







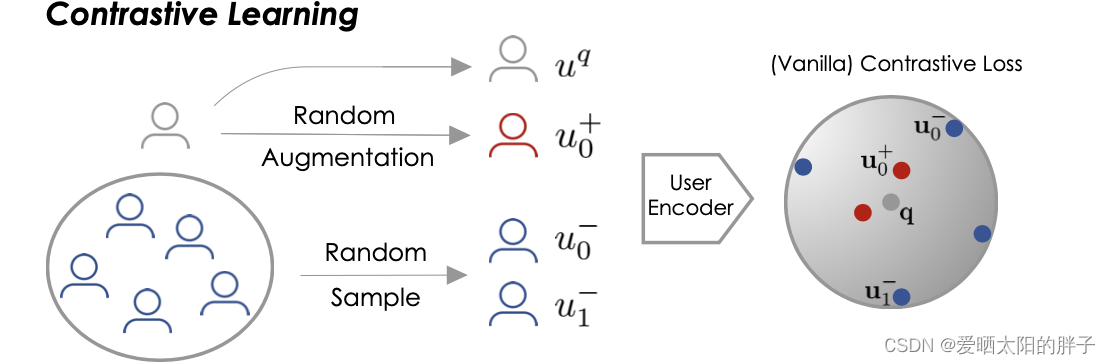
对比学习优势:可以学习到对低级噪声(图像的平移旋转)具有鲁棒性的高级特征。
数据增强:数据增强通过生成每个训练实例的许多变体来人为地增加训练集的大小。这减少了过 拟合,使之成为一种正则化技术
引言:
读完本文你将知道传统对比学习存在的问题,并学会一种解决方式。为了更好得阅读本文,请确保已经对对比学习有了一些了解,如若不然,建议先看一下一文弄懂什么是对比学习。本文是自己的总结,如有问题欢迎批评指正。
传统对比学习存在的问题:
由于忽略了用户行为中的噪声并对所有增强样本一视同仁,现有的对比学习框架不足以学习推荐中有区分度的用户表示 。
举例:
对用户行为序列S:猫1,狗2,猫3,猫4(为了便于理解,可假设这是用户浏览过的图片)进行编码的到用户兴趣, 其中狗2为假阳性(想看猫但手滑点错了,并不喜欢狗。举例而已。。。小狗很可爱,本人很喜欢狗)。假设数据增强采用随机丢弃,得到两个新序列:S1:猫1、猫3、猫4 ,S2:猫1、狗2、猫3。编码得到用户兴趣
,
,不难想到S2应该更能反应用户兴趣(假阳性数据被丢弃,剩下的数据都是ture-positive)。1、若使用传统对比学习,同等程度的对待两个增强数据(S1,S2),模型会同等程序地增大(
,
)相似度(
,
)的相似度,即在特征空间中同等程度拉近与锚点q的距离。现在我们来想一下,它们能同等程度被对待嘛?S1:猫1,猫3,猫4 (只喜欢猫),S2:猫1、狗2、猫(即喜欢猫又喜欢狗)。若用对比学习得到的编码器对数据进行编码,那编码结果,对这两类人的区分对是不是非常小(存在过平滑问题。)
假阳性:用户与商品进行交互了但并不喜欢。
举例:买了一个一本书,但可能会给差评。若直接把与用户交互过的物品,当做正样本,则会引入假阳性误差。
解决方法(CCL4Rec):
我们设计了困难感知的数据增强,追踪查询的用户 被替换行为的重要性和替换的相关性(原行为和替换行为),从而确定增强的正/负样本的质量。下面为对应原文:
In this paper, we propose to model the nuances between positives/negatives using contrast over the traditional con-trastive learning. Also, the proposed controllable augmentation strategy constructs negatives with the desired hardness/quality from the query sample, which empirically leads to robust trainingand better performance
这句话是不是不好理解,让我们回到刚刚的例子。现在我们有训练数据 S:猫1,狗2,猫3,猫4,假设它们都是true-positive(不存在假阳性,注意这和之前不一样,上一个例子是为了说明传统对比学习可能造成的过平滑问题),我们使用困难感知增强(可以自己控制新数据和S的相关性),还是生成S1,S2。可能你会疑惑,这和之前的区别是啥?很简单,之前新数据是随机生成的,换句话说我们不知道它和原数据的相关性,现在知道了。那有啥用?? 那用处可就大了,知道相关性后,我们就可以控制,
与锚点
之间的距离了,因为S1和S更相似,训练模型的时候就可以让这俩点更接近点,
与
远点。如下图儿所示:
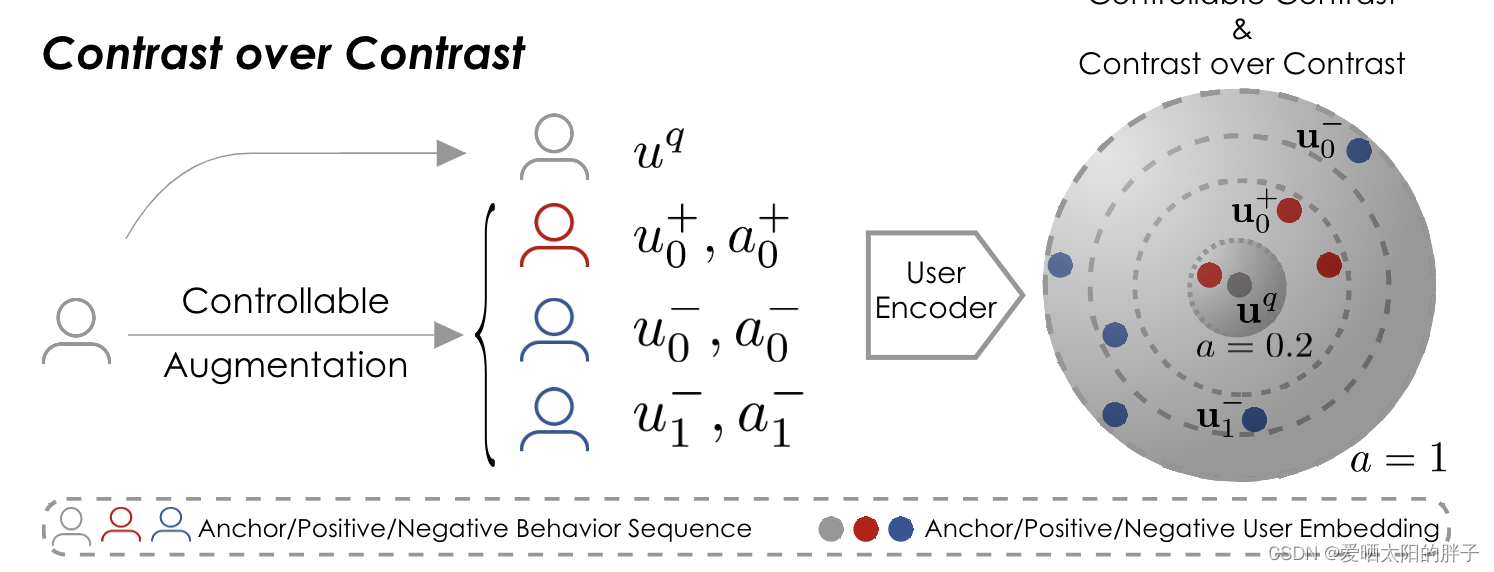
论文模型组成(三部分):
- Hardness-aware Augmentation。确定每个历史行为的重要性和每个替代者的相关性。通过联合考虑重要性和相关性,进行替代增强,并获得各种困难分数的正/负用户行为序列。我们可以明确选择特定困难范围的增强样本以及对比学习过程。
- Sequence Modeling。对历史行为序列以及扩增序列进行编码,得到特征向量。
- Contrast over Contrast。显性建模不通增强数据之间的差异。传统对比学习只学习(positive,query),(negative,query),论文中增加了(positve,positive),(negative,negative)。此外,论文中提出:基于增强样本的困难程度,在训练的早期阶段从简单对比中学习,并逐渐从较难的对比中学习,可以提高模型的健壮性。
模型实现
一、Behavior/Substitute Ranking
论文应用领域是短视频推荐。 表示用户的历史观看序列{
……
}(
表示序列长度),首先声明一下u代表用户,v代表一个短视频,U为用户的特征向量,V为一个视频的特征向量。Hardness-aware Augmentation阶段综合考虑行为在序列中的重要性,代带替换行为与序列中行为之间的相关度。接下来我们分别进行说明。
1、行为在序列中的重要性。论文中用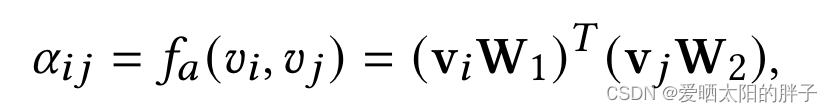 计算序列中两个行为的相关性。
计算序列中两个行为的相关性。,
是 两个可训练的矩阵,因为没有办法确切知道两个行为之间的相关程度,所以采用这种方式让模型自己去优化,经过训练,模型自己可以实现。论文对行为i与序列中所有行为j之间相关性求和作为行为i在序列中的重要程度(
)。
下面是原文对这一点的描述
Intuitively, when a micro-video is more relevant to other micro-videos watched by the user, it has a higher chance of being animportant one
2、替代品与序列相关程度评分。论文提出,所有不存在于用户u行为序列中的行为,都可以作为潜在替代品。(进行了随机采样)。行为t与替代品k之间的相关性计算公式为
![]()
,
与1中矩阵相同,对其进行复用可减少参数量。
一、Hardness-aware Augmentation(难度感知数据增强)
论文中采用的数据增强方式为行为替换(作者认为这种方式更可控)。 = (
\
)
,\ 是集合减法,所以
意思:用长度为
的序列
去替换用户原行为序列中的行为子序列
后的新序列,简单点说。
1.1 Constructing Negatives
读完上一部分,我们已经知道论文选用的数据增强方式是行为序列替换,现在我没将进一步了解负样本生成方式及负样本难度计算方式:
- 负样本生成方式:替换原序列中相对重要的行为!序列中行为i的重要性分数为
- 负样本难度。让我们看一下计算公式图三所示,看着是不是挺复杂的,让我们来一步步解读一下,这是两个数的乘法,其实就是 行为(i)在序列中的重要程度*要替换的行为(j)与原行为的相似度(j),。

图三:负样本难度
The intuition behind themultiplication of relative importance and relatedness scores for constructing negativesis that replacing an important item with a highly related substitute will make the augmented negative harder.
1.2 Constructing Positives
同理正样本生成方式:替换原序列中不重要的行为。并且正样本难度计算公式如下,
不重要程度* 与被替换物品的不相似程度不相关程度。
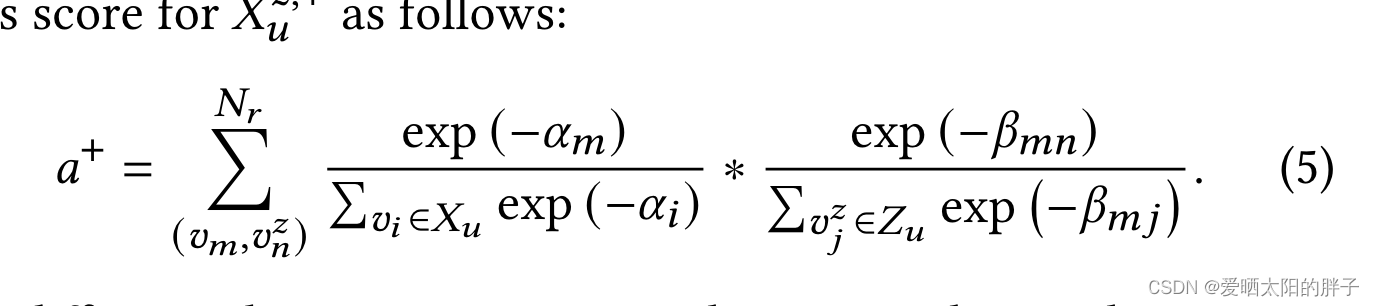
1.3 难度分数的使用
前文提到,为了解决过平滑问题应该有区分度得处理增强数据。论文采用的方式是:正样本分数大的拉近与锚点距离,负样本分数大的推远。(不用纠结,论文没有详细证明,给的解释是凭直觉直觉)
论文采用了三元组损失函数实现,对增强数据(query,positive,negative),(query,positive,positve),
(query,negative,negative)分别进行学习,通过样本难度分数,限制两两样本之间的最小距离,最终每个锚点都会形成如下的一个个同心圆,各增强数据离锚点距离,都会根据难度分数规则排列。

1、对(query,positive,negative)用三元组损失函数,确定,不同类型增强数据的位置。其中,
,
是超参数,分别用于调节范围去见,限制上下边界。
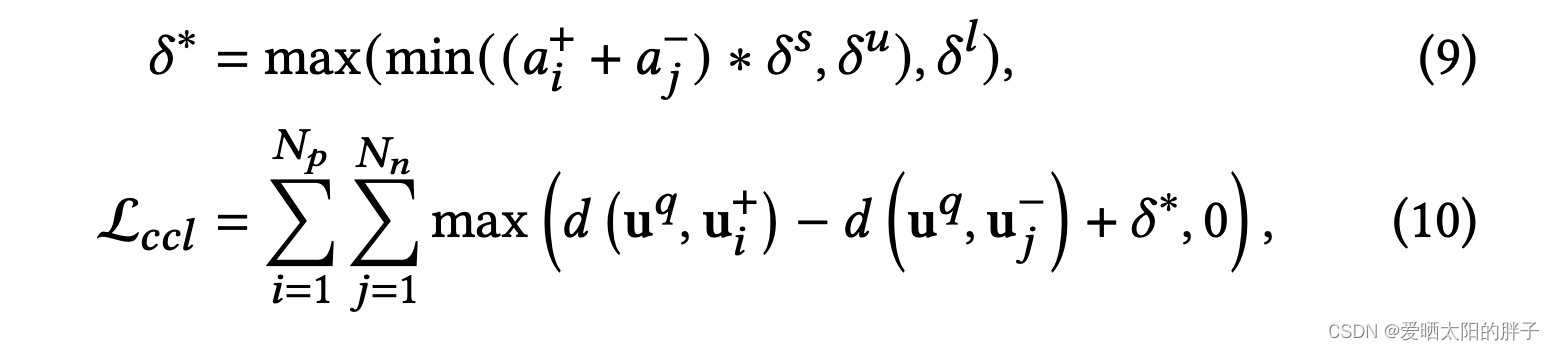
2、(query,positive,positve),(query,negative,negative),采用如下公式进行学习。
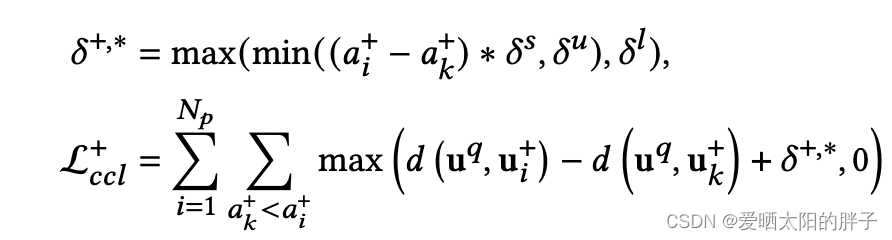

















 1872
1872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









