







sklearn教程05 - 特征选择降维(低方差过滤,皮尔逊相关系数),PCA主成分分析降维
sklearn一站式学习->: sklearn一站式学习,机器学习数据集获取与划分,无量纲化,特征提取,特征降维(低方差,皮尔逊,PCA),KNN,模型选择调优,决策树,朴素贝叶斯,岭回归,kMeans等等
python一站式学习->: python一站式学习,python基础,数据类型,numpy,pandas,机器学习,NLP自然语言处理,deepseek大预言模型,Tensorflow,CV视觉
降维:降低特征个数,得到一组不相关或相关性较低的纬度的过程(剔除冗余相关的特征)
特征选择
特征选择:原有数据中包含冗余的特征,从中找出主要特征
filter过滤式: 1. 方差选择法:方差较低的特征过滤
2. 相关系数法:特征与特征之间的相关程度
embedded 嵌入式(后续文档中会讲解):
1.决策树
2.正则化
3.深度学习
1. 低方差特征过滤
原理:某个特征大多数样本值接近(方差过低),说明特征都接近或一样,可以剔除这个特征
from sklearn.feature_selection import VarianceThreshold
def test():
# threshold=0.5 过滤小于0.5的方差
transform = VarianceThreshold(threshold=0.5)
vData = transform.fit_transform([[1, 10, 0.5], [2, 29, 0.2], [3, 40, 0.3]])
print("方差选择后-------------", vData.shape, vData)
if __name__ == '__main__':
test()

2. 相关系数法-皮尔逊相关系数
公式一:基于均值离差,直接体现协方差与标准差的比值,理论意义明确。
r
x
y
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
∑
i
=
1
n
(
y
i
−
y
ˉ
)
2
r_{xy} = \frac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum_{i=1}^{n}(x_i - \bar{x})^2} \sqrt{\sum_{i=1}^{n}(y_i - \bar{y})^2}}
rxy=∑i=1n(xi−xˉ)2∑i=1n(yi−yˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
公式二:通过原始数据的总和计算,避免先计算均值的步骤。
r
=
n
∑
x
y
−
∑
x
∑
y
n
∑
x
2
−
(
∑
x
)
2
n
∑
y
2
−
(
∑
y
)
2
r = \frac{n\sum xy - \sum x \sum y}{\sqrt{n\sum x^{2} - (\sum x)^{2}} \sqrt{n\sum y^{2} - (\sum y)^{2}}}
r=n∑x2−(∑x)2n∑y2−(∑y)2n∑xy−∑x∑y
两个公式展开后是相等的,这里不多做数学推导
- r<0 负相关 r>0正相关
- |r| <0.4 低度相关 0.4<=|r|<=0.7 显著相关 0.7<=|r|<=1 高度线性相关
准备数据
import pandas as pd
p1 = pd.DataFrame([{"name":"张三","age":22,"height":175,"weight":156},
{"name":"李四","age":12,"height":126,"weight":98},
{"name":"王五","age":17,"height":151,"weight":123},
{"name":"老刘","age":16,"height":153,"weight":135}])
from scipy.stats import pearsonr
def test():
r = pearsonr(p1 ["age"],p1 ["height"])
print("age和height特征列 相关性结果----------",r)
r2 = pearsonr(p1["height"], p1["weight"])
print("height和weight特征列 相关性结果----------", r2)
if __name__ == '__main__':
test()

statistic表示相关性,表明年龄和身高,身高和体重相关性都很高
当两列相关性非常高时:
- 选取其中一列作为特征值
- 两列求加权求和得到新的特征列,舍弃原来两列特征
- 使用下方的主成分分析
主成分分析法
- 目标:将高维数据转换为低维表示,同时保留尽可能多的原始信息。
- 用途:数据可视化、噪声过滤、特征提取、减少计算复杂度等。
其核心思想可概括为:
方差最大化:新坐标系的选择使数据在第一个主成分上的方差最大,后续主成分依次递减,且彼此正交(不相关)。
线性组合:每个主成分是原始变量的线性组合,且彼此正交(不相关)。
from sklearn.decomposition import PCA
def test():
# n_components=0.95 小数:表示保留百分之多少的信息
# 整数:减少到多少特征降 纬度
pcaTransform = PCA(n_components=0.95)
pcaData = pcaTransform.fit_transform([[2,8,4,6],[8,0,3,5],[1,0,9,7]])
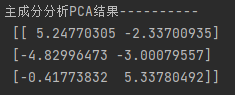
print("主成分分析PCA结果----------\n ", pcaData)
if __name__ == '__main__':
test()
结果纬度少了一半,n_components信息还保留了0.95,从而达到降维目的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









