







论文地址:https://arxiv.org/pdf/2108.05054.pdf https://arxiv.org/pdf/2108.05054.pdf
https://arxiv.org/pdf/2108.05054.pdf
代码地址:https://github.com/chosj95/MIMO-UNethttps://github.com/chosj95/MIMO-UNet

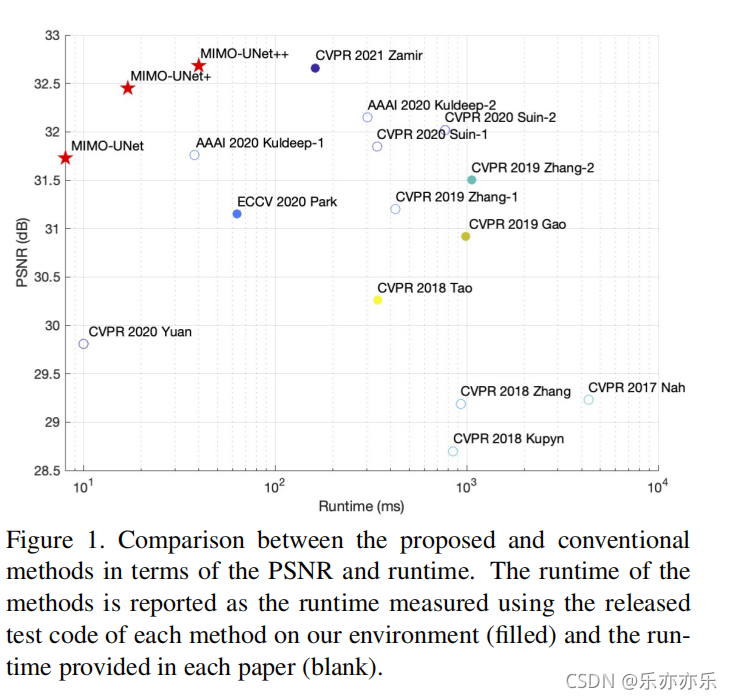
粗到精细的策略已被广泛应用于单个图像去模糊网络的体系结构设计。传统的方法通常将子网络与多尺度输入图像叠加,逐步提高图像从底层子网到顶层子网的清晰度,不可避免地产生较高的计算成本。为了实现快速和准确的去模糊网络设计,重新考虑了粗到细的策略,并提出了一个多输入多输出unet网(MIMO-UNet)。
MIMO-UNet有三个不同的特性。
首先,MIMO-UNet的单个编码器采用多尺度的输入图像来减轻训练的难度。
其次,MIMO-UNet的单个解码器输出多个不同尺度的去模糊图像,使用单个u形网络模拟多级联u型网络。
最后,引入非对称特征融合,有效地合并多尺度特征。
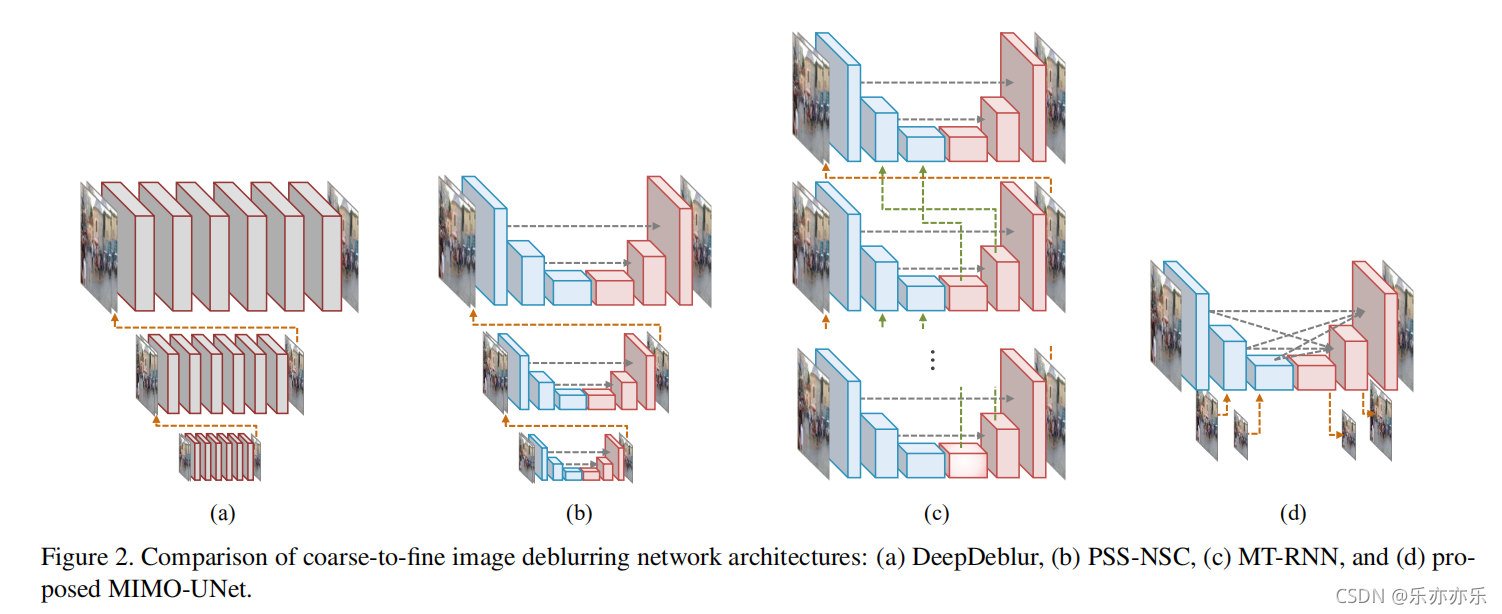
图2 粗到细去模糊网络的对比。
在本文中,作者重新讨论了从粗到细的方案,并提出了一种新的去模糊网络,称为多输入多输出UNet(MIMO-UNet),它可以处理低计算复杂度的多尺度模糊。所提出的MIMOUNet是一个单一基于编码器-解码器的u型网络,具有三个不同的特征。(与上文介绍基本相同)
首先,MIMO-UNet的单个解码器输出多个去模糊图像,因此将解码器命名为多输出单个解码器(MOSD)。MOSD虽然简单,但可以模拟传统的由堆叠子网络组成的网络架构,并引导解码器层以coarse-to-fine 的方式逐步恢复潜在的清晰图像。
其次,MIMO-UNet的单个编码器采用多尺度的输入图像;因此,编码器被称为多输入单个编码器(MISE)。
最后,引入了非对称特征融合(AFF),有效地合并了多尺度特征。AFF采用不同尺度的特征,合并跨编码器和解码器的多尺度信息流,以提高去模糊性能。
Proposed method
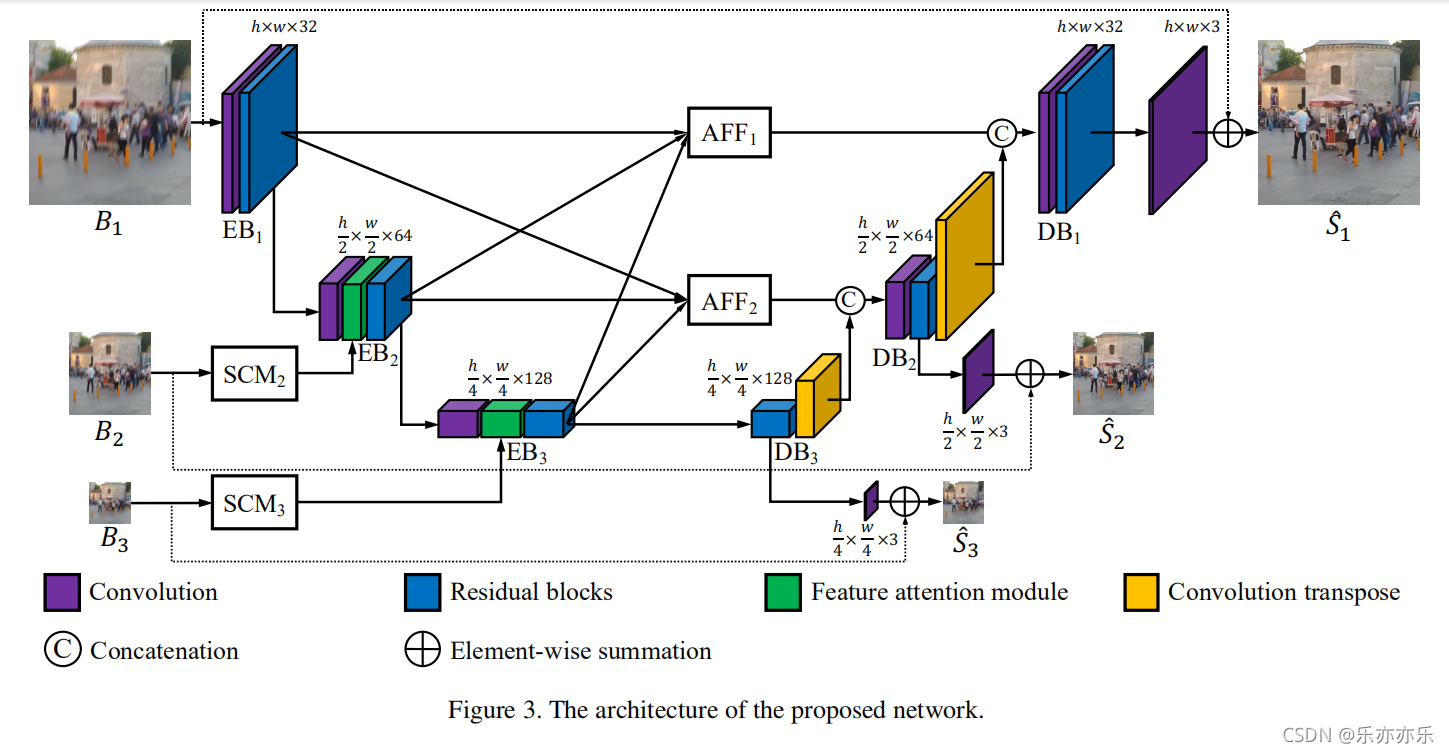
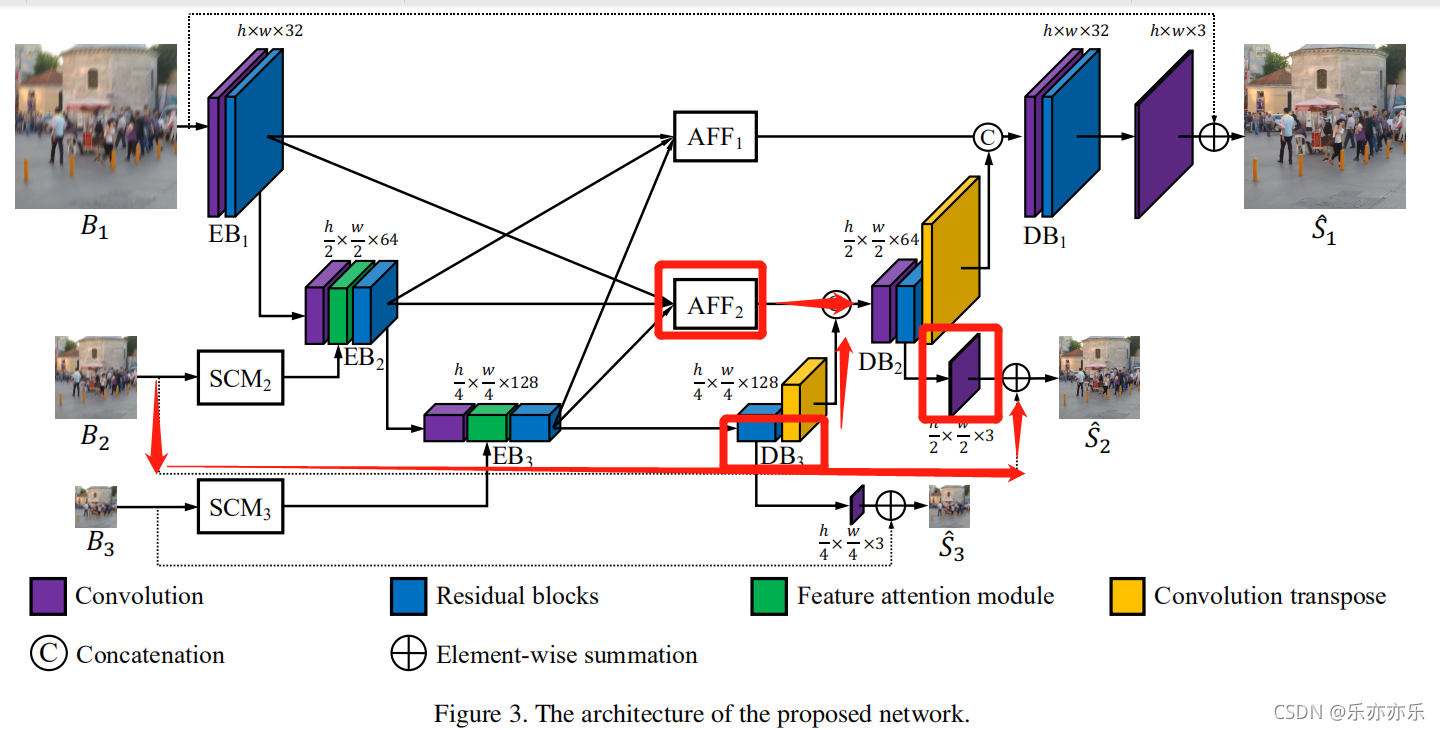
所提出的方法如图3所示,MIMO-UNet的编码器和解码器由三个编码器块(EB)和解码器块(DB)组成。
Multi-input single encoder
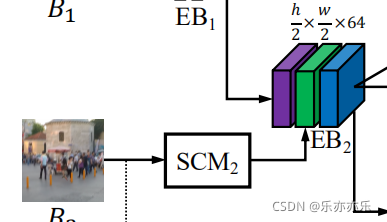
已经证明,从多尺度图像可以更好地处理图像中不同层次的模糊 。在MIMO-UNet中,不是子网络,而是EB以不同尺度的模糊图像作为输入。换句话说,除了从上述EB中提取的缩小特征外,还从降采样的模糊图像(如图B2,B3)中提取该特征,然后将这两个特征结合起来。
通过利用缩小特征的互补信息和降采样图像获得的特征,EB有望有效地处理不同的图像模糊。使用多尺度图像作为单个U-Net的输入也被证明在其他任务中是有效的,如深度地图超分辨率和对象检测。
图4,网络中所用到的模块结构!
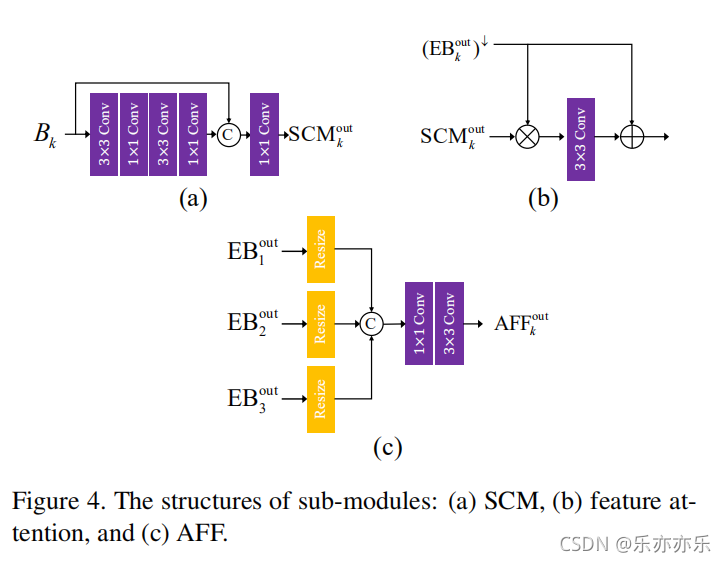
首先使用一个浅层卷积模块(SCM)从下采样图像中提取特征,如图4(a)所示。考虑到效率,使用了两个3×3和1×1的卷积层堆叠。将最后一个1×1层的特征与输入Bk连接起来,并使用额外的1×1卷积层进一步细化连接起来的特征。
具体代码:(其中BasicConv与ResBlock 可参考后文layers.py)
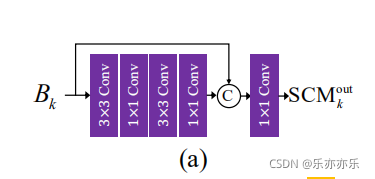
# Figure 4 (a) SCM 模块
class SCM(nn.Module):
def __init__(self, out_plane):
super(SCM, self).__init__()
self.main = nn.Sequential(
BasicConv(3, out_plane//4, kernel_size=3, stride=1, relu=True),
BasicConv(out_plane // 4, out_plane // 2, kernel_size=1, stride=1, relu=True),
BasicConv(out_plane // 2, out_plane // 2, kernel_size=3, stride=1, relu=True),
BasicConv(out_plane // 2, out_plane-3, kernel_size=1, stride=1, relu=True)
)
self.conv = BasicConv(out_plane, out_plane, kernel_size=1, stride=1, relu=False)
def forward(self, x):
x = torch.cat([x, self.main(x)], dim=1)
return self.conv(x)利用一个特征注意模块(FAM)来积极地强调或抑制先前尺度上的特征,并从SCM中学习特征的空间/通道重要性。如图4(b)所示。
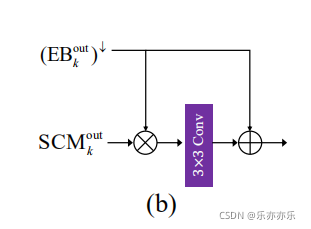
具体代码:(其中BasicConv与ResBlock 可参考后文layers.py)
# Figure 4 (b) feature attention
class FAM(nn.Module):
def __init__(self, channel):
super(FAM, self).__init__()
self.merge = BasicConv(channel, channel, kernel_size=3, stride=1, relu=False)
def forward(self, x1, x2):
x = x1 * x2
out = x1 + self.merge(x)
return outMulti-output single decoder
在MIMO-UNet中,不同的DBs具有不同大小的特征图。作者认为这些多尺度的特征图可以用于模拟多堆叠的子网络。与传统的子网络从粗到细网络的中间监督不同,将中间监督应用于每个DB。
具体表现形式:
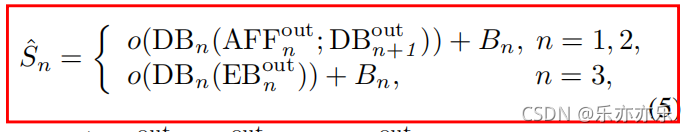
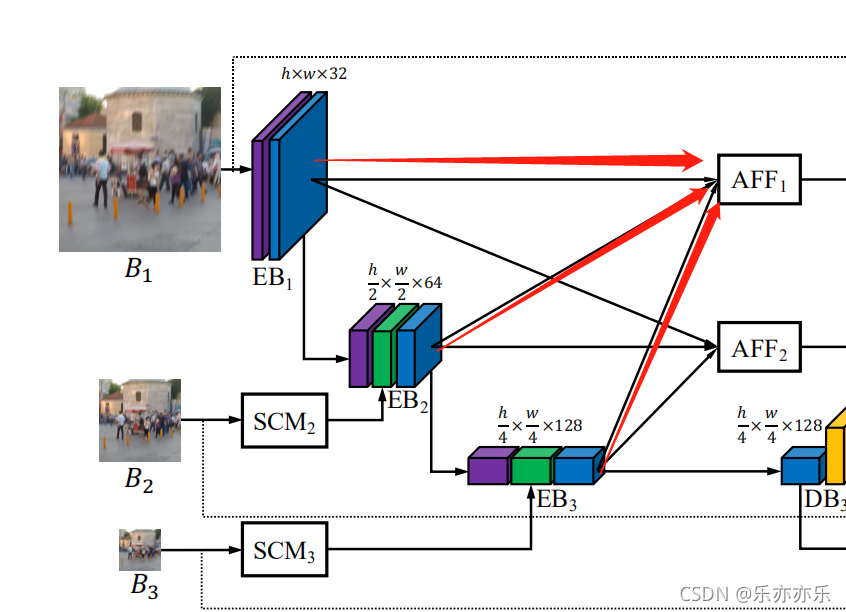
由于DB的输出是特征图而不是图像,因此映射函数o是生成中间输出图像所必需的,其中使用单个卷积层。公式表示如下图红色箭头所示。
Asymmetric feature fusion
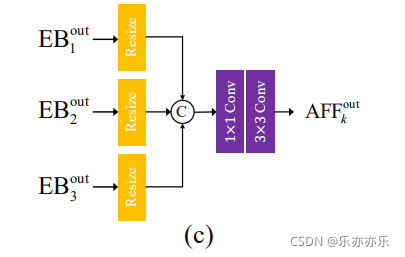
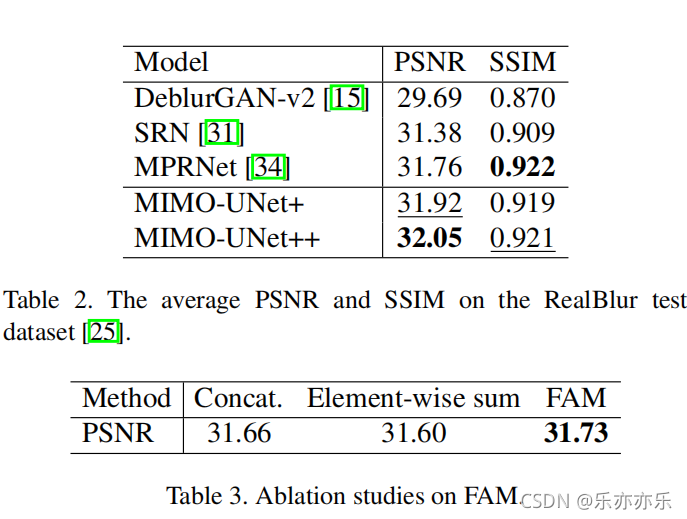
在大多数传统的粗到细的图像去模糊网络中,只有来自较粗尺度的子网络的特征被用于较细尺度的子网络,使得信息流不灵活。一种特殊的方法是将整个网络按水平或垂直方向级联,允许从上到下和从下到上的信息流。受尺度内特征(intra-scale)之间的紧密连接的启发,我们提出了一个非对称特征融合(AFF)模块,如图4(c)所示,以允许在单个U-Net内进行来自不同尺度的信息流。每个AFF将所有EB的输出作为输入,并使用卷积层结合多尺度特征。
具体表现形式如公式6:

具体代码:(其中BasicConv与ResBlock 可参考后文layers.py)
# AFF模块 论文中Figure 4(c)
class AFF(nn.Module):
def __init__(self, in_channel, out_channel):
super(AFF, self).__init__()
self.conv = nn.Sequential(
BasicConv(in_channel, out_channel, kernel_size=1, stride=1, relu=True),
BasicConv(out_channel, out_channel, kernel_size=3, stride=1, relu=False)
)
def forward(self, x1, x2, x4):
x = torch.cat([x1, x2, x4], dim=1)
return self.conv(x)Loss function: L1 loss
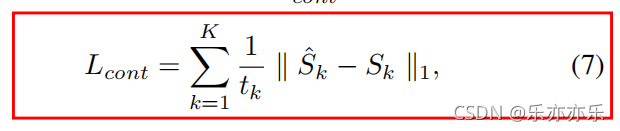
criterion = torch.nn.L1Loss()
train.py 训练代码
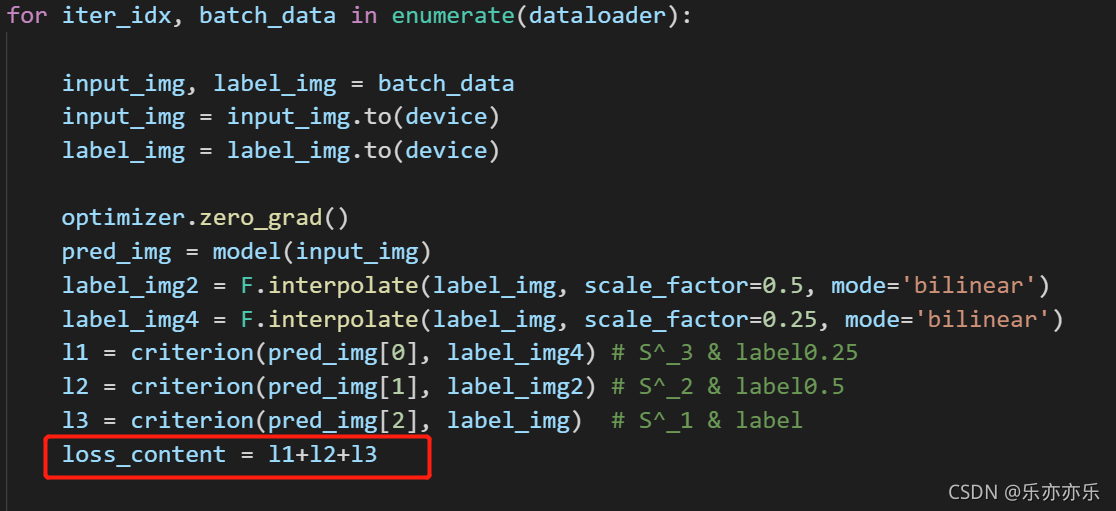
最近的研究也表明,除了性能改进的内容损失之外的辅助损失项。在图像增强和恢复任务中,尽量减少特征空间中输入和输出之间距离的辅助损失项已被广泛使用,并显示出有效的结果。
由于去模糊的目的是恢复丢失的高频分量,因此减少频率空间的差异是至关重要的。为此,文章提出了多尺度频率重建(MSFR)损失函数。

其中公式8、9对应代码:
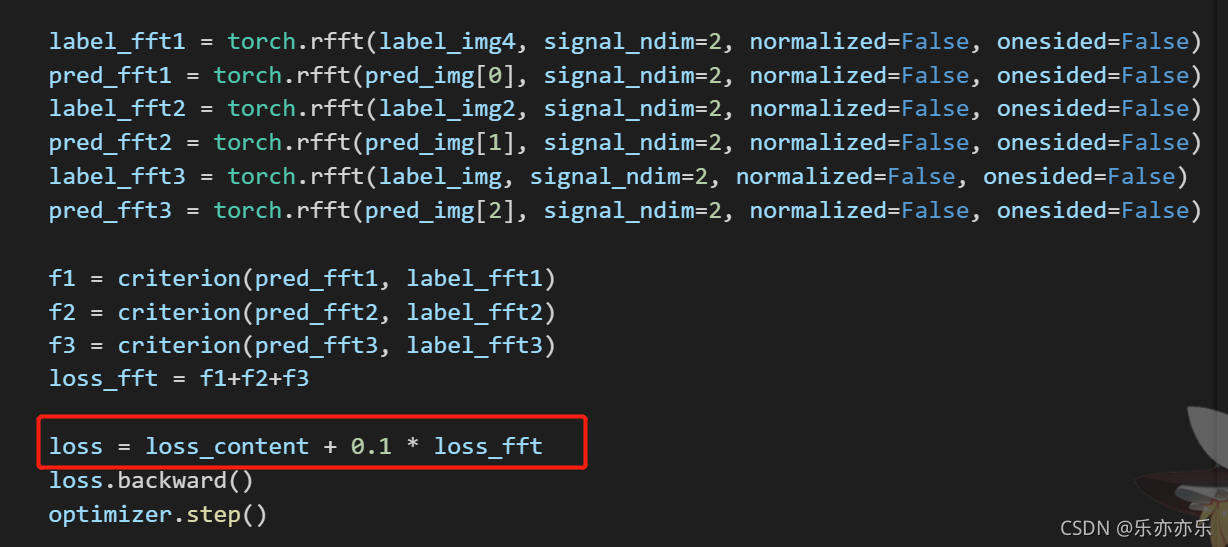
MIMO-UNet网络代码:(注释对应论文图中所标)
class MIMOUNet(nn.Module):
def __init__(self, num_res=8):
super(MIMOUNet, self).__init__()
base_channel = 32
self.Encoder = nn.ModuleList([
EBlock(base_channel, num_res),
EBlock(base_channel*2, num_res),
EBlock(base_channel*4, num_res),
])
self.feat_extract = nn.ModuleList([
BasicConv(3, base_channel, kernel_size=3, relu=True, stride=1),
BasicConv(base_channel, base_channel*2, kernel_size=3, relu=True, stride=2),
BasicConv(base_channel*2, base_channel*4, kernel_size=3, relu=True, stride=2),
BasicConv(base_channel*4, base_channel*2, kernel_size=4, relu=True, stride=2, transpose=True),
BasicConv(base_channel*2, base_channel, kernel_size=4, relu=True, stride=2, transpose=True),
BasicConv(base_channel, 3, kernel_size=3, relu=False, stride=1)
])
self.Decoder = nn.ModuleList([
DBlock(base_channel * 4, num_res),
DBlock(base_channel * 2, num_res),
DBlock(base_channel, num_res)
])
self.Convs = nn.ModuleList([
BasicConv(base_channel * 4, base_channel * 2, kernel_size=1, relu=True, stride=1),
BasicConv(base_channel * 2, base_channel, kernel_size=1, relu=True, stride=1),
])
self.ConvsOut = nn.ModuleList(
[
BasicConv(base_channel * 4, 3, kernel_size=3, relu=False, stride=1),
BasicConv(base_channel * 2, 3, kernel_size=3, relu=False, stride=1),
]
)
self.AFFs = nn.ModuleList([
AFF(base_channel * 7, base_channel*1),
AFF(base_channel * 7, base_channel*2)
])
self.FAM1 = FAM(base_channel * 4)
self.SCM1 = SCM(base_channel * 4)
self.FAM2 = FAM(base_channel * 2)
self.SCM2 = SCM(base_channel * 2)
def forward(self, x):
x_2 = F.interpolate(x, scale_factor=0.5) # 下采样B2
x_4 = F.interpolate(x_2, scale_factor=0.5) # 下采样B3
z2 = self.SCM2(x_2) # B2 通过SCM_2
z4 = self.SCM1(x_4) # B3通过SCM_3
outputs = list()
x_ = self.feat_extract[0](x) # Conv3x3
res1 = self.Encoder[0](x_) # 编码 EB1
z = self.feat_extract[1](res1) # Conv3x3
z = self.FAM2(z, z2) # SCM_2 在EB2 前进行融合
res2 = self.Encoder[1](z) # EB2
z = self.feat_extract[2](res2) # Conv3x3
z = self.FAM1(z, z4) # SCM_3 在EB3 前进行融合
z = self.Encoder[2](z) # EB3
z12 = F.interpolate(res1, scale_factor=0.5) # 下采样到AFF2
z21 = F.interpolate(res2, scale_factor=2) # 上采样到AFF1
z42 = F.interpolate(z, scale_factor=2) # 上采样到AFF2
z41 = F.interpolate(z42, scale_factor=2) # 上采样到AFF1
res2 = self.AFFs[1](z12, res2, z42) # AFF_2 融合
res1 = self.AFFs[0](res1, z21, z41) # AFF_1 融合
z = self.Decoder[0](z) # DB3
z_ = self.ConvsOut[0](z) # 通过卷积生成h/4 x w/4 x 3的特征图
z = self.feat_extract[3](z) # ConvTranspose 4x4 转置卷积
outputs.append(z_+x_4) # B3 + h/4 x w/4 x 3 ==> S^_3 (Element-wise summation)
z = torch.cat([z, res2], dim=1)
z = self.Convs[0](z) # Conv1x1
z = self.Decoder[1](z) # DB2
z_ = self.ConvsOut[1](z) # 通过卷积生成h/2 x w/2 x 3 的特征图
z = self.feat_extract[4](z) # ConvTranspose 4x4 转置卷积
outputs.append(z_+x_2) # B2 + h/2 x w/2 x 3 ==> S^_2 (Element-wise summation)
z = torch.cat([z, res1], dim=1)
z = self.Convs[1](z) # conv 1x1
z = self.Decoder[2](z) # DB1
z = self.feat_extract[5](z) # 通过conv3x3 生成 hxwx3
outputs.append(z+x) # B1 + h x w x 3 ==> S^_1
return outputs # 返回S^_3 S^_2 S^_1
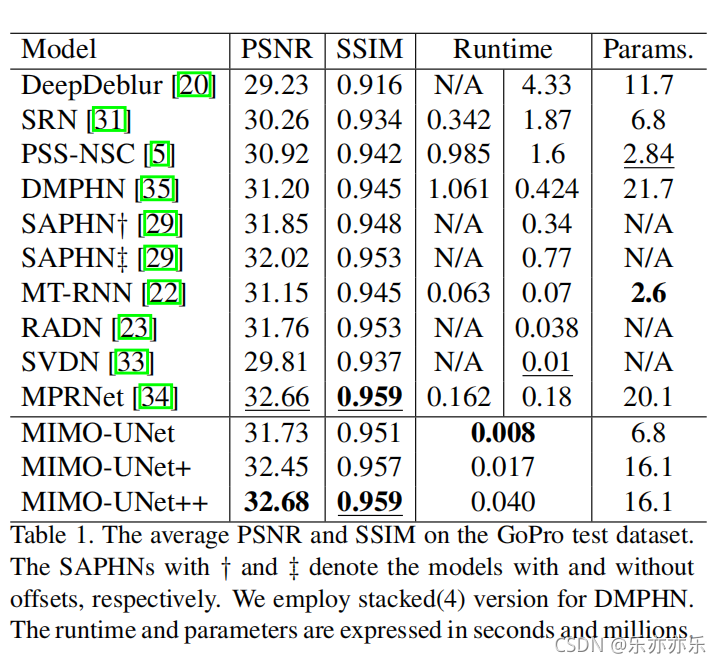
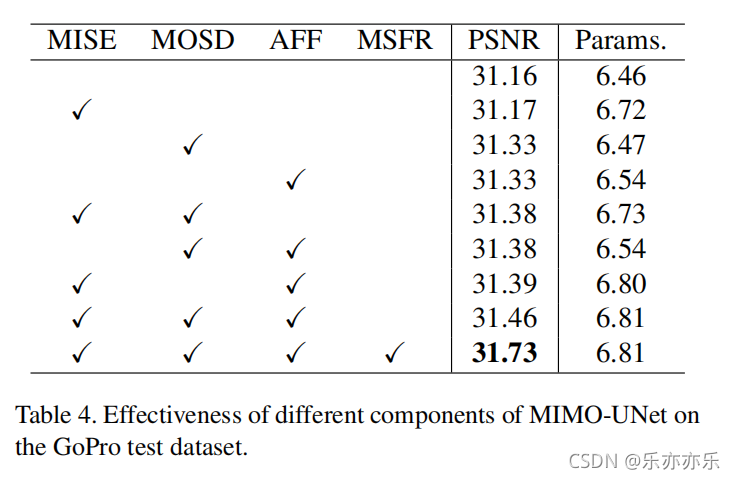
实验结果:
layers.py
import torch
import torch.nn as nn
# Conv2d -> BN -> ReLU or ConvTranspose2d -> BN ->ReLU
class BasicConv(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size, stride, bias=True, norm=False, relu=True, transpose=False):
super(BasicConv, self).__init__()
if bias and norm:
bias = False
padding = kernel_size // 2
layers = list()
if transpose:
padding = kernel_size // 2 -1
layers.append(nn.ConvTranspose2d(in_channel, out_channel, kernel_size, padding=padding, stride=stride, bias=bias))
else:
layers.append(
nn.Conv2d(in_channel, out_channel, kernel_size, padding=padding, stride=stride, bias=bias))
if norm:
layers.append(nn.BatchNorm2d(out_channel))
if relu:
layers.append(nn.ReLU(inplace=True))
self.main = nn.Sequential(*layers)
def forward(self, x):
return self.main(x)
# 残差块
class ResBlock(nn.Module):
def __init__(self, in_channel, out_channel):
super(ResBlock, self).__init__()
self.main = nn.Sequential(
BasicConv(in_channel, out_channel, kernel_size=3, stride=1, relu=True),
BasicConv(out_channel, out_channel, kernel_size=3, stride=1, relu=False)
)
def forward(self, x):
return self.main(x) + x


















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











