







论文地址:

Abstract
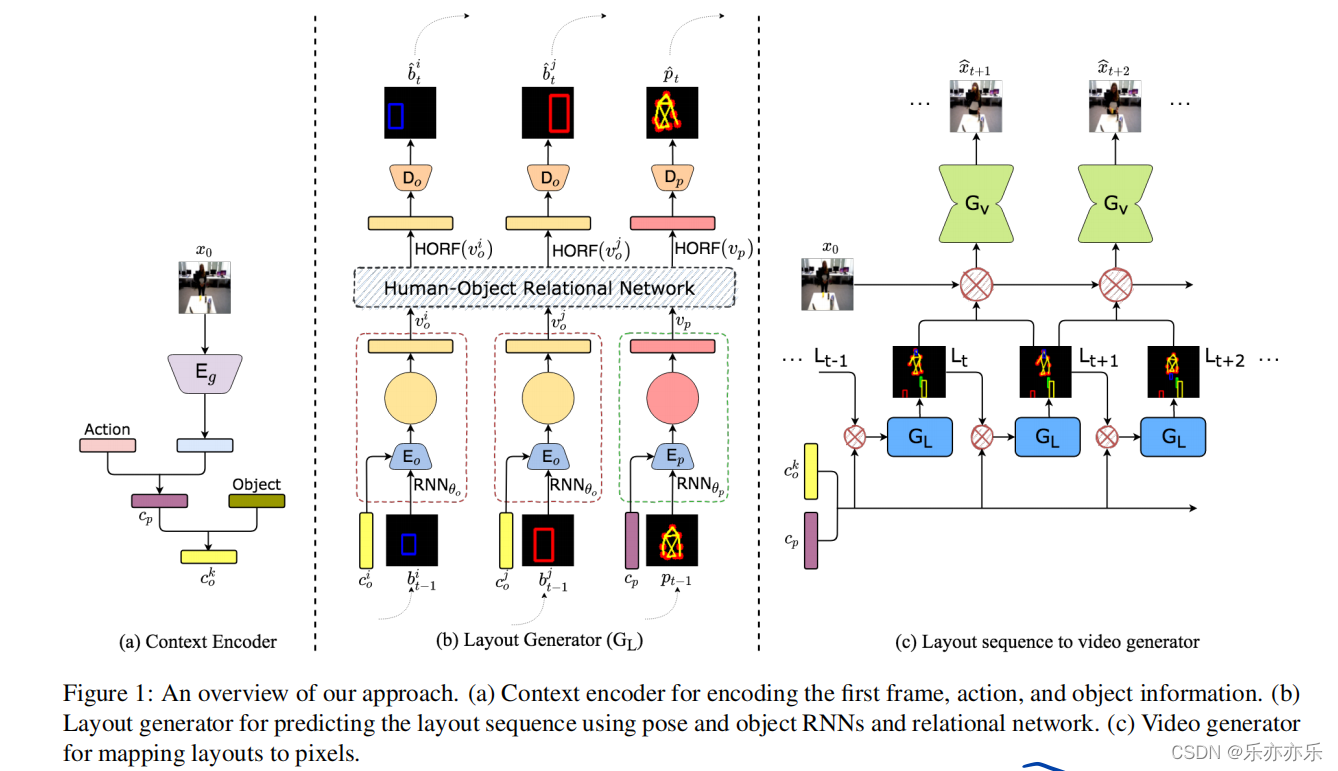
学习建模和预测人类在执行一个动作时如何与物体交互是一项具有挑战性的任务,而且大多数现有的视频预测模型在建模复杂的人-物体交互方面都是无效的。这篇工作建立在分层视频预测模型之上,该模型将视频生成过程分为两个阶:预测一个高级表示,如姿态序列,然后学习一个姿态到像素的转换模型进行像素生成。人-对象交互任务的动作序列通常非常复杂,涉及姿势、人的外观、物体位置和物体外观随时间的演变。为此,作者提出了一个使用关系布局的分层视频预测模型。
在第一阶段,学习预测一系列的布局。布局是视频的高级表示,其中包含每一帧的姿态和对象的信息。通过利用关系推理和递归神经网络对姿态和对象之间的关系进行建模来学习布局序列。在第二阶段之前,布局序列作为一个强结构,学习将布局映射到像素空间。方法在两个数据集,UMD-Hoi和Bimanual上的实验评估显示,在标准视频评估指标,如LPIPS、PSNR和SSIM方面有显著的改进。
Introduction
视频预测是一项具有挑战性的任务,即预测未来的帧,条件是基于一个或多个过去的帧。在现实世界中的视频是非常复杂的。日常活动,比如喝咖啡,是各种物体之间复杂互动的结果。例如,首先,这个人可能会到达咖啡壶前,把咖啡倒进他们的杯子里。接下来,他们可能会在浏览手机时开始用杯子喝。这个特定的动作涉及到各种对象之间的相互作用,例如咖啡壶、杯子和手机。每个物体相对于其他物体和执行该动作的人都有其相对的运动。虽然人类可以很不费力地想象这样的事件,但现有的计算机视觉模型经常在这些任务上失败。
现有的视频预测方法大致可分为两类:
- 模型是一种可以在像素空间中直接预测视频的模型
- 使用层次结构预测的模型。层次预测方法比直接预测像素空间中的视频更可取,因为它们学习了一个很好的中间表示,然后映射到像素空间。
将预测分解为更简单的步骤,有助于模型专注于更小的任务,从而学习一个改进的帧预测模型。视频中间表示的一种自然选择是光流[1]。类似地,对于涉及人类行为的视频,人体姿态通常被用作中间表示。
虽然姿势对于涉及人类动作的视频是一个很好的选择,但姿势并不足以捕捉人机交互序列中的各种动态。对于复杂的动作,比如人-物体交互,多个物体随着时间的推移而进化,姿态单独并不能完全捕捉复杂的场景动态。由于姿态不包含任何关于对象的信息,模型不能很好地捕捉对象的运动和外观。为了缓解这个问题,作者提出学习一个布局序列作为中间表示。布局序列是姿势和对象序列的组合,它不仅在执行动作时捕捉人的姿势,而且还明确地学习动作时在不同时间学习不同对象的位置。独立学习这些姿态和物体序列的简单方法也是不够的,因为物体的时空进化依赖于姿态的进化方式,反之亦然。因此,作者提出了一个人-物体关系网络(Human-Object Relational Network,HORN)来建模这些物体和姿态之间的复杂的相互作用。
主要贡献:
- 建模了人类的全身运动
- 中间表示捕获了姿态和对象的位置,从而在帧预测阶段学习了更好的结构
- 模型可以为新的交互生成视频
Related Work
视频预测Video Prediction
之前的工作直接生成预测的视频,本文不同之处在于,使用分层的模型,首先在第一阶段生成一个结构,作为第二阶段的先验。姿态本身并不足以捕获良好的结构先验,作者使用了姿态序列和对象序列组合的布局序列。
人物交互HOI
建模人类全身运动
关系推理Relational Reasoning
这项工作是第一次在现实世界视频的视频预测中使用关系推理。因为该任务涉及建模人-对象交互,这反过来涉及跨实体的推理,如人和对象和物和物,关系推理是进行布局生成的第一阶段的自然选择。


















 5537
5537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











