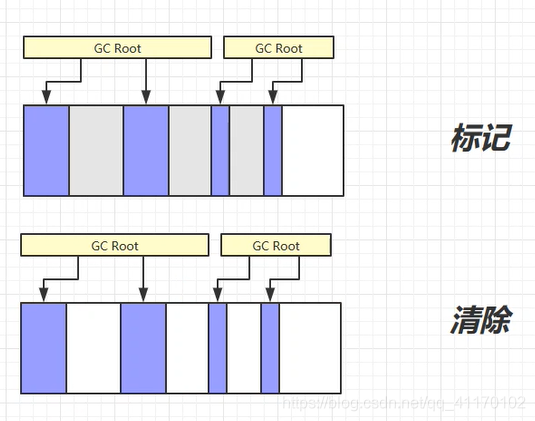
标记清除法
- 标记没有被GC Root引用的对象
- 清除被标记位置的内存
- 优点:处理速度快
- 缺点:造成空间不连续,产生内存碎片
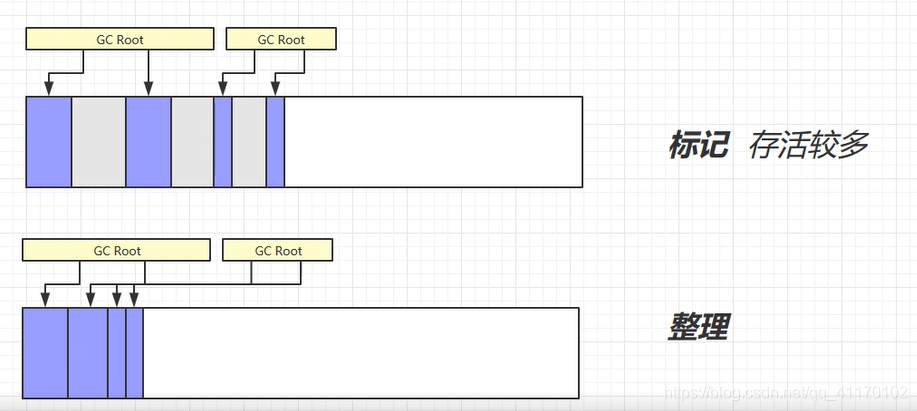
标记整理法
- 标记没有被GC Root引用的对象
- 整理被引用的对象
- 优点:空间连续,没有内存碎片
- 缺点:整理导致效率较低
复制算法
- 分配同等大小的内存空间
- 标记被GC Root引用的对象
- 将引用的对象连续的复制到新的内存空间
- 清除原来的内存空间
- 交换FROM空间和TO空间
- 优点:空间连续,没有内存碎片
- 缺点:占用双倍的内存空间
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









