







从零开始学习深度学习技术路线-以语义分割算法Unet为例
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
我不生产内容,我只是大自然的搬运工。适合有编程基础的人看。(电脑是windowXp系统)
效果图(训练70个世代之后)

一、Anconda是什么
创建虚拟环境各种安装依赖、编辑器的工具平台,开发者的专属应用商店,需要什么就往这儿找。
二、Anconda安装
自己百度去。
注意的点:
第一、安装要正确
一定是安装Anaconda而不是conda
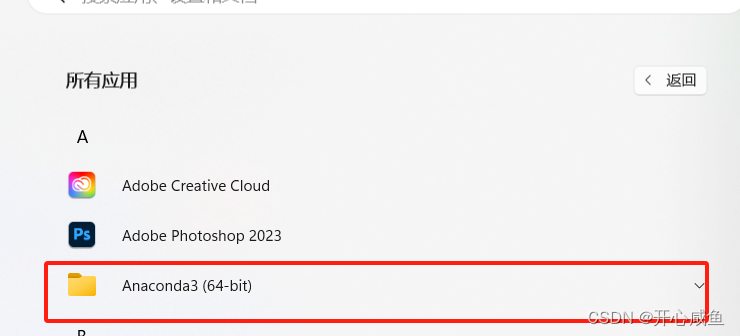
安装成功之后;点击所有应用=》ancaconda3==>
应该包含Anaconda Promt、Anaconda Navigator、Spyder




第二、可以不用配置环境变量
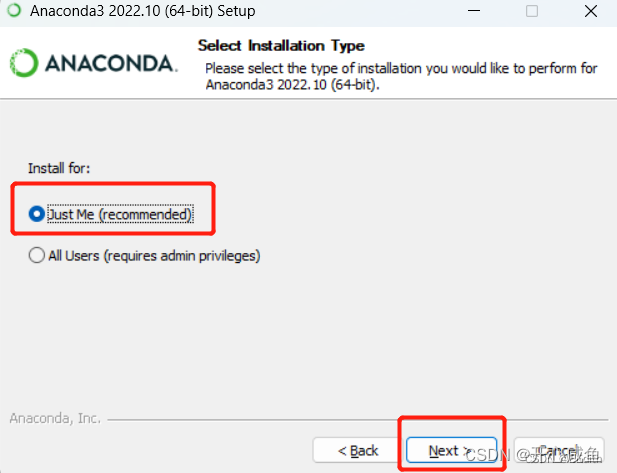
第三、选择Just Me
随便搜的链接:感谢博主分享https://blog.csdn.net/m0_61607990/article/details/129531686
Anconda的简单使用
最重要的学会使用导航(功能类似应用商店)去下载自己想要的依赖和编辑器
第一使用导航(Anaconda Navigator)在首页下载编辑器

第二在环境下载依赖的包
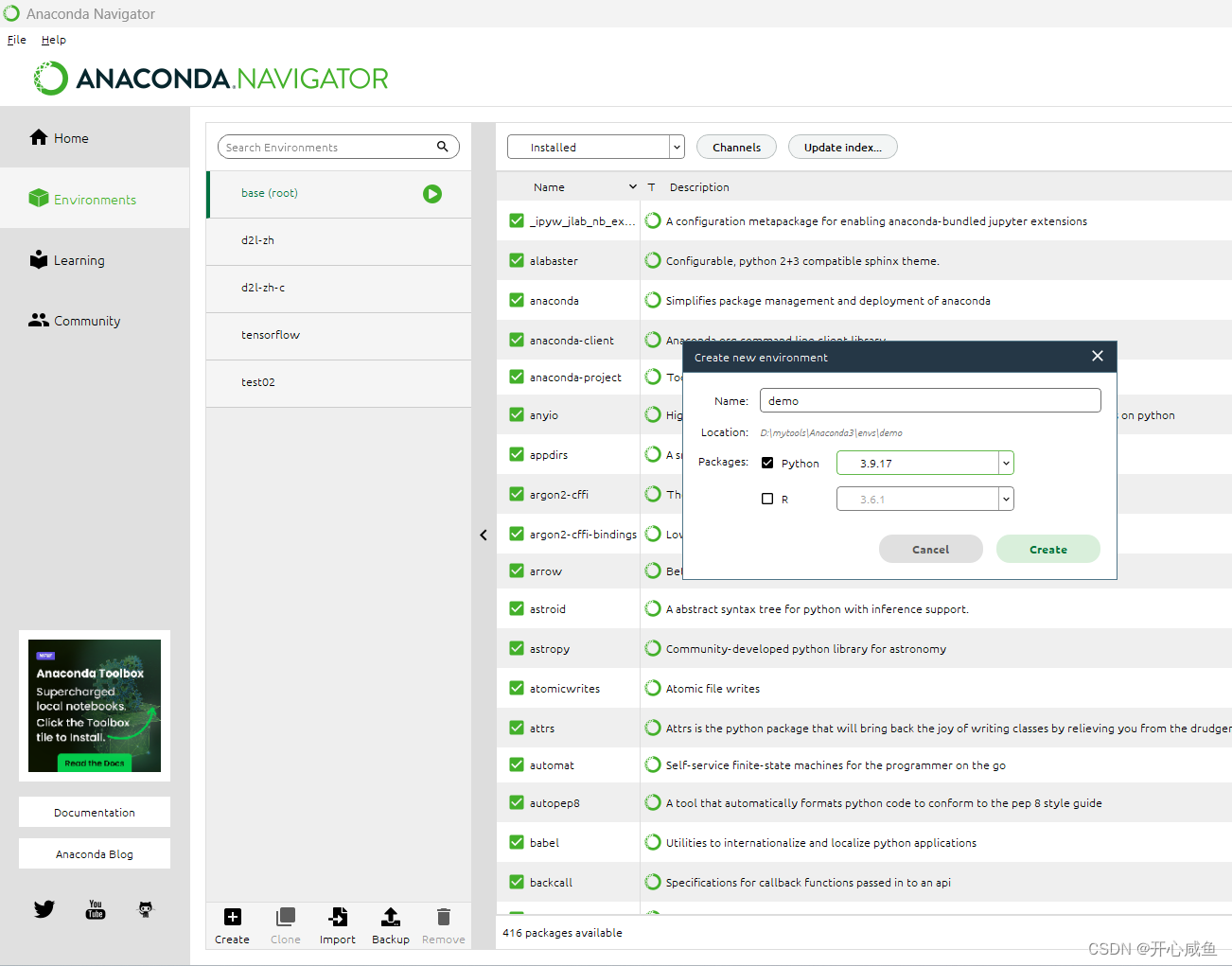
1.创建虚拟环境(可以自己查询一下Anconda虚拟环境默认保存位置更换,更换到D盘感觉比较好)
2.下载模块
3.增加渠道(Channels按钮)这个渠道多了可以下载的模块就多了(个人理解)
Anconda prompt使用
命令行输入的地方,自己探索
查看安装的包
conda list
查看Anconda版本
conda -V
创建虚拟环境
conda create --name xxx python=3.8
查看所有虚拟环境(直接看网址)
https://blog.csdn.net/qq_49141095/article/details/130276262
二、理论学习
1、吴恩达
去哪儿学
【[双语字幕]吴恩达深度学习deeplearning.ai】
https://www.bilibili.com/video/BV1FT4y1E74V/?share_source=copy_web&vd_source=7e38fcd1291f26d62ce3ba45bbb935ab
课后作业总结:
https://zhuanlan.zhihu.com/p/95510114
学哪些
L1、L2、L4课程
怎么学
看一个阶段写一个阶段的练习
2、李沐
重要
整理文档 该网址里有很多环境安装过程
https://blog.csdn.net/shaqilaixi2/article/details/128491193
去哪儿看
【00 预告【动手学深度学习v2】】 https://www.bilibili.com/video/BV1if4y147hS/?share_source=copy_web&vd_source=7e38fcd1291f26d62ce3ba45bbb935ab
课程主页: https://courses.d2l.ai/zh-v2
教材: https://zh-v2.d2l.ai/
课程论坛讨论: https://discuss.d2l.ai/c/16
Pytorch论坛: https://discuss.pytorch.org/
代码:https://github.com/d2l-ai/d2l-zh-pytorch-slides
三、实战(B导yyds,我就是搬运工)
这一步就是下载代码,使用代码,有两个点需要注意
1.B导的Json转换png的代码会报错 我会再后面填修改的代码(忘记是哪一位博主提供的)
2.环境搭配都是命令行的,我自己总结步骤(新手友好可行在后续步骤里)
1、参考博文
https://blog.csdn.net/weixin_44791964/article/details/108866828
配套视频
【Pytorch 搭建自己的Unet语义分割平台(Bubbliiiing 深度学习 教程)】
https://www.bilibili.com/video/BV1rz4y117rR/?share_source=copy_web
四、pytorch-unet虚拟环境搭建
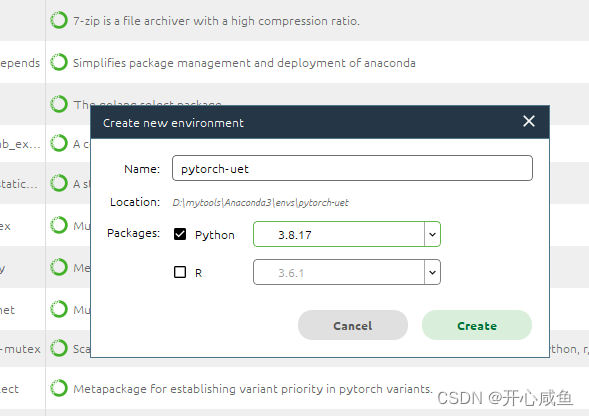
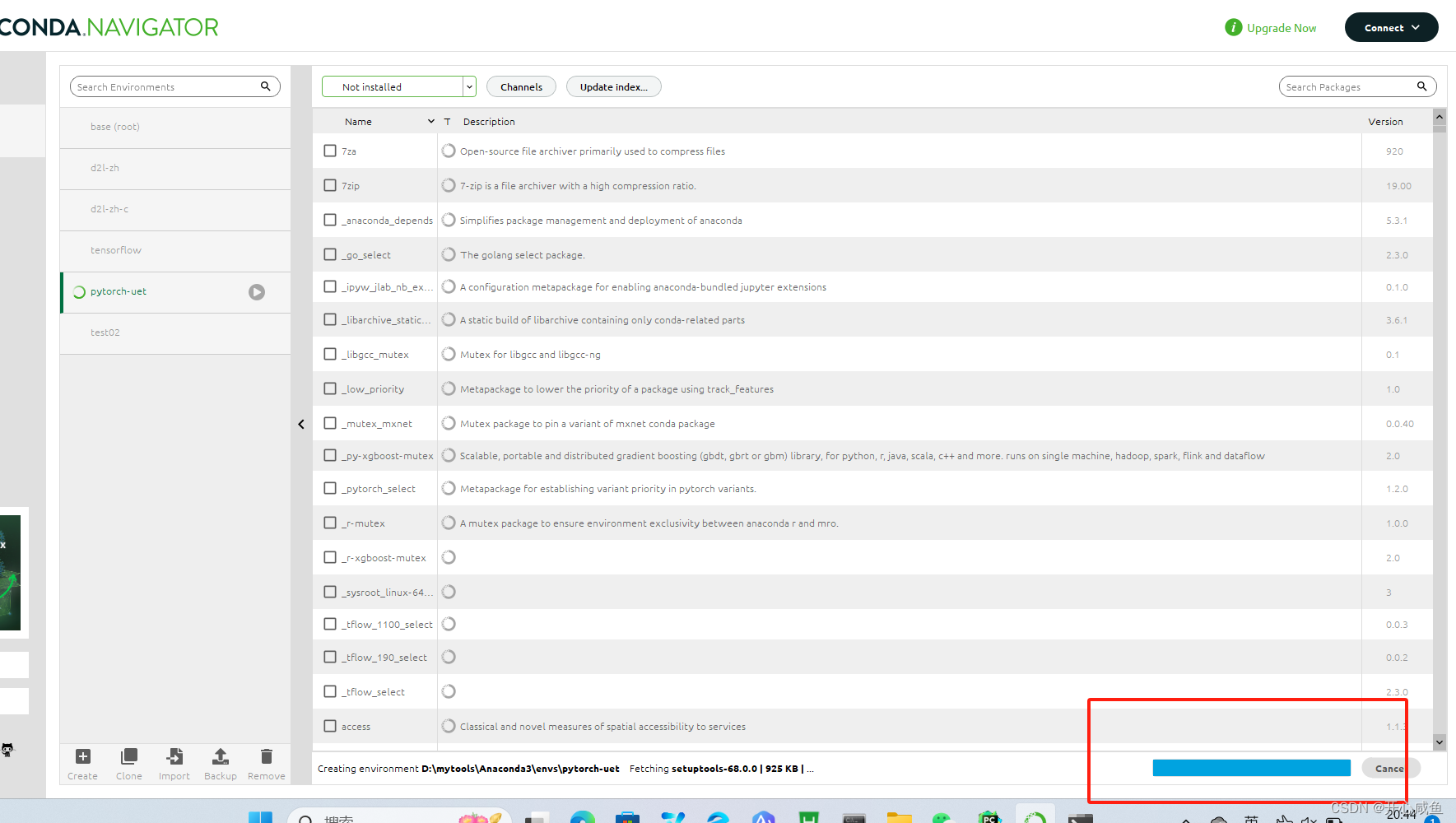
打开Anconda 导航==》首页==》左下角创建虚拟环境==》弹框写环境名字pytorch-uet 选择python版本3.8.17==》点击创建==》等很长一段时间一直等到创建好为止
2.开始安装依赖
scipy
numpy
matplotlib
opencv_python
torch
torchvision
tqdm
Pillow
h5py
tensorboard
3安装torch
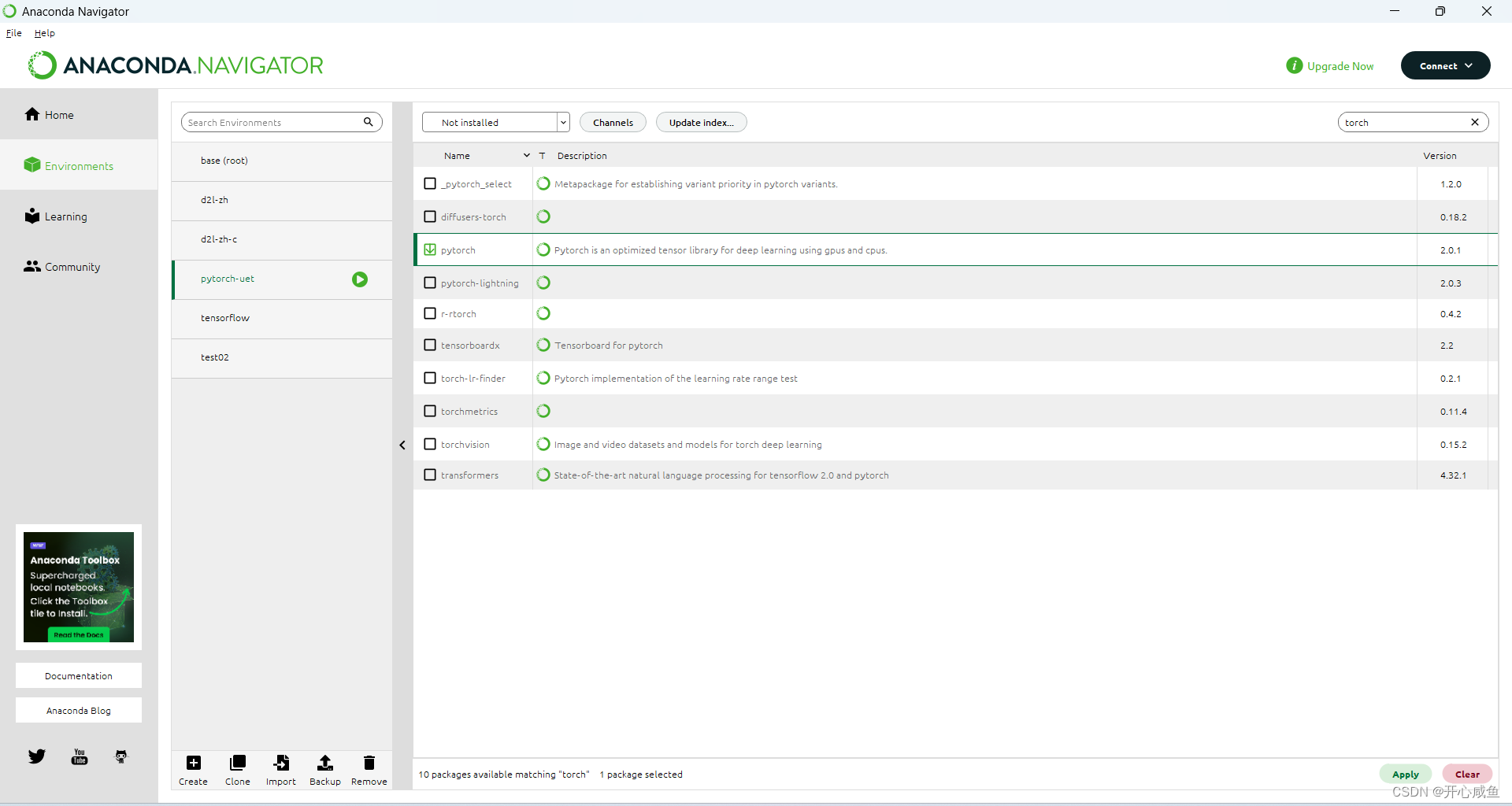
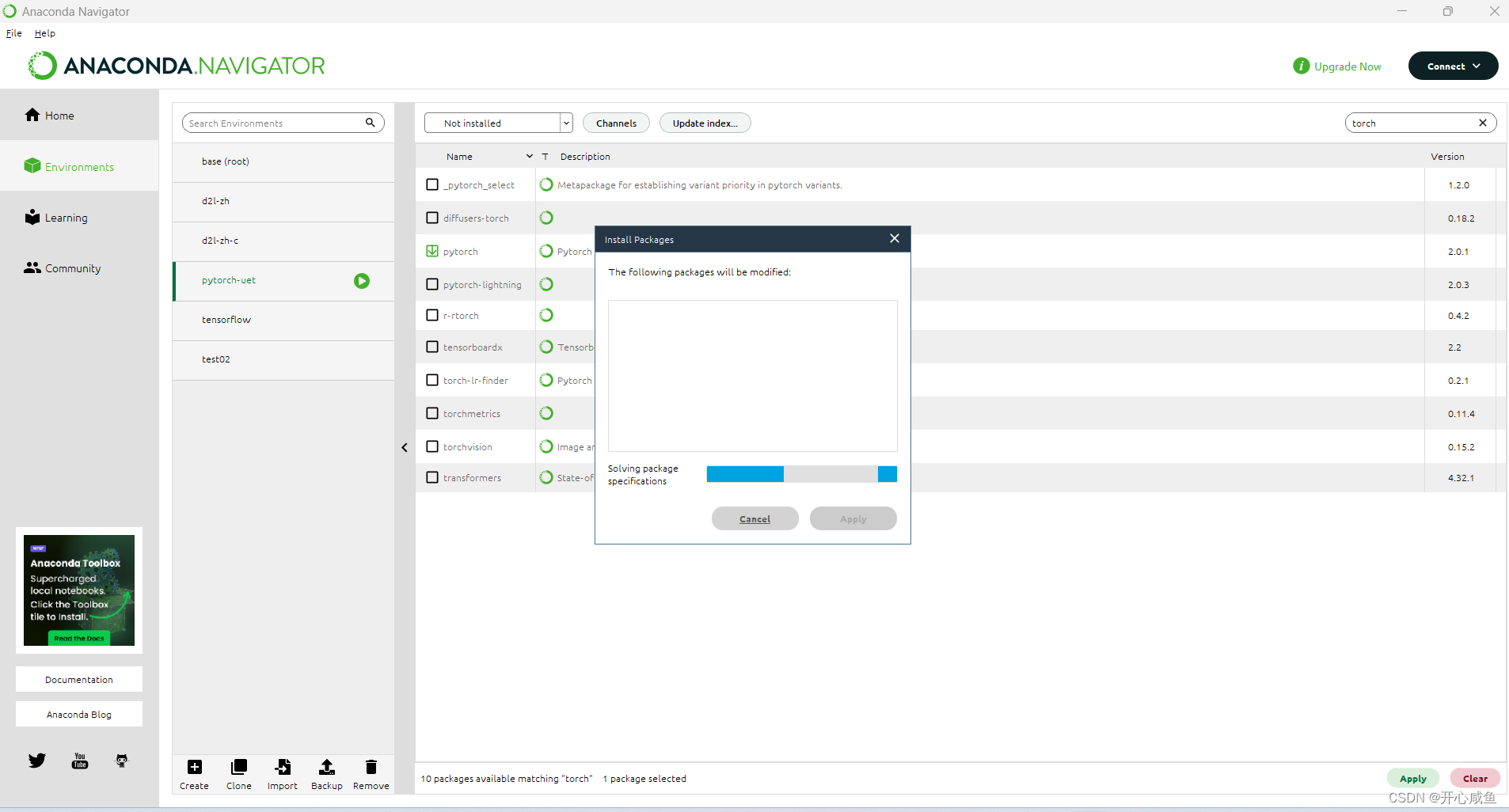
Anaconda 导航==》选择虚拟环境 pytorch-uet(名字可以自己起)==》选择not installed >右上角输入torch 》搜索》点击下载pytorch 右下角点击apply >等待》弹框点击apply》 ==>又是漫长的等待
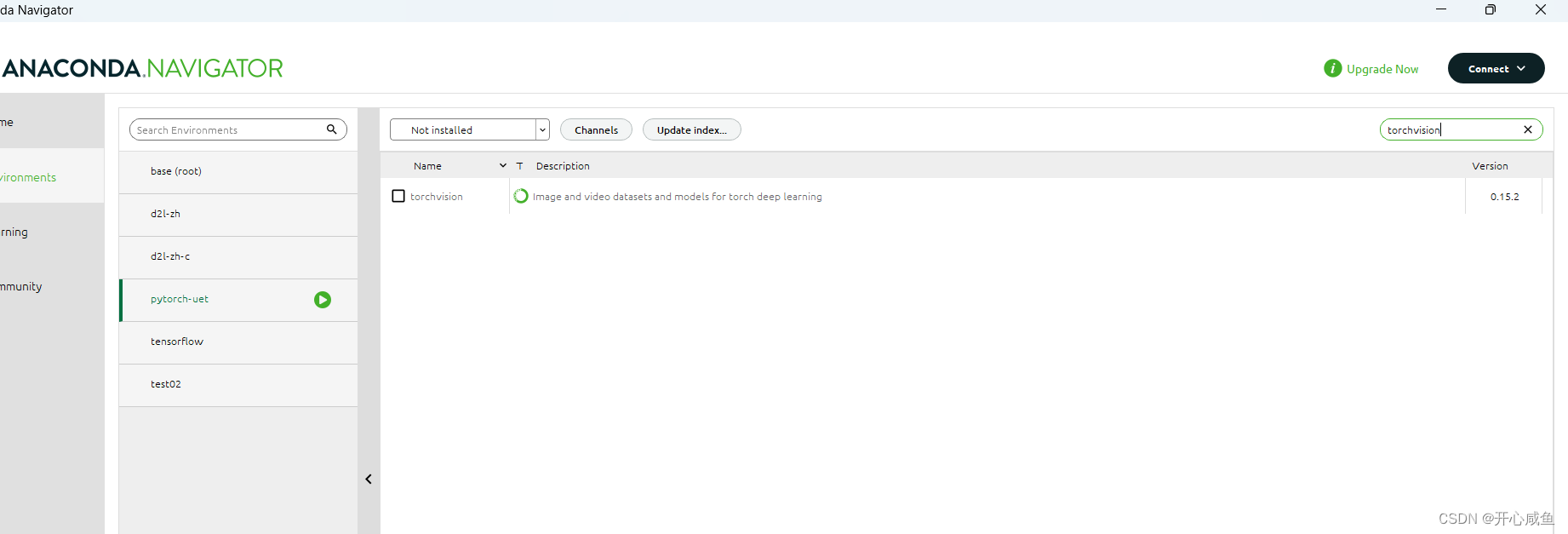
4下载torchvision
选择not installed >右上角输入torch 》搜索torchvision》点击下载torchvision 右下角点击apply >等待》弹框点击apply》 ==>又是漫长的等待
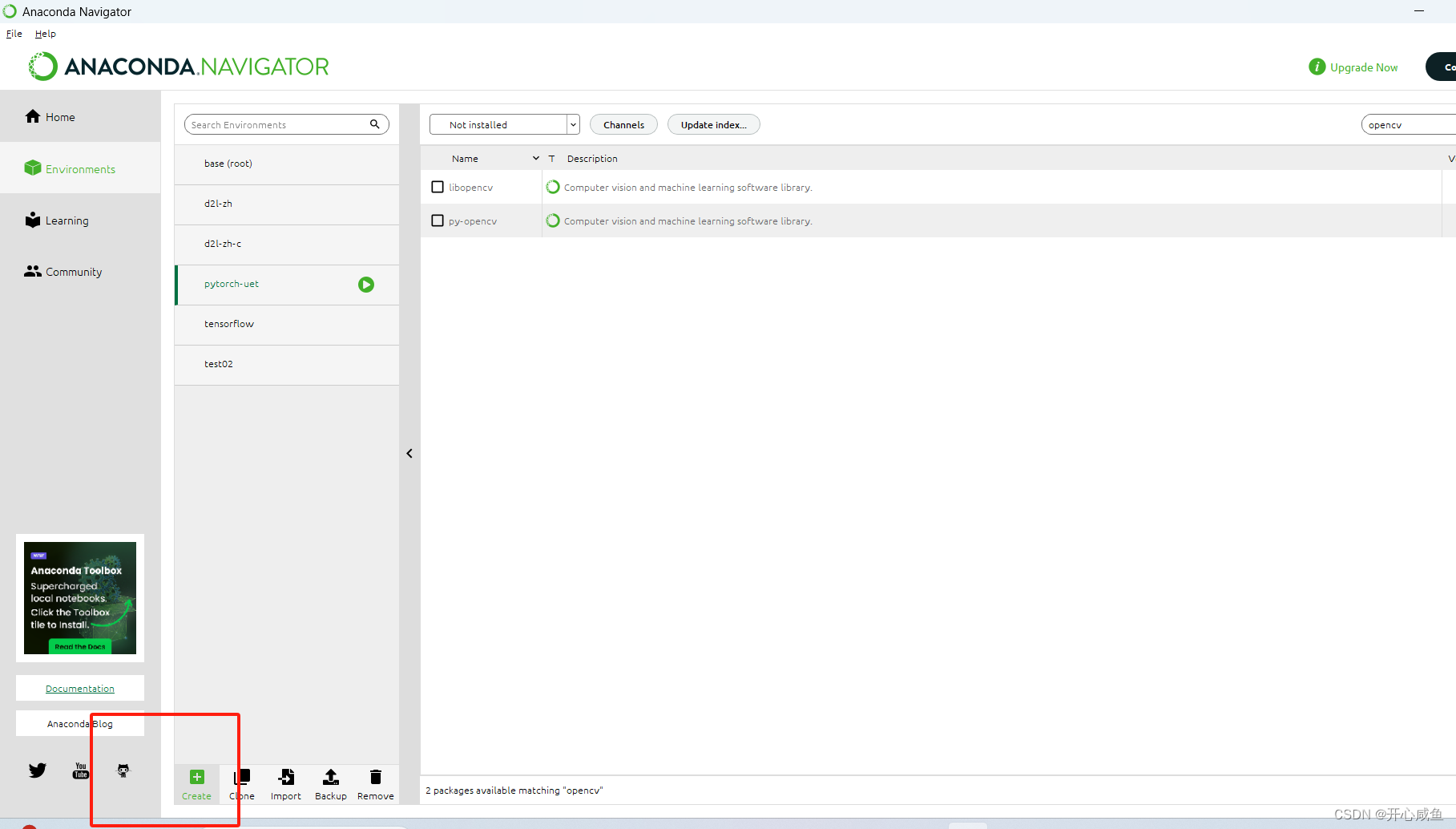
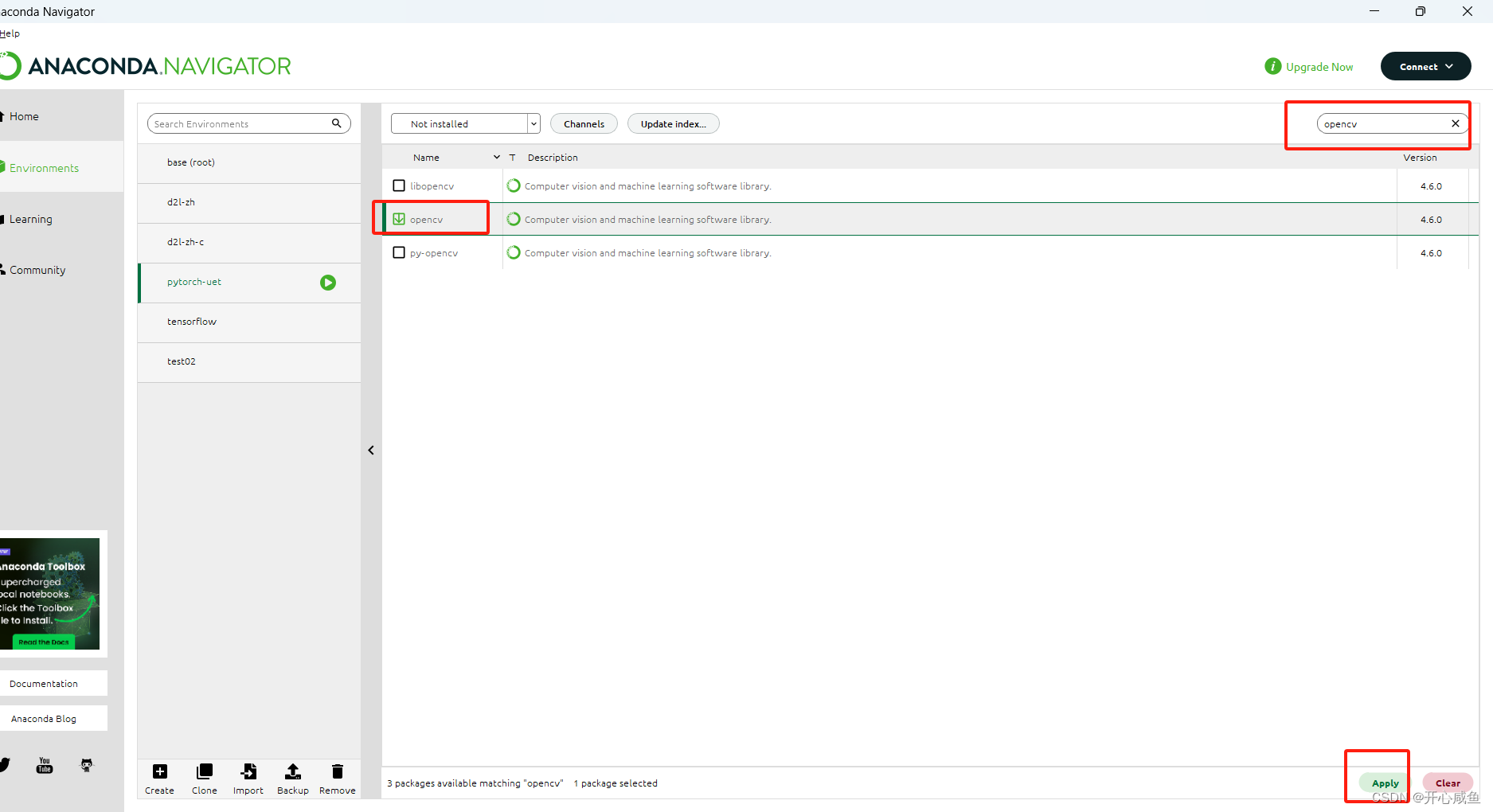
5下载opencv
选择not installed >右上角输入torch 》搜索opencv》点击下载py-opencv 右下角点击apply >等待》弹框点击apply》 ==>又是漫长的等待
6下载pillow
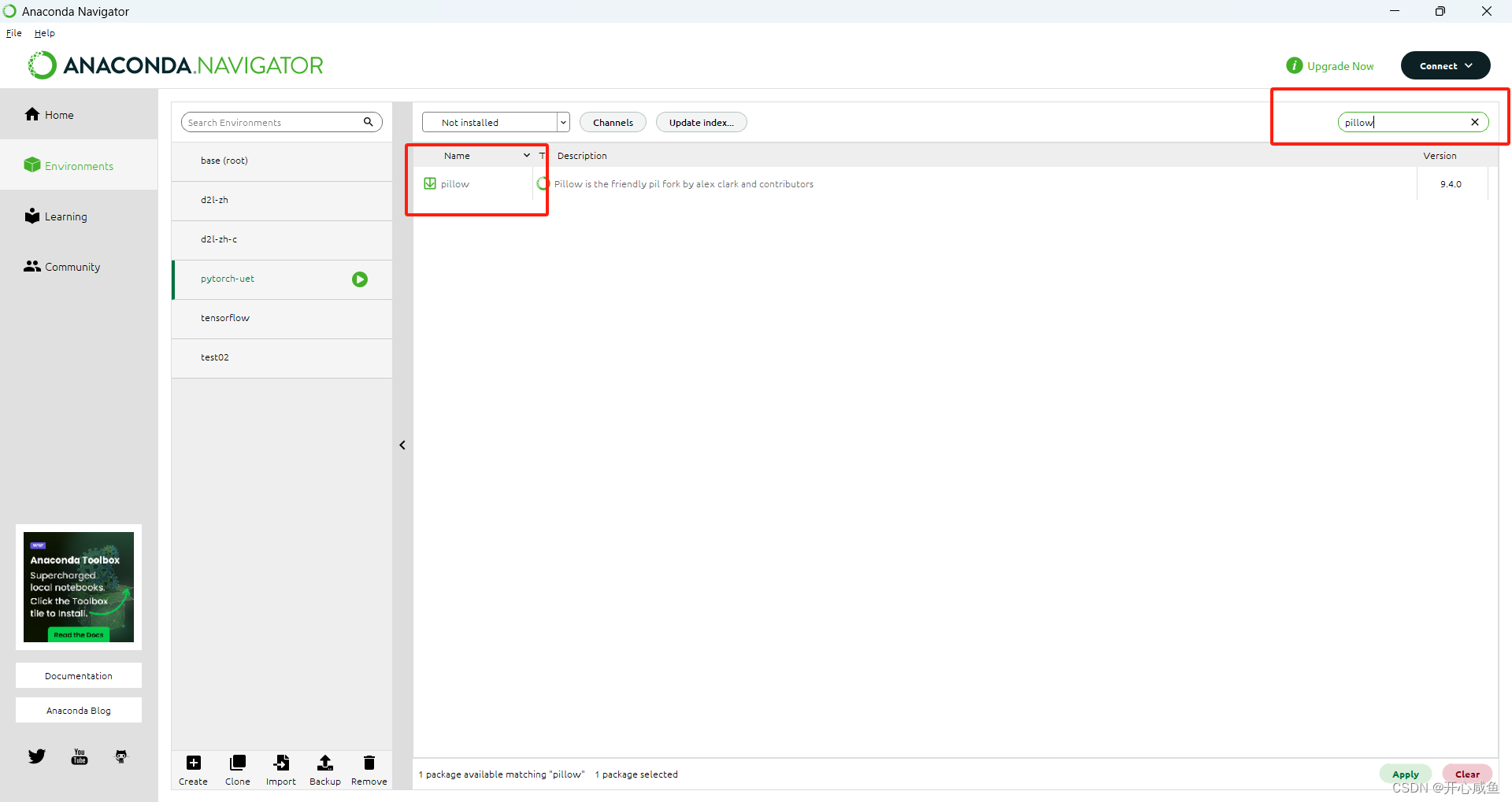
7下载matplotlib
8下载scipy
9下载h5py
10下载tensorboard
11下载tqdm
12安装labelme
需要先添加渠道
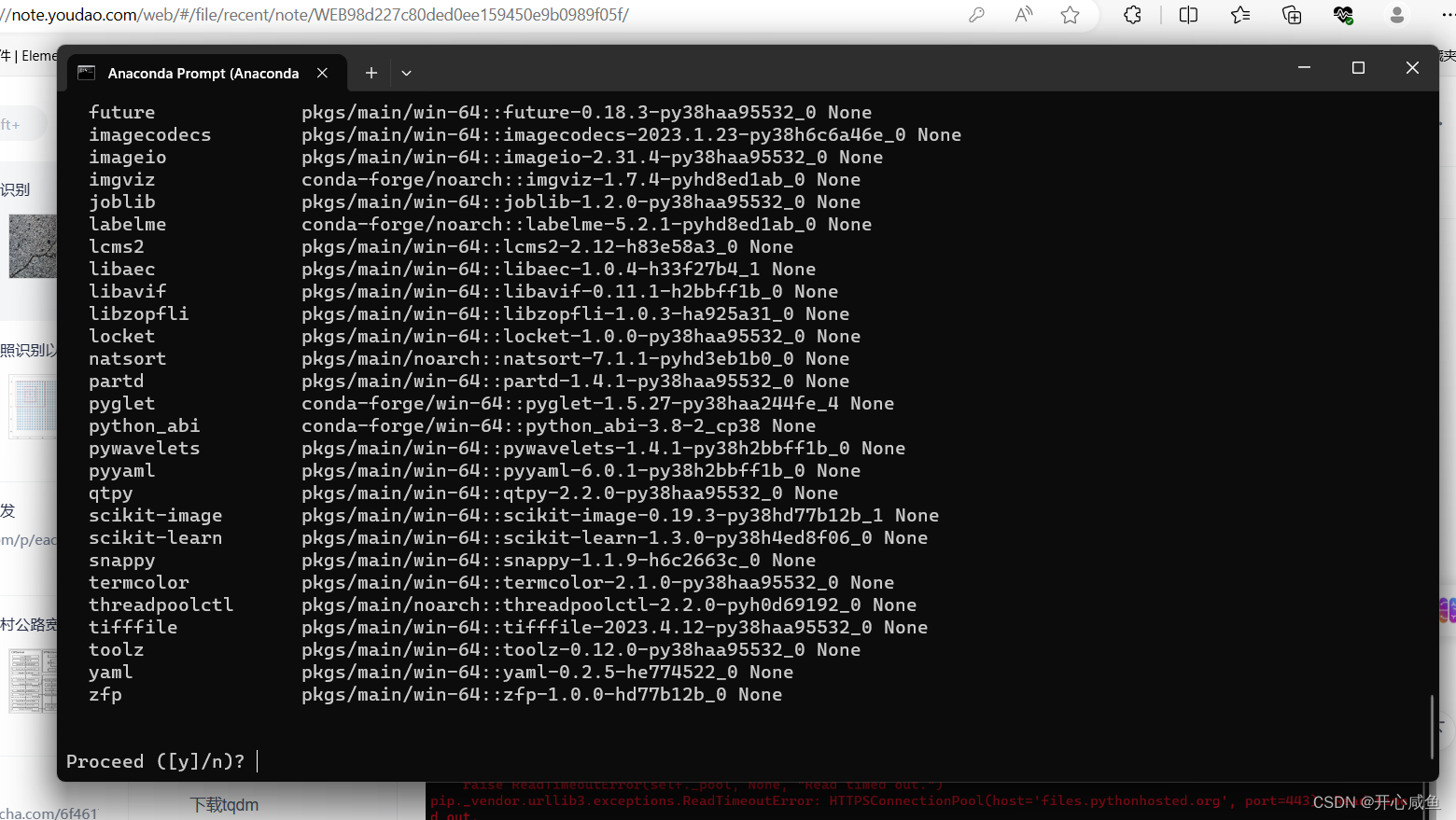
1.打开Anconada Prompt==>激活pytorch-uet 环境 输入命令行 conda activate pytorch-uet 激活=》
输入命令行
conda config --append channels conda-forge
然后再输入命令行
conda install labelme
出现 y/n=>输入y
13使用labelme
每次使用labelme都需要通过命令行进入
1.打开Anconada prompt
2.激活 pytorch-uet环境 conda activate pytorch-uet
3.输入labelme
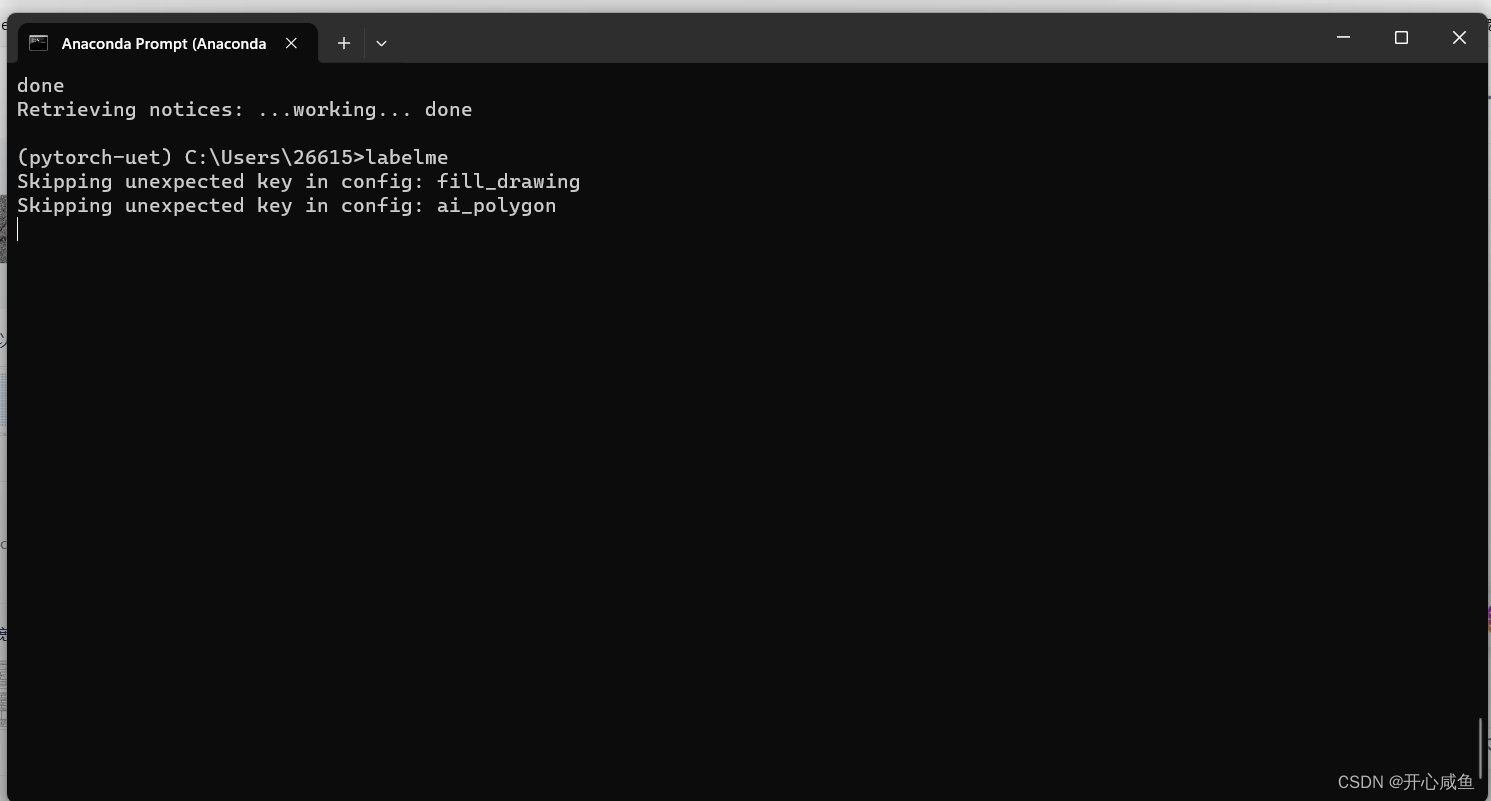
点击打开目录进入数据集开始标注
点击file设置自动保存
绘制多边形
快捷键 A上一张图片 D下一张图片
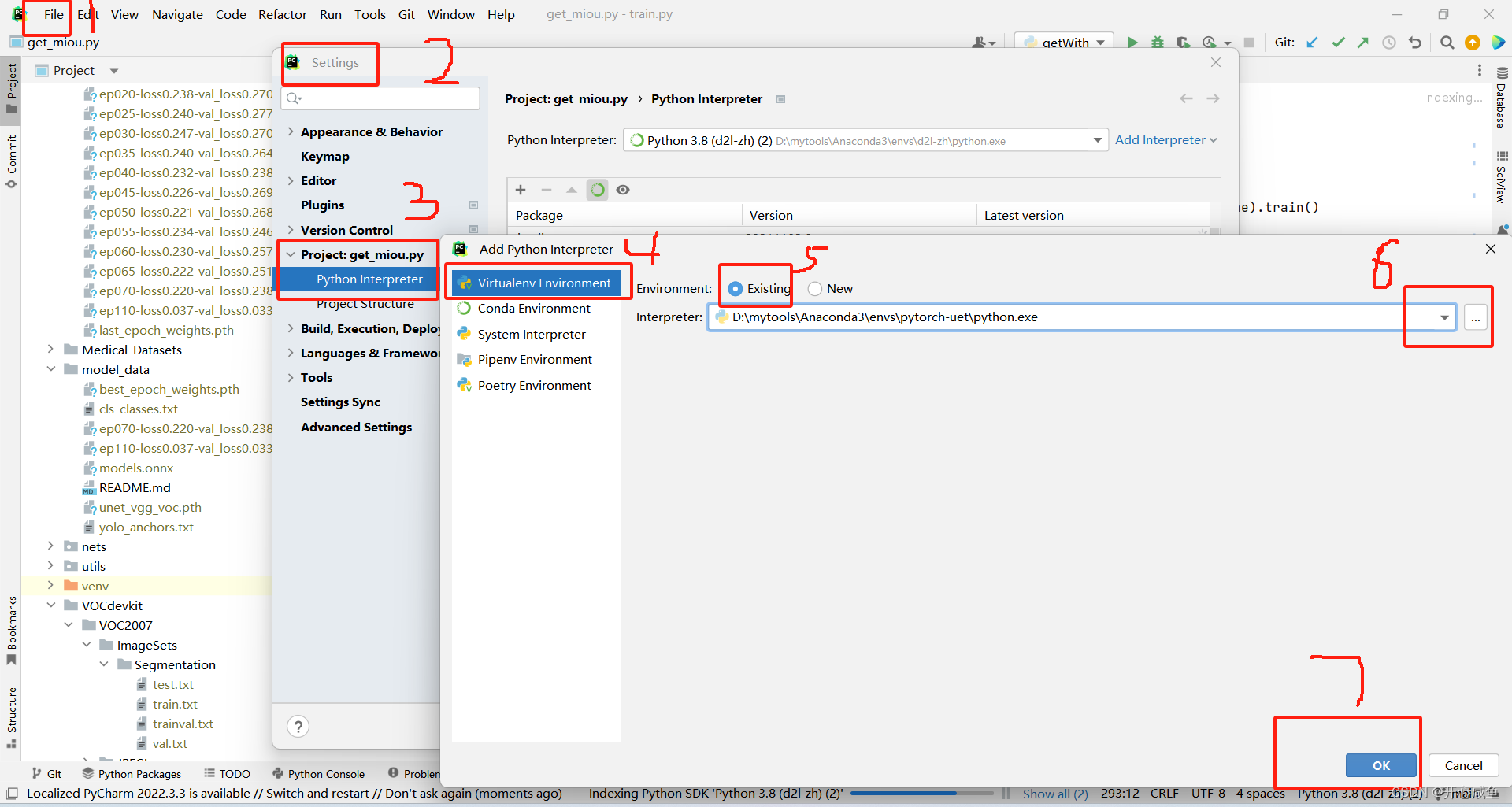
五、pyCharm 项目绑定虚拟环境
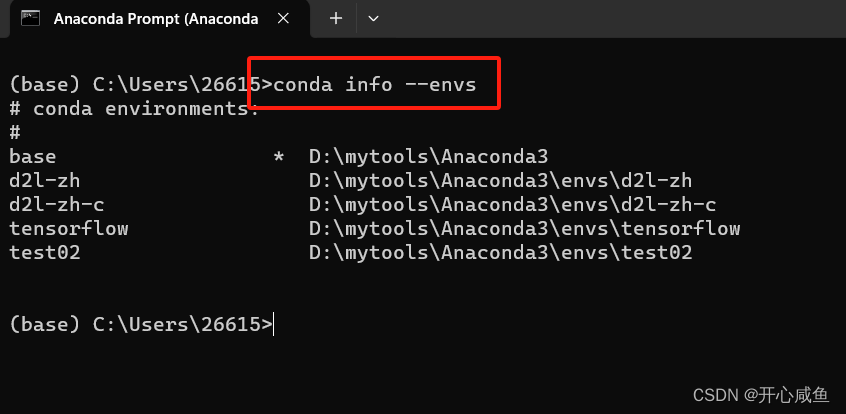
使用命令行看 或者在anconda 导航里的虚拟环境左下角有标明路径
2、
六、json_to_dataset.py
# CreatTime: 2023/8/11
# FileName:newdatatojson
# Descriptiot:解释
import argparse
import base64
import json
import os
import os.path as osp
import cv2
import imgviz
import PIL.Image
import numpy
from labelme.logger import logger
from labelme import utils
def main():
logger.warning(
"This script is aimed to demonstrate how to convert the "
"JSON file to a single image dataset."
)
logger.warning(
"It won't handle multiple JSON files to generate a "
"real-use dataset."
)
# json_file是标注完之后生成的json文件的目录。out_dir是输出目录,即数据处理完之后文件保存的路径
json_file = r"./datasets/before/"
out_dir1 = r"./datasets/SegmentationClass"
out_dir2 = r"./datasets/JPEGImages"
# 如果输出的路径不存在,则自动创建这个路径
# if not osp.exists(out_dir1):
# os.mkdir(out_dir1)
# 将类别名称转换成数值,以便于计算
label_name_to_value = {
"_background_": 0,
"road": 1,
}
for file_name in os.listdir(json_file):
# 遍历json_file里面所有的文件,并判断这个文件是不是以.json结尾
if file_name.endswith(".json"):
path = os.path.join(json_file, file_name)
if os.path.isfile(path):
data = json.load(open(path))
# 获取json里面的图片数据,也就是二进制数据
imageData = data.get("imageData")
# 如果通过data.get获取到的数据为空,就重新读取图片数据
if not imageData:
imagePath = os.path.join(json_file, data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
# 将二进制数据转变成numpy格式的数据
img = utils.img_b64_to_arr(imageData)
for shape in sorted(data["shapes"], key=lambda x: x["label"]):
label_name = shape["label"]
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
lbl, _ = utils.shapes_to_label(img.shape, data["shapes"], label_name_to_value)
# print(lbl)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = imgviz.label2rgb(
label=lbl, image=imgviz.asgray(img), label_names=label_names, loc="rb"
)
# out_dir = osp.basename(file_name).replace('.', '_')
# out_dir = osp.join(out_dir1, out_dir)
# if not osp.exists(out_dir):
# os.mkdir(out_dir)
# print(out_dir)
# 将输出结果保存,
# PIL.Image.fromarray(img).save(osp.join(out_dir1, "%s_img.jpg" % file_name.split(".")[0]))
utils.lblsave(osp.join(out_dir1, "%s.png" % file_name.split(".")[0]), lbl)
# PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir1, "%s_label_viz.png"%file_name.split(".")[0]))
# with open(osp.join(out_dir, "label_names.txt"), "w") as f:
# for lbl_name in label_names:
# f.write(lbl_name + "\n")
logger.info("Saved to: {}".format(out_dir1))
else:
path = os.path.join(json_file, file_name)
path2 = os.path.join(out_dir2, file_name)
img = cv2.imread(path)
cv2.imwrite(path2[0:-4]+'.jpg', img)
print("label:", label_name_to_value)
if __name__ == "__main__":
main()















 822
822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









