









Contrastive Learning for Sequential Recommendation
1 Intro
- 序列推荐很有用,但是很容易受限于数据稀疏
- 自监督学习很有用,但是不试用于推荐:缺乏大量原料i库 & 自监督序列预测任务基本就是序列推荐目标
2 主要框架
主要框架分为3块:
- 数据增广模块:同一个数据产生两份增广样本< s u a i , s u a j s^{a_i}_u, s^{a_j}_u suai,suaj>,彼此视为正样本;不同数据产生的视为负样本 s − s^- s−
- 用户表示:适用所有用户序列建模方法
- 对比学习辅助函数:使用对比损失函数来区分两个表示是否来自相同的用户历史序列
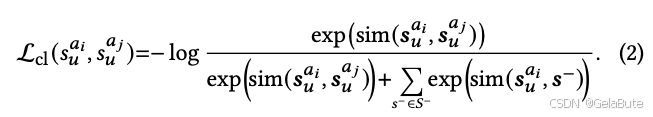
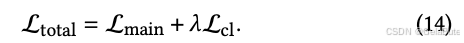
2.1 数据增广方法
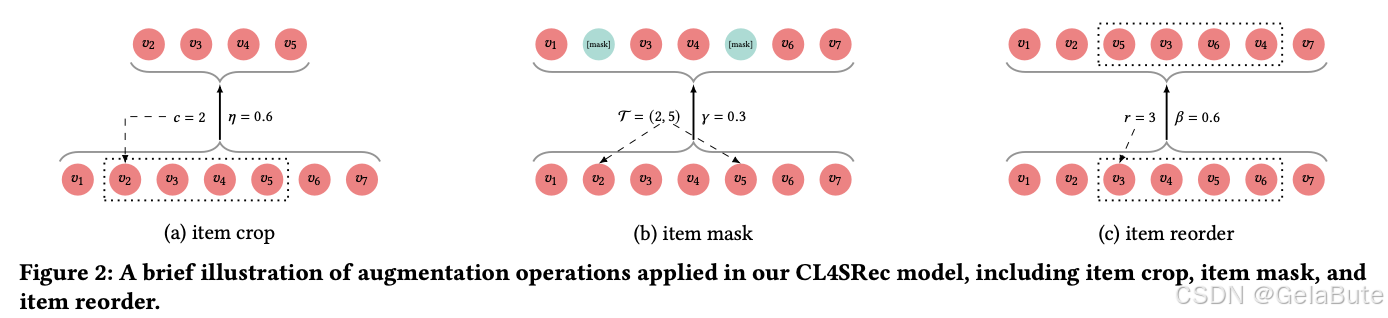
- crop:以 η \eta η概率保留某连续子序列( η = 1 \eta=1 η=1即原序列,=0序列为空)
- mask:以 γ \gamma γ概率mask掉随机item
- reorder:以 β \beta β概率shuffle某段连续子序列
2.2 用户表示
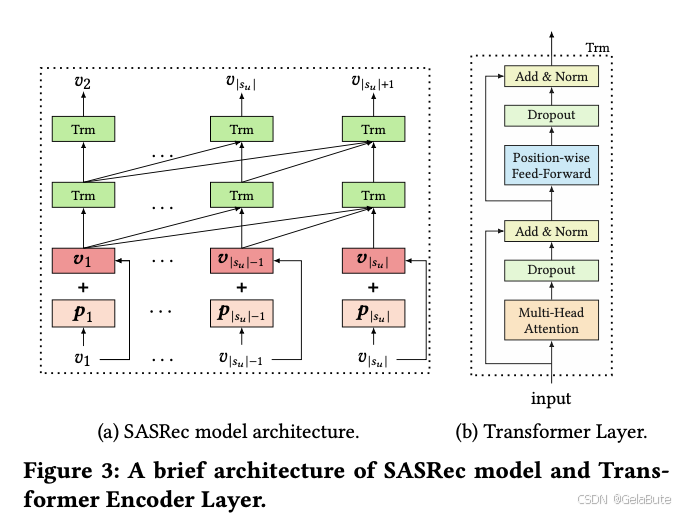
item和位置编码
p
i
p_i
pi结合后,输入Trm block。Trm block由Multi-Head Attention (MH)和Position-wise Feed-Forward (PFFN) 组成
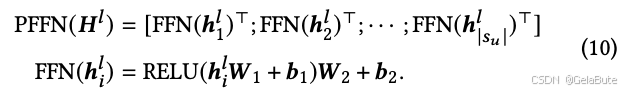
不断堆叠Trm block
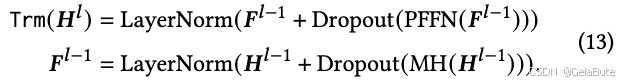
最终
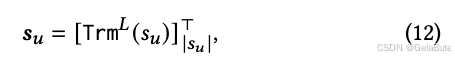
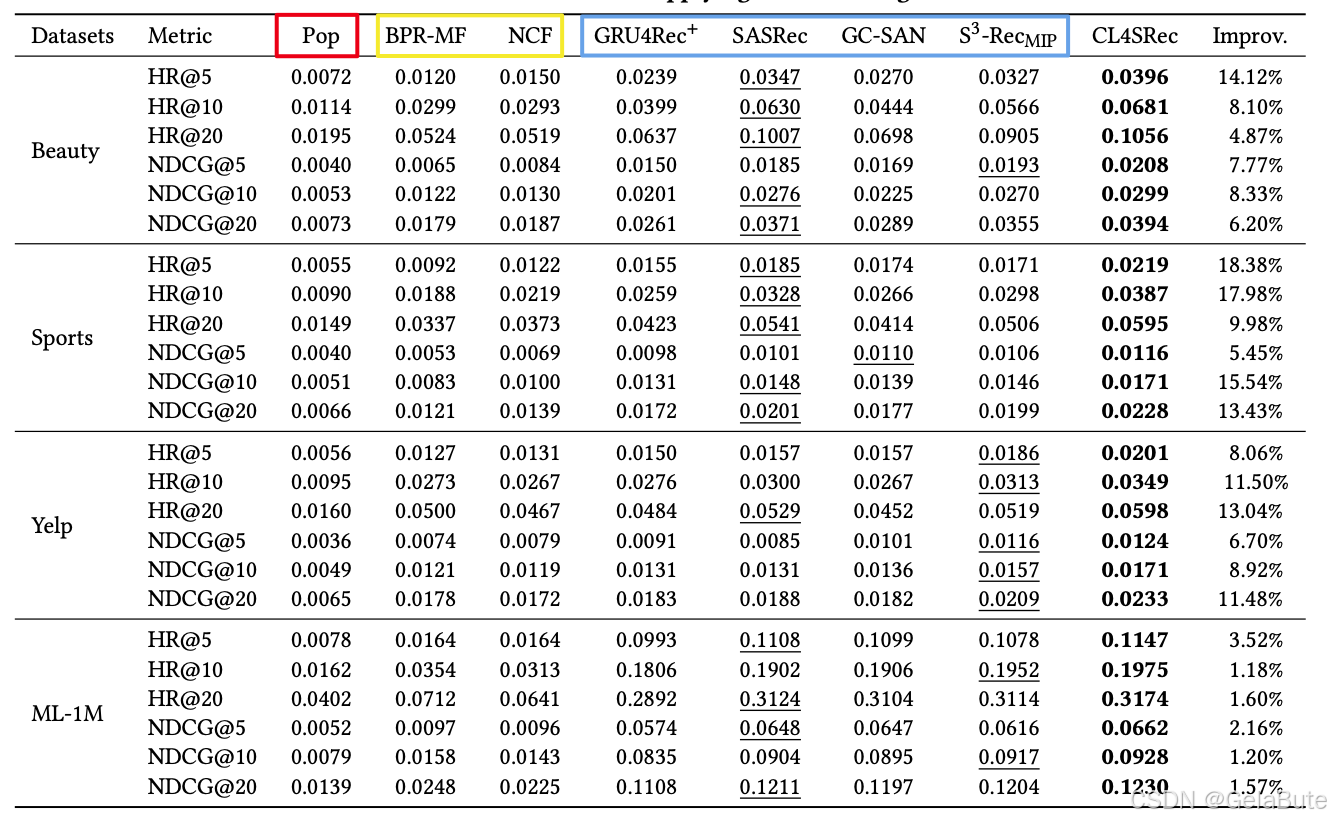
3 Expr
- 非个性化(红)是最差的;序列建模(蓝)比非序列建模(黄)更好;ATTN在序列建模中最有效;CL4SRec最优
- 数据增广方法各有各的好,没有全优的 (每次只取一种增广方法实验)
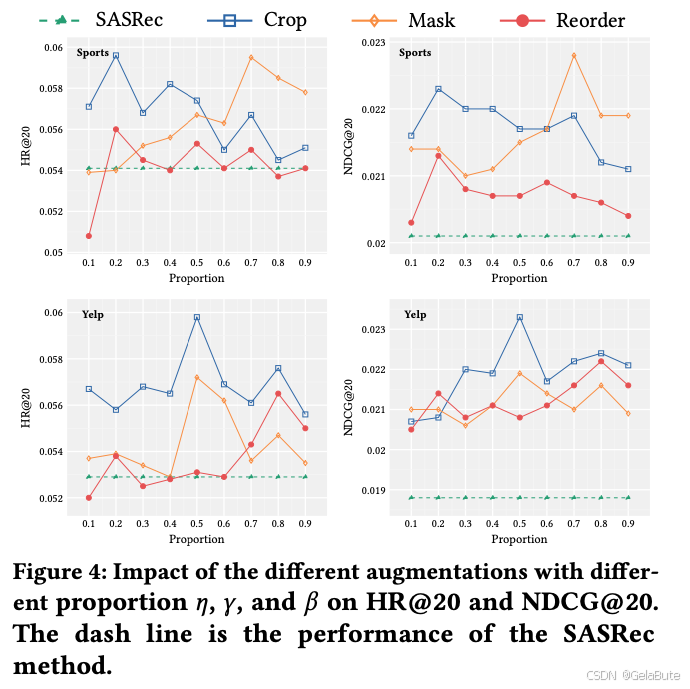
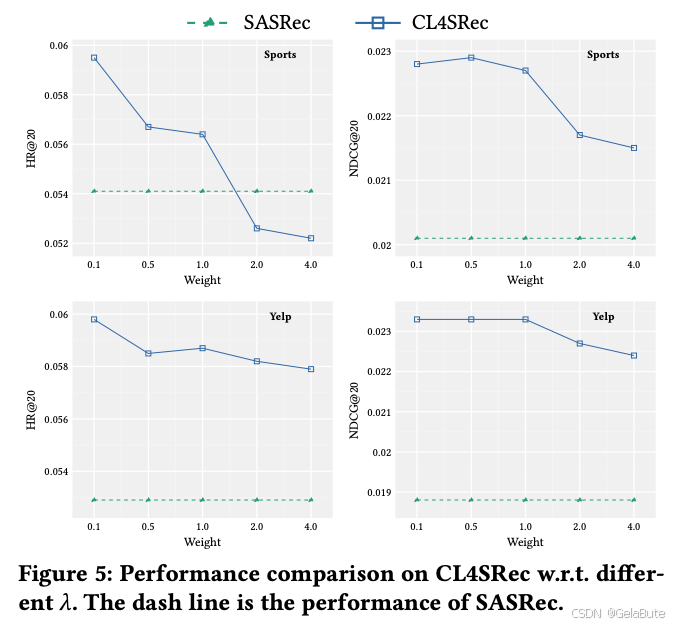
- 最终loss中
λ
\lambda
λ超过一定阈值后再增加就会导致模型效果下降
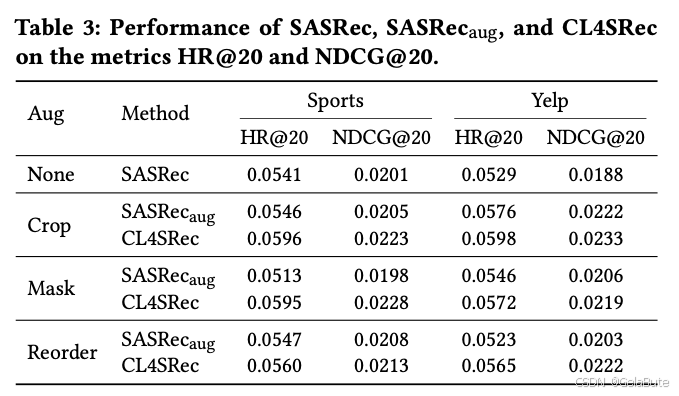
- 消融数据增广方法和对比学习loss,都有增益(
S
A
S
R
e
c
a
u
g
SASRec_{aug}
SASRecaug = SASRec + 增广方法,CL4SRec =
S
A
S
R
e
c
a
u
g
SASRec_{aug}
SASRecaug + 对比学习loss)
- 基于数据集中为好友的用户对,检查其表示vec是否相似。SASRec和CL4SRec平均相似度分别是0.5198和0.6100,CL4Rec相比SASRec产生了更好的用户向量表示

















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









