







1. 数据结构的定义
table的定义
typedef struct Table {
CommonHeader;
lu_byte flags; //是否存在元方法
lu_byte lsizenode; //hash部分的大小(这个值是以2为底的对数值)
unsigned int alimit; //数组大小
TValue *array; //数组部分
Node *node; //hash部分
Node *lastfree; //指向hash部分最后一个未使用的节点
struct Table *metatable;//元表
GCObject *gclist;
} Table;
hash节点的定义
typedef union Node {
struct NodeKey {
TValuefields; //value
lu_byte key_tt; //key的类型
int next; //next指针(保存下一个节点相对于本节点的位置)
Value key_val; //key value
} u;
TValue i_val; //value
} Node;
快捷访问宏
#define gval(n) (&(n)->i_val) //获取node的value
#define gnext(n) ((n)->u.next) //next指针
2. 存储方式
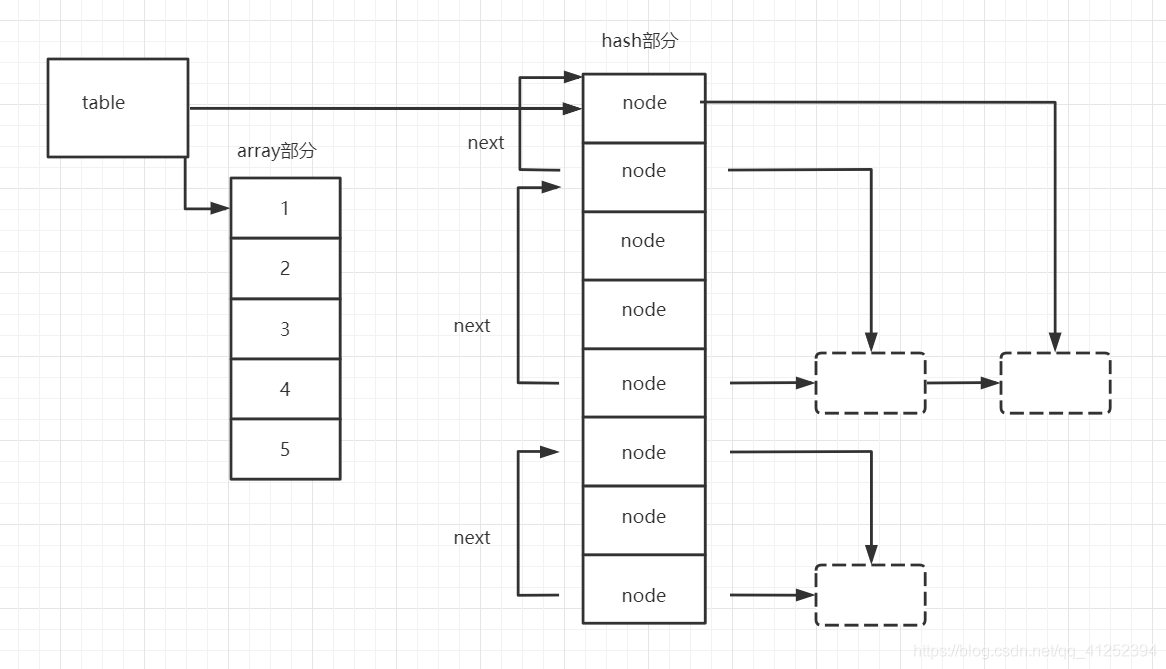
table中有两个存储部分,数组部分和hash部分。在插入整数类型的key时优先选择的是数组部分。hash部分本质也是一个数组,区别于字符串hash表的实现,table中的hash表使用的节点都是预先分配好的,不会插入时去申请内存,直到这个数组中的元素全部使用完,才会去扩容。正是以为如此node中的next指针是一个int类型,这个值表示的是下一个节点相对于本节点位置。
为什么hash部分不使用之前字符串hash表中存储方式?
个人认为这样子更方便去遍历table,这样子实现意味着只要遍历两个数组就可以遍历整个hash表
3. 实现
3.1 hash
//两种取余运算 (&上(size-1) 或者是 % )
#define lmod(s,size) \
(check_exp((size&(size-1))==0, (cast_int((s) & ((size)-1)))))
#define hashpow2(t,n) (gnode(t, lmod((n), sizenode(t))))
#define hashmod(t,n) (gnode(t, ((n) % ((sizenode(t)-1)|1))))
//字符串 hash
#define hashstr(t,str) hashpow2(t, (str)->hash)
//bool hash
#define hashboolean(t,p) hashpow2(t, p)
//int hash
#define hashint(t,i) hashpow2(t, i)
//地址hash
#define hashpointer(t,p) hashmod(t, point2uint(p))
//float hash算法
static int l_hashfloat (lua_Number n) {
int i;
lua_Integer ni;
n = l_mathop(frexp)(n, &i) * -cast_num(INT_MIN);
if (!lua_numbertointeger(n, &ni)) { /* is 'n' inf/-inf/NaN? */
lua_assert(luai_numisnan(n) || l_mathop(fabs)(n) == cast_num(HUGE_VAL));
return 0;
}
else { /* normal case */
unsigned int u = cast_uint(i) + cast_uint(ni);
return cast_int(u <= cast_uint(INT_MAX) ? u : ~u);
}
}
各个类型的hash算法
static Node *mainposition (const Table *t, int ktt, const Value *kvl) {
switch (withvariant(ktt)) {
case LUA_VNUMINT: {//int
lua_Integer key = ivalueraw(*kvl);
return hashint(t, key);
}
case LUA_VNUMFLT: {//float
lua_Number n = fltvalueraw(*kvl);
return hashmod(t, l_hashfloat(n));
}
//string
case LUA_VSHRSTR: {
TString *ts = tsvalueraw(*kvl);
return hashstr(t, ts);
}
case LUA_VLNGSTR: {
TString *ts = tsvalueraw(*kvl);
return hashpow2(t, luaS_hashlongstr(ts));
}
//bool
case LUA_VFALSE:
return hashboolean(t, 0);
case LUA_VTRUE:
return hashboolean(t, 1);
//下面三个都是使用地址作为hash值
case LUA_VLIGHTUSERDATA: {
void *p = pvalueraw(*kvl);
return hashpointer(t, p);
}
case LUA_VLCF: {
lua_CFunction f = fvalueraw(*kvl);
return hashpointer(t, f);
}
default: {
GCObject *o = gcvalueraw(*kvl);
return hashpointer(t, o);
}
}
}
这个函数用于集合各个类型的hash函数,返回对应的节点
3.2 创建
3.2.1 创建空表
Table *luaH_new (lua_State *L) {
//new sizeof(Table)
GCObject *o = luaC_newobj(L, LUA_VTABLE, sizeof(Table));
Table *t = gco2t(o);
t->metatable = NULL;
t->flags = cast_byte(maskflags); //这个值表示没有元方法
t->array = NULL;
t->alimit = 0;
setnodevector(L, t, 0); //初始化hash部分
return t;
}
前面两句类似于 Table *t = sizeof(sizeof(Table)) ,这么做只是由于lua中有gc机制,需要做一下gc相关的操作
static void setnodevector (lua_State *L, Table *t, unsigned int size) {
if (size == 0) { /* no elements to hash part? */
t->node = cast(Node *, dummynode); /* use common 'dummynode' */
t->lsizenode = 0;
t->lastfree = NULL; /* signal that it is using dummy node */
}
...
}
dummynode 类似于哨兵节点,和NULL意思差不多
Table大多成员初始化都为0
3.2.2 空间分配
void luaH_resize (lua_State *L, Table *t, unsigned int newasize,
unsigned int nhsize) {
unsigned int i;
Table newt;
unsigned int oldasize = setlimittosize(t);
TValue *newarray;
setnodevector(L, &newt, nhsize);//申请新的hash部分内存
...
newarray = luaM_reallocvector(L, t->array, oldasize, newasize, TValue);//realloc 数组部分的内存
...
t->array = newarray; //更新数组部分,
t->alimit = newasize;
for (i = oldasize; i < newasize; i++) //把数组部分扩容的部分初始化
setempty(&t->array[i]);
...
}
static void setnodevector (lua_State *L, Table *t, unsigned int size) {
if (size == 0) { /* no elements to hash part? */
...
}
else {
int i;
int lsize = luaO_ceillog2(size); //取以2为低的对数(向上取整的方式)
if (lsize > MAXHBITS || (1u << lsize) > MAXHSIZE)
luaG_runerror(L, "table overflow");
size = twoto(lsize); //2^lsize
t->node = luaM_newvector(L, size, Node);//申请 (sizeof(Node) * size) 的内存
for (i = 0; i < (int)size; i++) { //初始化node数组
Node *n = gnode(t, i);
gnext(n) = 0;
setnilkey(n);
setempty(gval(n));
}
t->lsizenode = cast_byte(lsize); //保存以2为低的对数值(用于表示node的大小)
t->lastfree = gnode(t, size); //指向最后一个node节点
}
}
空间分配直接调用luaH_resize函数, newasize为数组部分的大小,nhsize为hash部分的大小
3.3 获取
const TValue *luaH_get (Table *t, const TValue *key) {
switch (ttypetag(key)) {
case LUA_VSHRSTR: return luaH_getshortstr(t, tsvalue(key));
case LUA_VNUMINT: return luaH_getint(t, ivalue(key));
case LUA_VNIL: return &absentkey;
case LUA_VNUMFLT: {//转换为int,如果失败会去default
lua_Integer k;
if (luaV_flttointeger(fltvalue(key), &k, F2Ieq)) //尝试转换成int,如果有小数会转换失败
return luaH_getint(t, k); /* use specialized version */
/* else... */
} /* FALLTHROUGH */
default:
return getgeneric(t, key, 0);
}
}
table获取值的总入口,根据key的类型去使用不同类型的hash方法,
string
const TValue *luaH_getshortstr (Table *t, TString *key) {
Node *n = hashstr(t, key); //找到对应的槽
lua_assert(key->tt == LUA_VSHRSTR);
for (;;) { //查找key(遍历链表)
if (keyisshrstr(n) && eqshrstr(keystrval(n), key))//比较
return gval(n); /* that's it */
else { //next
int nx = gnext(n);
if (nx == 0)
return &absentkey; /* not found */
n += nx;
}
}
}
int
const TValue *luaH_getint (Table *t, lua_Integer key) {
if (l_castS2U(key) - 1u < t->alimit) //如果这个key 在 1到t->alimit之间,是数组部分的key
return &t->array[key - 1];
else if (!limitequalsasize(t) && /* key still may be in the array part? */
(l_castS2U(key) == t->alimit + 1 ||
l_castS2U(key) - 1u < luaH_realasize(t))) {
t->alimit = cast_uint(key); /* probably '#t' is here now */
return &t->array[key - 1];
}
else {
Node *n = hashint(t, key); //找到对应的槽
for (;;) { //查找key(遍历链表)
if (keyisinteger(n) && keyival(n) == key)//比较
return gval(n); /* that's it */
else {//next
int nx = gnext(n);
if (nx == 0) break;
n += nx;
}
}
return &absentkey;
}
}
默认的方法
static const TValue *getgeneric (Table *t, const TValue *key, int deadok) {
Node *n = mainpositionTV(t, key);
for (;;) { /* check whether 'key' is somewhere in the chain */
if (equalkey(key, n, deadok))
return gval(n); /* that's it */
else {
int nx = gnext(n);
if (nx == 0)
return &absentkey; /* not found */
n += nx;
}
}
}
可以看到三个方法的算法是类似的
- 使用hash算法得到node头
- 查找这个key,找到返回,没找到返回哨兵节点
3.4 添加
void luaH_finishset (lua_State *L, Table *t, const TValue *key,
const TValue *slot, TValue *value) {
if (isabstkey(slot)) //这个key不存在
luaH_newkey(L, t, key, value);
else //存在直接设置值
setobj2t(L, cast(TValue *, slot), value);
}
void luaH_set (lua_State *L, Table *t, const TValue *key, TValue *value) {
const TValue *slot = luaH_get(t, key);//获取这个key
luaH_finishset(L, t, key, slot, value);
}
luaH_set 这个是添加key的入口,实现主逻辑也相对简单
- 使用luaH_get 获取这个key对应的node
- 如果这个key不存在就创建,存在则重新赋值
3.4.1 创建key
void luaH_newkey (lua_State *L, Table *t, const TValue *key, TValue *value) {
Node *mp;
TValue aux;
if (l_unlikely(ttisnil(key)))//判空
luaG_runerror(L, "table index is nil");
else if (ttisfloat(key)) {//如果是float
lua_Number f = fltvalue(key);
lua_Integer k;
if (luaV_flttointeger(f, &k, F2Ieq)) { //把float尝试转换成int,使用F2Ieq这个值,如果float有小数转换会失败
setivalue(&aux, k);
key = &aux; /* insert it as an integer */
}
else if (l_unlikely(luai_numisnan(f)))//转换失败
luaG_runerror(L, "table index is NaN");
}
if (ttisnil(value))
return; /* do not insert nil values */
mp = mainpositionTV(t, key);//hash,返回对应的槽
if (!isempty(gval(mp)) || isdummy(t)) { //如果table是空的,或者当前位置已经被使用
Node *othern;
Node *f = getfreepos(t); //获取一个未被使用的node
if (f == NULL) { //表示node都已经使用完
rehash(L, t, key); //调整table
/* whatever called 'newkey' takes care of TM cache */
luaH_set(L, t, key, value); /* insert key into grown table */
return;
}
lua_assert(!isdummy(t));
othern = mainposition(t, keytt(mp), &keyval(mp));//找到这个node的hash头
if (othern != mp) { //如果这个node不是本身,说明这个节点已经变为别的节点的链表节点
//用一个为使用的节点替换
while (othern + gnext(othern) != mp) //找到node在这个槽的位置
othern += gnext(othern);
gnext(othern) = cast_int(f - othern); //node的前一个节点指向新的节点
*f = *mp; //节点值拷贝
if (gnext(mp) != 0) {//如果node还有后续节点
gnext(f) += cast_int(mp - f); //更新next指向
gnext(mp) = 0; /* now 'mp' is free */
}
setempty(gval(mp));
}
else { //如果这个node是头
//插入未使用的节点
if (gnext(mp) != 0)//如果node有后续链表
gnext(f) = cast_int((mp + gnext(mp)) - f); //新节点指向后续节点
else lua_assert(gnext(f) == 0);
gnext(mp) = cast_int(f - mp);//当前节点指向新节点(头插法完成)
mp = f;//更新mp,用于函数的默认处理
}
}
setnodekey(L, mp, key);//赋值key
luaC_barrierback(L, obj2gco(t), key);
lua_assert(isempty(gval(mp)));
setobj2t(L, gval(mp), value);//赋值value
}
这个函数是table中最重要的函数之一,是hash表的实现逻辑
- 使用mainpositionTV获取这个key散列的位置
- 如果这个位置没有被使用,直接赋值
- 如果这个位置已经被使用
- 使用的这个节点,hash(key)是本身,说明这个节点是头节点,只需要找到一个未使用的节点插入。
- 使用的这个节点hash(key)不是本身,说明这个节点已经成为别的节点的链表节点,后续的操作就是找一个未使用的节点替换当前节点
3.4.2 rehash
static void rehash (lua_State *L, Table *t, const TValue *ek) {
unsigned int asize; //数组部分的大小
unsigned int na; //当前表中所有的int key
unsigned int nums[MAXABITS + 1];
int i;
int totaluse;//统计所有的已经使用的key
for (i = 0; i <= MAXABITS; i++) nums[i] = 0; /* reset counts */
setlimittosize(t);
na = numusearray(t, nums); //统计key在 (2^(i - 1),2^i]的数量输出在nums[i],返回int key的数量
totaluse = na;
totaluse += numusehash(t, nums, &na); //na+=hash部分的int key
/* count extra key */
if (ttisinteger(ek)) //如果新的key是int
na += countint(ivalue(ek), nums);
totaluse++;
/* compute new size for array part */
asize = computesizes(nums, &na); //计算数组部分的大小.na返回的当数组部分大小为asize时,使用int key的数量
//重新设置数组部分和hash部分的大小
luaH_resize(L, t, asize, totaluse - na);//totaluse - na all_key - 新数组部分int key的数量
}
1.遍历所有key,把int key输出在nums数组中。数组每个元素都是用于计算,统计(2^(i - 1),2^i]的数量
2.na变量用于记录所有的int key的数量,totaluse用于记录所有已使用的key。
3.最后通过computesizes去计算数组部分的大小。计算完一个之后hash部分就是totaluse - 新数组部分int key的数量
computesizes函数的实现
static unsigned int computesizes (unsigned int nums[], unsigned int *pna) {
int i;
unsigned int twotoi; /* 2^i (candidate for optimal size) */
unsigned int a = 0; /* number of elements smaller than 2^i */
unsigned int na = 0; /* number of elements to go to array part */
unsigned int optimal = 0; /* optimal size for array part */
/* loop while keys can fill more than half of total size */
for (i = 0, twotoi = 1;
twotoi > 0 && *pna > twotoi / 2;
i++, twotoi *= 2) {
a += nums[i];
if (a > twotoi/2) { //两倍关系
optimal = twotoi; /* optimal size (till now) */
na = a; /* all elements up to 'optimal' will go to array part */
}
}
lua_assert((optimal == 0 || optimal / 2 < na) && na <= optimal);
*pna = na; //返回新数组部分key的数量
return optimal; //新数组部分的大小
}
可以看到循环中有一个很显眼的比较。说明使用数量和空间数量是尽量满足两倍的关系
luaH_resize的实现
void luaH_resize (lua_State *L, Table *t, unsigned int newasize,
unsigned int nhsize) {
unsigned int i;
Table newt; /* to keep the new hash part */
unsigned int oldasize = setlimittosize(t);
TValue *newarray;
/* create new hash part with appropriate size into 'newt' */
setnodevector(L, &newt, nhsize);//申请新的hash部分内存
if (newasize < oldasize) { //如果数组部分有缩减
t->alimit = newasize; //先赋值为新的,后续使用luaH_setint函数时key不会在数组部分
exchangehashpart(t, &newt); //交换hash部分
//把数组部分多余的部分移到hash部分
for (i = newasize; i < oldasize; i++) {
if (!isempty(&t->array[i]))
luaH_setint(L, t, i + 1, &t->array[i]);
}
//恢复原来的状态
t->alimit = oldasize;
exchangehashpart(t, &newt);
}
/* allocate new array */
newarray = luaM_reallocvector(L, t->array, oldasize, newasize, TValue);//realloc 数组部分
if (l_unlikely(newarray == NULL && newasize > 0)) { /* allocation failed? */
freehash(L, &newt); /* release new hash part */
luaM_error(L); /* raise error (with array unchanged) */
}
/* allocation ok; initialize new part of the array */
exchangehashpart(t, &newt); /* 't' has the new hash ('newt' has the old) */
t->array = newarray; //更新数组部分,
t->alimit = newasize;
for (i = oldasize; i < newasize; i++) //把数组部分扩容的部分初始化
setempty(&t->array[i]);
/* re-insert elements from old hash part into new parts */
reinsert(L, &newt, t); //newt现在是老的hash表。把原来表的数据插入新表
freehash(L, &newt); //释放原来表的hash部分
}
1.如果数组部分缩容把越界的int key添加到新表hash部分
2.把老表的hash部分移到新表的hash部分中
注意:这个新版只是hash部分的。最后通过交换换调了老的hash部分的表
3.5 遍历
static unsigned int findindex (lua_State *L, Table *t, TValue *key,
unsigned int asize) {
unsigned int i;
if (ttisnil(key)) return 0; //如果是空,返回0,这个是遍历的起点
i = ttisinteger(key) ? arrayindex(ivalue(key)) : 0;
if (i - 1u < asize) //key 在数组部分
return i; /* yes; that's the index */
else {//key 在hash部分
const TValue *n = getgeneric(t, key, 1);
if (l_unlikely(isabstkey(n)))
luaG_runerror(L, "invalid key to 'next'"); /* key not found */
i = cast_int(nodefromval(n) - gnode(t, 0)); /* key index in hash table */
/* hash elements are numbered after array ones */
return (i + 1) + asize;
}
}
int luaH_next (lua_State *L, Table *t, StkId key) { //遍历
unsigned int asize = luaH_realasize(t);
unsigned int i = findindex(L, t, s2v(key), asize); //查找key
for (; i < asize; i++) { /* try first array part */
if (!isempty(&t->array[i])) { /* a non-empty entry? */
setivalue(s2v(key), i + 1);
setobj2s(L, key + 1, &t->array[i]);//value的值设置在key的下一个位置,意味着key必须是有两个元素的数组(一般使用lua栈)
return 1;
}
}
for (i -= asize; cast_int(i) < sizenode(t); i++) { /* hash part */
if (!isempty(gval(gnode(t, i)))) { /* a non-empty entry? */
Node *n = gnode(t, i);
getnodekey(L, s2v(key), n);
setobj2s(L, key + 1, gval(n)); //value的值设置在key的下一个位置,意味着key必须是有两个元素的数组(一般使用lua栈)
return 1;
}
}
return 0; /* no more elements */
}
luaH_next的使用要注意两点
- key必须是有两个元素的数组
- 最开始传入的是一个空值
4. table的使用
1.创建 include 、lib、src、bin目录
mkdir include lib src bin
2.将编译好的liblua.a放到lib、源码中的头文件放入include
mv luapath/src/liblua.a lib
mv luapath/src/*h include
3.在src目录创建table.c写入代码
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#include <lua.h>
#include <lualib.h>
#include <lauxlib.h>
#include <ltable.h>
#include <lstring.h>
#include <lobject.h>
static void PrintString(const TString* ts)
{
const char* s=getstr(ts);
size_t i,n=tsslen(ts);
printf("\"");
for (i=0; i<n; i++)
{
int c=(int)(unsigned char)s[i];
switch (c)
{
case '"':
printf("\\\"");
break;
case '\\':
printf("\\\\");
break;
case '\a':
printf("\\a");
break;
case '\b':
printf("\\b");
break;
case '\f':
printf("\\f");
break;
case '\n':
printf("\\n");
break;
case '\r':
printf("\\r");
break;
case '\t':
printf("\\t");
break;
case '\v':
printf("\\v");
break;
default:
if (isprint(c)) printf("%c",c); else printf("\\%03d",c);
break;
}
}
printf("\"");
}
static void print_value(const TValue *o)
{
switch (ttypetag(o))
{
case LUA_VNIL:
printf("nil");
break;
case LUA_VFALSE:
printf("false");
break;
case LUA_VTRUE:
printf("true");
break;
case LUA_VNUMFLT:
{
char buff[100];
sprintf(buff,LUA_NUMBER_FMT,fltvalue(o));
printf("%s",buff);
if (buff[strspn(buff,"-0123456789")]=='\0') printf(".0");
break;
}
case LUA_VNUMINT:
printf(LUA_INTEGER_FMT,ivalue(o));
break;
case LUA_VSHRSTR:
case LUA_VLNGSTR:
PrintString(tsvalue(o));
break;
default: /* cannot happen */
printf("?%d",ttypetag(o));
break;
}
}
struct kv_data
{
char *key;
int value;
};
static struct kv_data data[] = {
{"a",1},
{"b",2},
{"c",3},
{"d",4},
{"e",5},
{"f",6},
{"g",7},
{"h",8},
{"i",9},
{"j",10},
{"k",12},
{"l",13},
{"m",14},
{"n",15},
{"o",16},
{"p",17},
{NULL,-1},
};
int main(int argc,char *argv[])
{
lua_State *L = luaL_newstate(); //lua虚拟机
Table *t = luaH_new(L); //创建一个table
luaH_resize(L,t,3,4); //分配内存
TValue key,val;
//遍历添加
struct kv_data *it = data;
for(;it->key;it++) {
setsvalue(L, &key, luaS_new(L,it->key));
setivalue(&val, it->value);
luaH_set(L,t,&key,&val);
//setivalue(p, it->value);
}
//遍历输出
setnilvalue(s2v(L->top));
while(luaH_next(L,t,L->top)) {
//printf("%s %f\n",getstr(tsvalue(s2v(L->top))),nvalue(s2v(L->top+1)));
print_value(s2v(L->top));
printf("\t");
print_value(s2v(L->top+1));
printf("\n");
}
printf("sizeof(node) = %ld\n",sizeof(Node));
return 0;
}
4.Makefile编写
SRC=$(wildcard src/*.c)
SRC_OBJ=$(patsubst %.c,%.o,$(SRC))
OBJ=$(patsubst src%,obj%,$(SRC_OBJ))
SRC_OUT=$(patsubst %.c,%,$(SRC))
TARGET=$(patsubst src/%,%,$(SRC_OUT))
CC=gcc
CFLAGS=-g2 -gdwarf-2
LIBPATH=-L./lib
LIBS=-llua -lm -ldl
INCLUDE=-I./include
all:$(TARGET)
$(TARGET):%:src/%.c
$(CC) $(CFLAGS) -o bin/$@ $^ $(INCLUDE) $(LIBPATH) $(LIBS)
clean:
rm -rf $(OBJS) bin/*
test:
echo $(SRC) && echo $(OBJ)
- make
- cd /bin && ./table
这部分的源码注释可以参考本人的
github地址:https://github.com/huoyang11/read_lua
参考
<lua设计与实现> codedump
基于lua5.4.3源码














 7431
7431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









