







Pandas教程04 - 算数运算,逻辑运算,统计运算,自定义运算
pandas一站式学习->: pandas一站式学习,创建,索引使用,运算,pd可视化柱状图等,csv,hdf5,json格式数据读取存储,NaN值处理,数据离散化,数据合并,交叉表与透视表
python一站式学习->: python一站式学习,python基础,数据类型,numpy,pandas,机器学习,NLP自然语言处理,deepseek大预言模型,Tensorflow,CV视觉
算数运算
方式一:使用+ - * / 运算符号
方式二:使用add, sub,multiply,divide函数
import pandas as pd
p1 = pd.DataFrame([[1,2,3],[4,5,6]])
# 方式一
new_p1 = p1 + 1
# 方式二
new_p1 = p1.add(1)
# 结果new_p1: [[2, 3, 4],[5, 6, 7]]
逻辑运算
数据准备
import numpy as np
import pandas as pd
# 制造3个地区,5天的气温变化数据
data = np.random.uniform(10,20,(3,5))
# 保留一位小数
p1 = np.around(data,decimals=1)
date = pd.date_range(start="20260101",periods=5,freq="D")
city =['city{}'.format(i+1) for i in range(3)]
# 创建datafram
pd1 = pd.DataFrame(p1,index=city,columns=date)
pd1
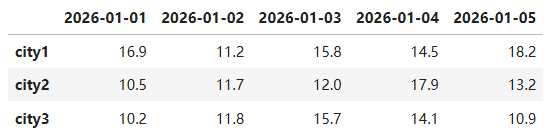
逻辑运算符 < > | &
# 判断所有数据是否大于15
pd1>15
# 判断某列数据是否大于15
pd1["2026-01-01"]>15
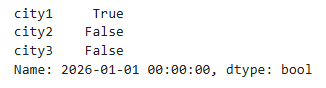
布尔索引
# 判断所有数据是否大于15
new_pd1 = pd1[pd1["2026-01-01"]>15]

多条件搜索
方式一:data[ (data[“列名1”]>10) & (data[“列名2”]<20) ]
方式二:data.query( “列名1>10 & 列名2 < 20”) (推荐,但列索引名不能像日期这样数字开头,必须遵循命名规则)
# 判断所有数据是否大于15
pd1[(pd1["2026-01-01"]>10.2) & (pd1["2026-01-02"]<11.7)]

是否包含 isin()
# 是否包含
new_pd1 = pd1.isin([10.2])
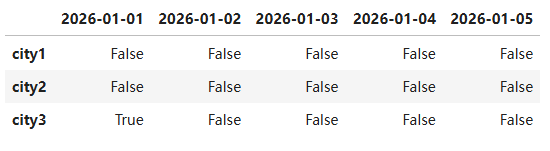
isin()过滤数据
# isin()过滤数据
new_pd1 = pd1[pd1["2026-01-01"].isin([10.2])]

统计运算
数据准备
import pandas as pd
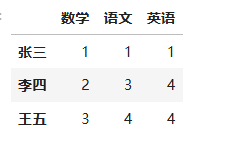
item = ['数学','语文','英语']
name=['张三','李四','王五']
# 创建datafram
pd1 = pd.DataFrame([[1,1,1],
[2,3,4],
[3,4,4]],index=item,columns=name)
pd1
describe整体统计
pd1.describe()
# count计数
# mean 平均值
# std 标准差
# min/max 最小/最大值
# 百分比 是分位数
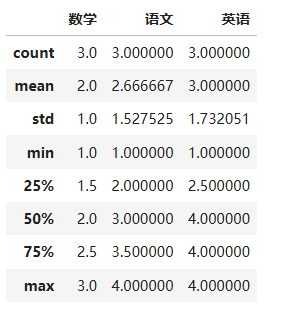
常用统计函数
# 求和 # 其他函数不做演示了,这里列出常用的统计函数
pd1.sum()
# max() 最大数
# min() 最小数
# median() 中位数
# mean() 平均值
# abs() 绝对值
# mode() 众数(每列出现次数最多的数,如果次数一样,就返回多个)
# std 标准差
# prod(axis=1, skipna=True) axis=1/0按照行或者列,skipna跳过NaN后,进行乘积
# var(axis=0,ddof=1) axis=1/0按照行或者列,ddof=1/0计算样本方差或者总体方差
# idxmax() 最大数位置的索引
# idxmin() 最小数位置的索引

累计统计函数
# axis=0/1 控制行列方向
# cumsum() 计算前n个数的和
# cummax() 计算前n个数的最大值
# cummax() 计算前n个数的最小值
# cumprod() 计算前n个数的乘积
自定义运算 apply
data.apply(fun , axis=1/0) 对数据按照行或者列进行 fun自定义函数运算
# 求输入列中最大值,和最小值的差值是多少
# lambda函数就是fun , x为输入的行或者列(由axis=1/0决定)
pd1[['数学','语文']].apply(lambda x: x.max()-x.min() )


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









