







在JS中使用正则表达式(2种方式)
构造正则表达式
使用 RegExp 构造函数可以定义正则表达式对象,具体语句格式如下:
new RegExp(pattern, attributes);
参数 pattern 是一个字符串,指定匹配模式或者正则表达式对象。参数 attributes 是一个可选的修饰性标志,包含 “g” “i” 和 “m” 三个选项,分别设置全局匹配、区分大小写的匹配和多行匹配;如果参数 pattern 是正则表达式对象,则必须省略该参数。
该函数返回一个新的 RegExp 对象,该对象包含指定的匹配模式和匹配标志。
示例1
下面示例使用 RegExp 构造函数定义了一个简单的正则表达式,匹配模式为字符“a”,没有设置第二个参数,所以这个正则表达式只能匹配字符串中第一个小写字母“a”,后面的字母“a”将无法被匹配到。
var r = new RegExp("a"); //构造最简单的正则表达式
var s = "JavaScript != JAVA"; //定义字符串直接量
var a = s.match(r); //调用正则表达式执行匹配操作,返回匹配的数组
console.log(a); //返回数组["a"]
console.log(a.index); //返回值为1,匹配的下标位置
示例2
var r = new RegExp("a", "gi"); //设置匹配模式为全局匹配,且不区分大小写
var s = "JavaScript != JAVA"; //字符串直接量
var a = s.match(r); //匹配查找
console.log(a); //返回数组["a", "a", "A", "A"]
示例3
在正则表达式中可以使用特殊字符。下面示例的正则表达式将匹配字符串“JavaScript JAVA”中每个单词的首字母。
var r = new RegExp("\\b\\w", "gi"); //构造正则表达式对象
var s = "JavaScript JAVA"; //字符串直接量
var a = s.match(r); //匹配查找
console.log(A); //返回数组["J", "J"]
在上面示例中,字符串 “\b\w” 表示一个匹配模式,其中 “\b" 表示单词的边界,"\w" 表示任意 ASCII 字符,反斜杠表示转义序列。为了避免 Regular() 构造函数的误解,必须使用“\”替换所有“\”字符,使用双反斜杠表示斜杠本身的意思。
在脚本中动态创建正则表达式时,使用构造函数 RegExp() 会更方便。例如,如果检索的字符串是由用户输入的,那么就必须在运行时使用 RegExp() 构造函数来创建正则表达式,而不能使用其他方法。
示例4
如果 RegExp() 构造函数的第 1 个参数是一个正则表达式,则第 2 个参数可以省略。这时 RegExp() 构造函数将创建一个参数相同的正则表达式对象。
var r = new RegExp("\\b\\w", "gi"); //构造正则表达式
var r1 = new RegExp(r); //把正则表达式传递给RegExp()构造函数
var s = "JavaScript JAVA"; //字符串直接量
var a = s.match(r); //匹配查找
console.log(a); //返回数组["J", "J"]
把正则表达式直接量传递给 RegExp() 构造函数,可以进行类型封装。
示例5
RegExp() 也可以作为普通函数使用,这时与使用 new 运算符调用构造函数功能相同。不过如果函数的参数是正则表达式,那么它仅返回正则表达式,而不再创建一个新的 RegExp() 对象。
```var a = new RegExp("\\b\\w", "gi"); //构造正则表达式对象
var b = new RegExp(a); //对正则表达式对象进行再封装
var c = RegExp(a); //返回正则表达式直接量
console.log(a.constructor == RegExp); //返回true
console.log(b.constructor == RegExp); //返回true
console.log(c.constructor == RegExp); //返回true
正则表达式直接量
正则表达式直接量使用双斜杠作为分隔符进行定义,双斜杠之间包含的字符为正则表达式的字符模式,字符模式不能使用引号,标志字符放在最后一个斜杠的后面。语法如下:
/pattern/attributes
示例6
下面示例定义一个正则表达式直接量,然后进行调用。
var r = /\b\w/gi;
var s = "JavaScript JAVA";
var a = s,match(r); //直接调用正则表达式直接量
console.log(a); //返回数组["j", "J"]
在 RegExp() 构造函数与正则表达式直接量语法中,匹配模式的表示是不同的。对于 RegExp() 构造函数来说,它接收的是字符串,而不是正则表达式的匹配模式。所以,在上面示例中,RegExp() 构造函数中第 1 个参数里的特殊字符,必须使用双反斜杠来表示,以防止字符串中的字符被 RegExp() 构造函数转义。同时对于第 2 个参数中的修饰符词也应该使用引号来包含。而在正则表达式直接量中每个字符都按正则表达式来定义,普通字符与特殊字符都会被正确解释。
示例7
在 RegExp() 构造函数中可以传递变量,而在正则表达式直接量中是不允许的。
var r = new RegExp("a" + s + "b", "g"); //动态创建正则表达式
var r = /"a" + s + "b"/g; //错误的用法
在上面示例中,对于正则表达式直接量来说,“"”和“+”都将被视为普通字符进行匹配,而不是作为字符与变量的语法标识符进行连接操作。
JavaScript 正则表达式支持 “g” “i” 和 “m” 三个标志修饰符,简单说明如下。
- “g”:global(全局)的缩写,定义全局匹配,即正则表达式将在指定字符串范围内执行所有匹配,而不是找到第一个匹配结果后就停止匹配。
- “i”:case-insensitive(大小写不敏感)中 insensitive 的缩写,定义不区分大小写匹配,即对于字母大小写视为等同。
- “m”:multiline(多行)的缩写,定义多行字符串匹配。
这三个修饰词分别指定了匹配操作的范围、大小写和多行行为,关键词可以自由组合。
JS exec()方法:执行正则表达式匹配
JavaScript 中的 exec() 方法用来检索字符串中的正则表达式的匹配,也即执行具体的正则表达式匹配操作。
exec()的具体语法格式如下:
regpxp.exec(string)
regexp表示正则表达式对象,参数 string 是要检索的字符串。
exec()将返回一个数组,其中存放匹配的结果。如果为找到匹配结果,则返回 null。
返回数组的第 1 个元素是与正则表达式相匹配的文本,第 2 个元素是与正则表达式的第 1 个子表达式相匹配的文本(如果有的话),第 3 个元素是与正则表达式的第 2 个子表达式相匹配的文本(如果有的话),以此类推。
除了数组元素和 length 属性之外,exec() 方法还会返回下面两个属性。
index:匹配文本的第一个字符的下标位置。input:存放被检索的原型字符串,即参数 string 自身。
在非全局模式下,exec() 方法返回的数组与 String.match() 方法返回的数组是相同的。
在全局模式下,exec() 方法与 String.match() 方法返回的结果不同。当调用 exec() 方法时,会为正则表达式对象定义 lastIndex属性,执行下一次匹配的起始位置,同时返回匹配数组,与非全局模式下的数组结构相同;而 String.match() 仅返回匹配文本组成的数组,没有附加信息。
因此,在全局模式下获取完整的匹配信息只能使用 exec() 方法。
当 exec() 方法找到了与表达式相匹配的文本后,会重置 lastIndex 属性为匹配文本的最后一个字符下标位置加 1,为下一次匹配设置起始位置。因此,通过反复调用 exec() 方法,可以遍历字符串,实现全局匹配操作,如果找不到匹配文本时,将返回 null,并重置 lastIndex 属性为 0。
示例
在下面示例中,定义正则表达式,然后调用 exec() 方法,逐个匹配字符串中每个字符,最后使用 while 语句显示完整的匹配信息。
var s = "JavaScript"; //测试使用的字符串直接量
var r = /\w/g; //匹配模式
while ((a = r.exec(s))) { //循环执行匹配操作
console.log("匹配文本 = " + a[0] + " a.index = " + a.index + " r.lastIndex = " + r.lastIndex); //显示每次匹配后返回的数组信息
}
在 while 语句中,把返回结果作为循环条件,当返回值为 null 时,说明字符串检测完毕,立即停止迭代;否则继续执行。在循环体内,读取返回数组 a 中包含的匹配结果,并读取结果数组的 index 属性,以及正则表达式对象的 lastIndex 属性,演示效果如图所示。
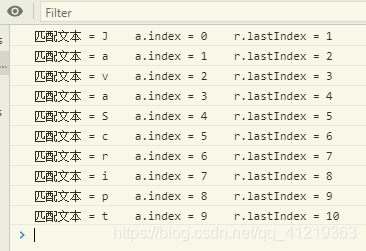
正则表达式对象的 lastIndex 属性是可读可写的。针对指定正则表达式对象,如果使用 exec() 方法对一个字符串执行匹配操作后,再对另一个字符串执行相同的匹配操作,则应该手动重置 lastIndex 属性为 0;否则不会从字符串的第一个字符开始匹配,返回的结果也会不同。
JS test()方法:检测一个字符串是否匹配某个正则表达式
JavaScript 正则表达式中的 test() 方法用来检测一个字符串是否匹配某个正则表达式
test()方法的具体格式如下:
regexp.test(string)
regexp 表示正则表达式对象,参数 string 表示要检测的字符串。如果字符串 string 中含有与 regexp 正则表达式匹配的文本,则返回 true;否则返回 false。
示例1
在下面示例中,使用test()方法检测字符串中是否包含字符。
var s = "JavaScript";
var r = /\w/g;
var b = r.test(s);
同样使用下面正则表达式也能够进行匹配,并返回true。
var r = /JavaScript/g;
var b = r.test(s);
但是如果使用下面这个正则表达式进行匹配,就会返回 false,因为在字符串“JavaScript”中找不到对应的匹配。
var r = /\d/g;
var b = r.test(s);
在全局模式下,test()等价于 exec()方法。配合循环语句,它们都能够迭代字符串,执行全局匹配操作,test()返回布尔值,exec()返回数组或者 null。虽然 test()方法的返回值是布尔值,但是通过正则表达式对象的属性和 RegExp静态属性,依然可以获取到每次迭代操作的匹配信息。
示例2
针对上面示例,下面使用test()方法代替exec()方法可以实现相同的设计效果。
var s = "JavaScript"; //测试字符串
var r = /\w/g; //匹配模式
while(r.test(s)) { //循环执行匹配检测,如果true,则继续验证
console.log("匹配文本 = " + RegExp.lastMatch + " r.lastIndex = " + r.lastIndex);
//利用RegExp静态属性显示当前匹配的信息
}
RegExp.lastMatch记录了每次匹配的文本,正则表达式对象的 lastIndex属性记录下一次匹配的起始位置。
使用 test()执行匹配时,IE 支持 RegExp.index记录了匹配文本的起始下标位置、Regexp.lastIndex记录下一次匹配的起始位置,但是其他浏览器不支持。
除了正则表达式内置方法外,字符串对象中很多方法也支持正则表达式的模式匹配操作,下面列表比较了字符串对象和正则表达式对象包含的 6 种模式匹配的方法,如表所示。
比较各种模式匹配的方法:
| 方法 | 所属对象 | 参数 | 返回值 | 通用性 | 特殊性 |
|---|---|---|---|---|---|
| exec() | 正则表达式 | 字符串 | 匹配结果的数组。如果没有找到,返回值为null | 通用强大 | 一次匹配一个单元,并提供详细的返回信息 |
| test() | 正则表达式 | 字符串 | 布尔值,表示是否匹配 | 快速验证 | 一次只能匹配一个单元,返回信息与exec()方法基本相似 |
| search() | 字符串 | 正则表达式 | 匹配起始位置。如果没有找到任何匹配的字符串,则返回-1 | 简单字符定位 | 不执行全局匹配,将忽略标志g,也会忽略正则表达式的 lastIndex 属性 |
| match() | 字符串 | 正则表达式 | 匹配的数组,或者匹配信息的数组 | 常用字符匹配方法 | 将根据全局模式的标志g决定匹配操作的行为 |
| replace() | 字符串 | 正则表达式或换文本 | 返回替换后的新字符串 | 匹配替换操作 | 可以支持替换函数,同时可以获得更多匹配信息 |
| split() | 字符串 | 正则表达式或分割字符 | 返回数组 | 特殊用途 | 把字符串分割为字符串数组 |
JS compile()方法:编译正则表达式
JavaScript 正则表达式中的 compile() 方法能够重新编译正则表达式,这样在脚本执行过程中可以动态修改正则表达式的匹配模式。
compile()方法的用法与 RegExp()构造函数的用法是相同的,不了解的读者请转到《在JS中使用正则表达式》。
compile() 的具体语法格式如下:
regexp.compile(regexp, modifier)
参数 regexp 表示正则表达式对象,或者匹配模式字符串。当第 1 个参数为匹配模式字符串时,可以设置第 2 个参数 modifier,使用它定义匹配的类型,如 “g” “i” “gi” 等。
示例
设计当匹配到第 3 个字母时,重新修改字符模式,定义在后续操作中,仅匹配大写字母,结果就只匹配到 S 这个大写字母。
var s = "JavaScript"; //测试字符串
var r = /\w/g; //匹配模式
var n = 0;
while(r.test(s)) {
if (r.lastIndex == 3) {
r.compile(/[A-Z]/g);
r.lastIndex = 3;
}
console.log("匹配文本 = " + RegExp.lastMatch + " r.lastIndex = " + r.lastIndex);
}
演示结果如下:
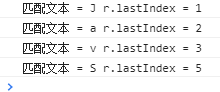
在上面示例代码中,r.compile(/[A-Z]/g);可以使用r.compile("[A-Z]", "g");代替。
重新编译正则表达式后,正则表达式搜包含的信息都被恢复到初始化状态,如 lastIndex变为 0。因此,如果想继续匹配,就需要设置 lastIndex属性,定义继续匹配的起始位置。反之,当执行正则表达式匹配操作之后,如果想用该正则表达式去继续匹配其他字符串,不妨利用下面方法恢复其初始状态,而不用手动重置 lastIndex属性。
regexp.compile(regexp);
其中 regexp 表示同一个正则表达式。
JS RegExp的实例属性(成员属性)和静态属性
正则表达式 RegExp类型拥有多个实例属性(也叫成员属性)和静态属性,通过它们能够了解正则表达式的一些情况。
RegExp 实例属性
每个正则表达式对象都包含一组属性,说明如表所示。
RegExp 对象属性:
| 属性 | 说明 |
|---|---|
| global | 返回 Boolean 值,检测 RegExp 对象是否具有标志 g |
| ignoreCase | 返回 Boolean 值,检测 RegExp 对象是否具有标志 i |
| multiline | 返回 Boolean 值,检测 RegExp 对象是否具有标志 m |
| lastIndex | 一个整数,返回或者设置执行下一次匹配的下标位置 |
| source | 返回正则表达式的字符模式源码 |
global、ignoreCase、multiline 和 source 属性都是只读属性。lastIndex 属性可读可写,通过设置该属性,可以定义匹配的起始位置。
示例
下面示例演示了如何读取正则表达式对象的基本信息,以及 lastIndex 属性在执行匹配前后的变化。
var s = "JavaScript"; //测试字符串
var r = /\w/g; //匹配模式
console.log("r.global = " + r.global); //true
console.log("r.ignoreCase = " + r.ignoreCase); //返回true
console.log("r.multiline = " + r.multiline); //返回false
console.log("r.source= " + r.source); //返回a
console.log("r.lastIndex = " + r.lastIndex); //返回0
r.exec(s); //执行匹配操作
console.log("r.lastIndex = " + r.lastIndex); //返回1
RegExp 静态属性
RegExp 类型包含一组静态属性,通过 RegExp 对象直接访问。这组属性记录了当前脚本中最新正则表达式匹配的详细信息,说明如表所示。
这些静态属性大部分有两个名字:长名(全称)和短名(简称,以 $ 开头表示)。
RegExp 静态属性:
| 长名 | 短名 | 说明 |
|---|---|---|
| input | $_ | 返回当前所作用的字符串,初始值为空字符串“” |
| index | 当前模式匹配的开始位置,从 0 开始计数。初始值为 -1,每次成功匹配时, index 属性值都会随之改变 | |
| lastIndex | 当前模式匹配的最后一个字符的下一个字符位置,从 0 开始计数,常被作为继续匹配的起始位置。ch初始值 -1,表示从起始位置开始搜索,每次成功匹配时,lastI 属性值都会随之改变 | |
| lastMatch | $& | 最后模式匹配的字符串,初始值为空字符串“”。在每次成功匹配时,lastMatch 属性值都会随之改变 |
| lastParen | $+ | 最后子模式匹配的字符串,如果匹配模式中包含有子模式(包含小括号的子表达式),在最后模式匹配中,最后一个子模式所匹配到的字符串。初始值为空字符串“”。在每次成功匹配时,lastParen属性值都会随之改变 |
| leftContext | $` | 在当前所作用的字符串中,最后模式匹配的字符串左边的所有内容。初始值为空字符串“”。每次匹配成功时,其属性值都会随之改变 |
| rightContext | $’ | 在当前所作用的字符串中,最后模式匹配的字符串右边的所有内容。初始值为空字符串“”。每次匹配成功时,其属性值都会随之改变 |
| $1~$9 | $1~$9 | 只读属性,如果匹配模式中有小括号包含的子字符串,$1$9属性值分别是第1个到第9个子模式所匹配到的内容。如果有超过9个以上的子模式,$1$9属性分别对应最后的9个子模式匹配结果。在一个匹配模式中,可以指定多个小括号包含的子模式,但 RegExp 静态属性只能存储最后9个子模式匹配的结果。在 RegExp 实例对象的一些方法返回的结果数组中,可以阔的所有圆括号内的子匹配结果 |
示例1
下面示例演示了 RegExp类型静态属性使用,匹配字符串“JavaScript”。
var s = "JavaScript, not JavaScript";
var r = /(Java)Script/gi;
var a = r.exec(s); //执行匹配操作
console.log(RegExp.input); //返回字符串“JavaScript, not JavaScript”
console.log(RegExp.leftContext); //返回空字符串,左侧没有内容
console.log(RegExp.rightContext); //返回字符串“,not JavaScript”
console.log(RegExp.lastMatch); //返回字符串“JavaScript”
console.log(RegExp.lastParen); //返回字符串“Java”
执行匹配操作后,各个属性的返回值说明如下:
- input 属性记录操作的字符串:“JavaScript, not JavaScript”。
- leftContext 属性记录匹配文本左侧的字符串在第一次匹配操作时,左侧文本为空。而 rightContext 属性记录文本右侧的文本,即为 “,not JavaScript”。
- lastMatch 属性记录匹配的字符串,即为"JavaScript"。
- lastParen 属性记录匹配的分组字符串,即为“Java”。
如果匹配模式中包含多个子模式,则最后一个子模式所匹配的字符就是“RegExp,lastParen”。
var r = /(Java)(Script)/gi;
var a = r.exec(s); //执行匹配操作
console.log(RegExp.lastParen); // 返回字符串"Script" ,而不再是"Java"。
示例2
针对上面示例也可以使用短名来读取相关信息。
var s = "JavaScript, not JavaScript";
var r = /(Java)(Script)/gi;
var a = r.exec(s);
console.log(RegExp.$_); //返回字符串“JavaScript, not JavaScript”
console.log(RegExp["$`"]); //返回空字符串
console.log(RegExp["$'"]); //返回字符串“,not JavaScript”
console.log(RegExp["$&"]); //返回字符串“JavaScript”
console.log(RegExp["$+"]); //返回字符串“Script”
这些属性的值都是动态的,在每次执行匹配操作时,都会被重新设置。
JS正则表达式语法大全
正则表达式的语法体现在字符模式上。字符模式是一组特殊格式的字符串,它由一系列特殊字符和普通字符构成,其中每个特殊字符都包含一定的语义和功能。
描述字符
根据正则表达式语法规则,大部分字符仅能够描述自身,这些字符被称为普通字符,如所有的字母、数字等。
元字符就是拥有特动功能的特殊字符,大部分需要加反斜杠进行标识,以便于普通字符进行区别,而少数元字符,需要加反斜杠,以便转译为普通字符使用。JavaScript 正则表达式支持的元字符如表所示。
| 元字符 | 描述 |
|---|---|
| . | 查找单个字符,除了换行和行结束符 |
| \w | 查找单词字符 |
| \W | 查找非单词字符 |
| \d | 查找数字 |
| \D | 查找非数字字符 |
| \s | 查找空白字符 |
| \S | 查找非空白字符 |
| \b | 匹配单词边界 |
| \B | 匹配非单词边界 |
| \0 | 查找NULL字符 |
| \n | 查找换行符 |
| \f | 查找换页符 |
| \r | 查找回车符 |
| \t | 查找制表符 |
| \v | 查找垂直制表符 |
| \xxx | 查找以八进制数 xxxx 规定的字符 |
| \xdd | 查找以十六进制数 dd 规定的字符 |
| \uxxxx | 查找以十六进制 xxxx 规定的 Unicode 字符 |
表示字符的方法有多种,除了可以直接使用字符本身外,还可以使用 ASCII 编码或者 Unicode 编码来表示。
示例1
下面使用ASCII编码定义正则表达式直接量
var r = /\x61/;
var s = "JavaScript";
var a = s.match(r);
由于字母 a 的 ASCII 编码为 97,被转换为十六进制数值后为 61,因此如果要匹配字符 a,就应该在前面添加“\x”前缀,以提示它为 ASCII 编码。
示例2
除了十六进制外,还可以直接使用八进制数值表示字符。
var r = /\141/;
var s = "JavaScript";
var a = s.match(r);
使用十六进制需要添加“\x”前缀,主要是为了避免语义混淆,而八进制则不需要添加前缀。
示例3
ASCII 编码只能够匹配有限的单字节字符,使用 Unicode 编码可以表示双字节字符。Unicode 编码方式:“\u”前缀加上 4 位十六进制值。
var r = /\u0061/g;
var s = "JavaScript";
var a = s.match(r);
在 RegExp()构造函数中使用元字符时,应使用双斜杠。
var r = new RegExp(\\u0061);
RegExp()构造函数的参数只接受字符串,而不是字符模式。在字符串中,任何字符加反斜杠还表示字符本身,如字符串“\u”就被解释为 u 本身,所以对于\u0061字符串来说,在转换为字符模式时,就被解释为u0061,而不是\u0061,此时反斜杠就失去转义功能。解决方法:在字符u前面加双反斜杠。
描述字符范围
在正则表达式语法中,方括号表示字符范围。在方括号中可以包含多个字符,表示匹配其中任意一个字符。如果多个字符的编码顺序是连续的,可以仅指定开头和结尾字符,省略中间字符,仅使用连字符-表示。如果在方括号内添加脱字符^前缀,还可以表示范围之外的字符。例如:
[abc]:查找方括号内任意一个字符。[^abc]:查找不在方括号内的字符。[0-9]:查找从 0 至 9 范围内的数字,即查找数字。[a-z]:查找从小写 a 到小写 z 范围内的字符,即查找小写字母。[A-Z]:查找从大写 A 到大写 Z 范围内的字符,即查找大写字母。[A-z]:查找从大写 A 到小写 z 范围内的字符,即所有大小写的字母。
如果匹配任意 ASCII 字符:
var r = /[\u0000-\u00ff]/g;
如果匹配任意双字节的汉字:
var r = /[a-zA-Z0-9]/g;
如果匹配任意大小写字母和数字:
var r = /[a-zA-Z0-9]/g;
使用下面字符模式可以匹配任意大写字母:
var r = /[\u0041-\u004A]/g;
使用下面字符模式可以匹配任意小写字母:
var r = /[\u0061-\u0074]/g;
示例2
在字符范围内可以混用各种字符模式
var s = "abcdez"; // 字符串直接量
var r = /[abce-z]/g; //字符a,b,c,以及从e-z之间的任意字符
var a = s.match(r); // 返回数组["a","b","c","e","z"]
示例3
在中括号内不要有空格,否则会误解为还要匹配空格
var r = /[0-9]/g;
示例4
字符范围可以组合使用,以便设计更灵活的匹配模式.
var s = "abc4 abd6 abe3 abf1 abg7"; //字符串直接量
var r = /ab[c-g][1-7]/g; //前两个字符为ab,第三个字符为从c到g,第四个字符为1~7的任意数字
var a = s.match(r); //返回数组["abc4","abd6","abe3","abf1","abg7"]
示例5
使用反义字符范围可以匹配很多无法直接描述的字符,达到以少应多的目的。
var r = /[^0123456789]/g;
选择匹配
选择匹配类似于 JavaScript 的逻辑于运算,使用竖线|描述,表示在两个子模式的匹配结果中任选一个。例如:
- 匹配任意数字或字母
var r = /\w+|\d+/;
- 可以定义多重选择模式。设计方法:在多个子模式之加入选择操作符。
var r = /(abc)|(efg)|(123)|(456)/;
为了避免歧义,应该为选择操作的多个子模式加上小括号。
示例
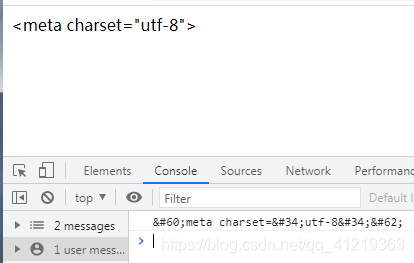
设计对提交的表单字符串进行敏感词过滤。先设计一个敏感词列表,然后使用竖线把它们连接在一起,定义选择匹配模式,最后使用字符串的replace()方法把所有敏感字符替换为可以显示的编码格式。代码如下:
var s = '<meta charset="utf-8">; // 待过滤的表单提交信息
var r = /\'|\"|\<|\>/gi; //过滤敏感字符的正则表达式
function f(){ //替换函数
把敏感字符替换为对应的网页显示的编码格式
return "&#" + arguments[0].charCodeA(0) + ";";
}
var a = s.replace(r,f); //执行过滤替换
document.write(a); // 在网页中显示正常的字符信息
console.log(a);
显示结果如下:
重复匹配
在正则表达式语法中,定义了一组重复类量词,如表所示。它们定义了重复匹配字符的确数或约数。
重复类量词列表:
| 量词 | 描述 |
|---|---|
| n+ | 匹配任何包含至少一个 n 的字符串 |
| n* | 匹配任何包含另个或多个 n 的字符串 |
| n? | 匹配任何包含零个或一个 n 的字符串 |
| n{x} | 匹配包含 x 个 n 的序列的字符串 |
| n{x,y} | 匹配包含最少 x 个、最多 y 个 n 的序列的字符串 |
| n{x,} | 匹配包含至少 x 个 n 的序列的字符串 |
示例
下面结合示例进行演示说明,先设计一个字符串:
var s = "ggle gogle google gooogle goooogle gooooogle goooooogle gooooooogle goooooooogle";
- 如果仅匹配单词 ggle 和gogle,可以设计:
var r = /go?gle/g;
var a = s.match(r);
量词?表示前面字符或子表达式为可有可无,等效于:
var r = /go{0,1}gle/g;
var a = s.match(r);
2.如果匹配第4个单词gooogle,可以设计:
var r = /go{3}gle/g;
var a = s.match(r);
等效于:
var r = /gooogle/g;
var a = s.match(r);
3.如果匹配第4个到第6个之间的单词,可以设计:
var r = /go{3,5}gle/g;
var = s.match(r);
4.如果匹配所有的单词,可以设计:
var r = /go*gle/g;
var a = s.match(r);
量词*表示前面字符或表达式可以不出现,或者重复出现任意多次。等效于:
var r = /go{0,}gle/g;
var a = s.match(r);
5.如果匹配包含字符"o"的所有词,可以设计:
var r = /go+gle/g;
var a = s.match(r);
量词+表示前面字符或子表达式至少出现1次,最多重复次数不限。等效于:
var r = /go{1,}gle/g;
var a = s.match(r);
重复类量词总是出现在它们所作用的字符或子表达式后面。如果想作用于多个字符,需要使用小括号把它们包裹在一起形成一个子表达式。
惰性匹配
重复类量词都具有贪婪性,在条件允许的前提下,会匹配尽可能多的字符。
- ?、{n} 和 {n,m} 重复类具有弱贪婪性,表现为贪婪的有限性。
- *、+ 和 {n,} 重复类具有强贪婪性,表现为贪婪的无限性。
示例1
越是排在左侧的重复类量词匹配优先级越高。下面示例显示当多个重复类量词同时满足条件时,会在保证右侧重复类量词最低匹配次数基础上,使最左侧的重复类量词尽可能的占有所有字符。
var s = "<html><head><title></title></head><body></body></html>";
var r = /(<.*>)(<.*>)/;
var a = s.match(r);
//左侧表达式匹配"<html><head><title></title></head><body></body></html>"
console.log(a[1]);
console.log(a[2]); //右侧表达式匹配“</html>”
与贪婪匹配相反,惰性匹配将遵循另一种算法:在满足条件的前提下,尽可能少的匹配字符。定义惰性匹配的方法:在重复类量词后面添加问号?限制词。贪婪匹配体现了最大化匹配原则,惰性匹配则体现最小化匹配原则。
示例2
下面示例演示了如何定义匹配模式
var s = "<html><head><title></title></head><body></body></html>";
var r = /<.*?>/
var a = s.match(r); //返回单个元素数组["<html>"]
在上面示例中,对于正则表达式/<.*?>/来说,它可以返回匹配字符串<>,但是为了能够确保匹配条件成立,在执行中还是匹配了带有4个字符串html。
惰性取值不能够以违反模式限定的条件而返回,除非没有找到符合条件的字符串,否则必须满足它。
针对 6 种重复类惰性匹配的简单描述如下:
- {n,m}?: 尽量匹配 n 次 , 但是为了满足限定条件也可能最多重复 m 次。
- {n}?: 尽量匹配 n 次。
- {n,}?: 尽量匹配 n 次,但是为了满足限定条件也可能匹配任意次。
- ?? : 尽量匹配,但是为了满足限定条件也可能最多匹配 1 次,相当于{0,1}?。
- +?: 尽量匹配 1 次,但是为了满足限定条件也可能匹配任意次, 相当于{1,}?。
- *?: 尽量不匹配,但是为了满足限定条件也可能匹配任意次,相当于{0,}?
边界量词
边界就是确定匹配模式的位置,如字符串的头部或尾部,具体说明如表所示。
JavaScript 正则表达式支持的边界量词
| 量词 | 说明 |
|---|---|
| ^ | 匹配开头,在多行检测中,会匹配一行的开头 |
| $ | 匹配结尾,在多行检测中,会匹配一行的结尾 |
下面代码演示如何使用边界量词。先定义字符串:
var s = "how are you";
1.匹配最后一个单词
var r = /\w+$/;
var a = s.match(r); // 返回数组["you"]
2.匹配第一个单词
var r = /^\w+/;
var a = s.match(r); //返回数组["how"]
3.匹配每一个单词
var r = /\w+/g;
var a = s.match(r); // 返回数组["how","are","you"];
声明词量
声明表示条件的意思。声明词量包括正向声明和反向声明两种模式。
正向声明
置顶匹配模式后面的字符必须被匹配,但又不返回这些字符。语法格式如下:
匹配模式 ( ? = 匹配条件 )
声明包含在小括号内,它不是分组,因此作为子表达式。
下面代码定义一个正前向声明的匹配模式。
var s = "one : 1; two : 2";
var r = /\w*(?==)/; // 使用正前向声明,置顶执行匹配必须满足的条件
var a = s.match(r); // 返回数组["two"]
在上面示例中,通过?==锚定条件,指定只有在\w*所能够匹配的字符后面跟随一个等号字符,才能够执行\w*匹配。所有,最后匹配的字符串two,而不是字符串one.
反向声明
与正向声明匹配相反,置顶接下来的字符都不必被匹配。语法格式如下:
匹配模式 (?! 匹配条件)
下面代码定义一个反前向声明的匹配模式。
var s = "one : 1; two : 2";
var r = /\w*(?!=)/; // 使用正前向声明,指定执行匹配不必满足的条件
var a = s.match(r); // 返回数组["one"]
在上面示例中,通过?!=锚定条件,指定只有\w*所能够匹配的字符后面不跟随一个等号字符,才能够执行 \w*匹配。所以,最后匹配的字符串one,而不是two。
子表达式
使用小括号可以对字符模式进行任意分组,在小括号内的字符串表示子表达式,也成为子模式。子表达式具有独立的匹配功能,保存独立的匹配结果;同时,小括号后的量词将会通于整个子表达式。
通过分组可以在一个完整的字符模式中定义一个或多个子模式。当正则表达式成功地匹配目标字符串后,也可以从目标字符串中抽出与子模式匹配的子内容。
示例
在下面代码中,不仅能匹配出每个变量声明,同时还抽出每个变量及其值。
var s = "ab=21, bc=45, cd=43";
var r = /(\w+)=(\d*)/g;
while(a = r.exec(s)){
console.log(a); // 返回类似["ab=21","bc=45","cd="43"]三个数组
}
反向引用
在字符模式中,后面的字符可以引用前面的字表达式。实现方法如下:
\+ 数字
数字指定了子表达式在字符模式中的顺序。如\1引用的是第一个子表达式,\2引用的是第2个子表达式。
示例1
在下面代码中,通过引用前面字表达式匹配的文本,实现成组匹配字符串。
var s = "<h1>title<h1><p>text<p>";
var r = /(<\/?\w+>).*\1/g;
var a = s.match(r); //返回数组["<h1>title<h1>","<p>text<p>"]
由于子表达式可以相互嵌套,它们的顺序将根据左括号的顺序来确定。例如,下面示例定义匹配模式包含多个子表达式。
var s = "abc";
var r = /(a(b(c)))/;
var a = s.match(r); //返回数组["abc","abc","bc","c"]
在这个模式中,共产生了 3 个反向引用,第一个是“(a(b©))”,第二个是“(b©)”,第三个是“©”。它们引用的匹配文本分别是字符串“abc”、“bc”和“c”。
对子表达式的引用,是指引用前面子表达式所匹配的文本,而不是子表达式的匹配模式。如果要引用前面子表达式的匹配模式,则必须使用下面方式,只有这样才能够达到匹配目的。
var s = "<h1>title</h1><p>text</p>";
var r = /((<\/?\w+>).*(<\/?\w+>))/g;
var a = s.match(r); //返回数组["<h1>title</h1>","<p>text</p>"]
反向引用在开发中主要有以下几种常规用法。
示例2
在正则表达式对象的 test() 方法中,以及字符串对象的 match() 和 search() 等方法中使用。在这些方法中,反向引用的值可以从 RegExp() 构造函数中获得。
var s = "abcdefghijklmn";
var r = /(\w)(\w)(\w)/;
r.test(s);
console.log(RegExp.$1); //返回第1个子表达式匹配的字符a
console.log(RegExp.$2); //返回第2个子表达式匹配的字符b
console.log(RegExp.$3); //返回第3个子表达式匹配的字符c
通过上面示例可以看到,正则表达式执行匹配检测后,所有子表达式匹配的文本都被分组存储在 RegExp() 构造函数的属性内,通过前缀符号$与正则表达式中子表达式的编号来引用这些临时属性。其中属性 $1 标识符指向第 1 个值引用,属性 $2 标识符指向第 2 个值引用。
示例3
可以直接在定义的字符模式中包含反向引用。这可以通过使用特殊转义序列(如 \1、\2 等)来实现。
var s = "abcbcacba";
var r = /(\w)(\w)(\w)\2\3\1\3\2\1/;
var b = r.test(s); //验证正则表达式是否匹配该字符串
console.log(b); //返回true
在上面示例的正则表达式中,“\1”表示对第 1 个反向引用 (\w) 所匹配的字符 a 进行引用,“\2”表示对第 2 个反向引用 (\w) 所匹配的字符串 b 进行引用,“\3”表示对第 3 个反向引用 (\w) 所匹配的字符 c 进行引用。
示例4
可以在字符串对象的 replace() 方法中使用。通过使用特殊字符序列$1、$2、$3 等来实现。例如,在下面的示例中将颠倒相邻字母和数字的位置。
var s = "aa11bb22c3d4e5f6";
var r = /(\w+?)(\d+)/g;
var b = s.replace(r,"$2$1");
console.log(b); //返回字符串“aa11bb22c3 d4e5f6”
在上面例子中,正则表达式包括两个分组,第 1 个分组匹配任意连续的字母,第 2 个分组匹配任意连续的数字。在 replace() 方法的第 2 个参数中,$1 表示对正则表达式中第 1 个子表达式匹配文本的引用,而 $2 表示对正则表达式中第 2 个子表达式匹配文本的引用,通过颠倒 $1 和 $2 标识符的位置,即可实现字符串的颠倒来替换原字符串。
禁止引用
反向引用会占用一定的系统资源,在较长的正则表达式中,反向引用会降低匹配速度。如果分组仅仅是为了方便操作,可以禁止反向引用。
实现方法:在左括号的后面加上一个问号和冒号。
var s1 = "abc";
var r = /(?:\w*?)|(?:\d*?)/;
var a = r.test(si);
非引用型分组必须使用子表达式,但是又不希望存储无用的匹配信息,或者希望提高匹配速度来说,是非常重用的方法。
JS正则表达式匹配时间和日期
时间
以24小时制为例,时间字符串格式如下:
23:59
02:07
模式分析:
- 共 4 位数字,第 1 位数字可以位 [0-2]。
- 当第 1 位为 “2” 时,第 2 位可以为[0-3]。
- 当第 3 个数字为 [0-5],第 4 位为 [0-9]。
实现代码:
var regex = /^([01][0-9][2][0-3]:[0-5][0-9]$/;
console.log(regex.test("23:59"));
console.log(regex.test("02:07"));
如果要求匹配“7:9” 格式,也就是说时分前面的“0”可以省略。优化后的代码如下:
var regex = /^(0?[0-9]|1[0-9]|[2][0-3]):(0?[0-9]|[1-5][0-9])$/;
console.log(regex.test("23:59")); //true
console.log(regex.test("02:07")); //true
console.log(regex.test("7:9")); //true
日期
常见日期格式:yyyy-mm-dd。例如:2019-09-05。
模式分析:
- 年:4 位数字即可,可用 [0-9] {4}。
- 月:共 12个月,分两种情况:"01"“02”…“09” 和 "10""11"“12”,可用 (0[1-9]1[0-2])。
- 日:最大 31 天,可用 (0[1-9][12][0-9]3[01])。
实现代码:
var regex = /^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])$/;
console.log(regex.test("2019-09-05"));
JS正则表达式匹配货币数字
英文的货币数字采用的是千位分隔符格式,如“12345678”表示为“12,345,678”。下面我们分步讲解如何书写正则表达式。
- 根据千位把相应的位置替换成
,,以最后一个逗号为例。解决方法:(?=\d{3}$)。
var result = "12345678".replace(/(?=\d{3}$)/g,',');
console.log(result); // "12345,678"
其中(?=\d{3}$)匹配\d{3}$前面的位置,而\d{3}$匹配的是目标字符串最后 3 位数字。
- 确定所有的逗号。因为逗号出现的位置,要求后面 3 个数字一组,也就是
\d{3}至少出现一次。此时可以使用量词+:
var result = "12345678".replace(/(?=(\d{3}) + $)/g,',');
console.log(result); // "12,345,678"
- 匹配其余数字,会发现问题如下:
var result = "123456789".replace(/(?=(\d{3} + $)/g,',');
console.log(result); // ",123,456,789"
因为上面的正则表达式,从结尾向前数,只要是 3 的倍数,就把其前面的位置替换成逗号。那么如何解决匹配的位置不能是开头呢?
- 匹配开头可以使用
^,但要求该位置不是开头,可以考虑使用(?!^)。实现代码如下:
var regex = /(?!^)(?=(\d{3} + $)/g;
var result = "12345678".replace(regex,',');
console.log(result);
result = "123456789".replace(regex,',');
console.log(result);
- 如果要把“12345678 123456789”替换成“12,345,678 123,456,789”,此时需要修改正则表达式,可以把里面的开头
^和结尾$修改成\b。实现代码如下:
var string = "12345678 123456789";
var regex = /(?!\b)(?=(\d{3}+\b))/g;
var result = string.replace(regex,',');
console.log(result); // "12,345,678 123,456,789"
其中(?!\b)要求当前是一个位置,但不是\b亲们的位置,其实(?!\b)说的就是\B。因此最终正则变成了:/\B(?=(\d{3}+\b)/g。
- 进一步格式化。千分符表示法一个常见的应用就是货币格式化。例如:
1888
格式化为:
$ 1888.00
有了前面的铺垫,可以很容易的实现,具体代码如下:
function format (num) {
return num.toFixed(2).replace(/\B(?=(\d{3}+\b)/g,',').replace(/^/,"$$");
};
console.log(format(1888));














 7526
7526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









