






一、 背景
最近这两周在UCloud公司实习,第一周尝试了云计算,第二周尝试并研究了大数据生态中的hadoop、yarn、spark、mapreduce等技术,并在公司提供的云主机上分别安装了hadoop伪分布式模式、hadoop分布式模式、yarn、spark以及在hadoop分布式模式上提交与查看作业。
本文介绍在一台云主机上安装hadoop伪分布式模式。
二、 实验目标
在一台云主机上安装hadoop,并修改hadoop的相关配置文件,以实现hadoop伪分布式模式,能够让主机与hdfs互相上传和下载文件。
三、 实验环境
云主机操作系统:CentOS7
jdk.1.8.0_191及以上已安装,具体JAVA版本与hadoop版本的对应关系,请参考https://cwiki.apache.org/confluence/display/HADOOP2/HadoopJavaVersions
四、 实验过程
1.安装JAVA环境
下载JAVA的rpm包,安装
输入java –version,显示JAVA版本,说明安装JAVA成功
2.去官网下载hadoop包:http://www.apache.org/dyn/closer.cgi/hadoop/common/
这里选择hadoop2.8.5

3.将下载的hadoop-2.8.5.tar.gz通过winscp传入主机中

4.解压到云主机,位置自定
5.在~./bashrc 文件中,加入如下语句:
export HADOOP_HOME=/opt/module/bigdata/hadoop2.8.5
export PATH=
H
A
D
O
O
P
H
O
M
E
/
b
i
n
:
HADOOP_HOME/bin:
HADOOPHOME/bin:HADOOP_HOME/sbin:$PATH
6.重启主机,输入echo $HADOOP_HOME,查看HADOOP路径设置是否生效

7. 输入echo $PATH,查看HADOOP路径设置是否生效
8.输入hadoop version,查看hadoop版本,并验证hadoop是否安装成功

9.
yum install ssh;
yum install pdsh
10.配置hadoop-env.sh
加入如下语句:
export JAVA_HOME=/opt/module/jdk/jdk1.8.0_191

10.配置core-site.xml
加入下图所示的语句:
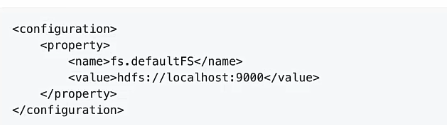

11.配置hdfs-site.xml
加入下图所示的语句:

12.配置ssh,达到输入ssh localhost可以免密登录,具体过程较为繁琐,因为本篇博客是记录安装hadoop伪分布式模式的过程,所以这里不再赘述。
13.格式化namenode

14.运行sbin/start-dfs.sh,开启守护进程,并输入jps指令,查看现运行进程中有无守护进程

15.通过bin/hdfs dfs –put local_file hdfs_file,向hdfs中上传文件(local_file和hdfs_file为象征性的名字,具体文件自定),上传后,输入hdfs dfs –ls –R /查看hdfs中的文件,发现上传成功

16.通过bin/hdfs dfs –get hdfs_file local_file,从hdfs中下载文件(local_file和hdfs_file为象征性的名字,具体文件自定),下载后,查看local_file所在目录,看local_file是否是下载的文件,发现下载成功

17.修改配置文件mapred-site.xml
将下图所示语句,加入配置文件
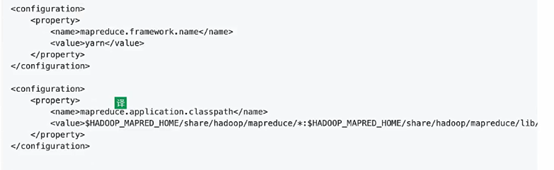

18.修改配置文件yarn-site.xml
将下图所示语句,加入配置文件


19.执行sbin/start-yarn.sh,查看yarn是否配置成功

五、 收获及心得
本周,在公司工程师前辈的带领下,我开始了大数据方面的学习与实验。工程师主要讲解了大数据的应用场景以及大数据场景下的数据处理的步骤和常用技术栈。
大数据的典型应用场景就是用户画像,比如每个人打开的淘宝页面是不同的,因为算法根据用户之前浏览的记录和行为习惯数据,进行个性化推荐(淘宝的商品、今日头条的新闻等),体现了千人千面的思想。
大数据场景下的数据处理的步骤主要有5步,分别为数据采集、数据预处理(可选)、数据存储、数据分析与数据应用。其中,数据采集的工作是采集比较格式化的数据,如注册信息,还有一些非格式化的数据,如网站或视频的浏览信息、搜索习惯信息、购买习惯信息等;数据预处理的主要工作是把一些异常、非法数据剔除,把非格式化的数据转换为需要的格式化的数据。关于技术栈,数据采集通常利用Flume、Logstash等工具,可以实时采集数据,方便接下来的数据分析;数据存储主要用到Ufile、HDFS、MPP数据库等技术。
这次实验,需要在一台云主机上配置伪分布式模式的hadoop,参考资料主要是官方文档。算上查阅资料和不断的试错,我花了两天时间配置完成。
这是是第一次照着官方文档配置一个环境(以前都是在网上直接搜教程),配了一会发现,这次官方文档的坑,主要是它的文件路径与自己的文件路径可能并不相同,所以在配置一些路径的时候,不能照搬,而是要根据自己的文件目录结构来进行,否则后面的步骤就没法正确进行。
希望我可以收获每一天,快乐每一天!
六、 技术支撑
UCloud云主机
七、 参考资料
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html














 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









