







Logstash日志收集(三)
还是得先顺着官网了解一波:https://www.elastic.co/products/logstash
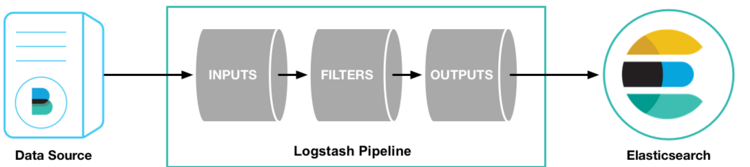
一、跟着官网学习下Logstash的基本概念
集中,转换和隐藏。您的数据Logstash是一个开源的服务器端数据处理管道,可以同时从多个源中获取数据,并将其转换为您喜欢的“存储”(自然是Elasticsearch)。)
1.1 Logstash 6.0.0新增功能
用多条管道简化处理:
Logstash 6.0引入了针对不同用例同时运行多个管道的能力。 管道在同一个实例中一起运行,但具有独立的输入,过滤器和输出,使用户能够隔离每个数据源的处理逻辑。 这使您的管道逻辑集中和简洁。
从历史上看,许多Logstash用户将多个用例组合成单个管道,这需要添加复杂的条件逻辑。 有了多个不再需要的管道, 现在,您可以更干净地组织您的配置,并通过使用每个用例的专用管道来更有效地执行您的管道。
为了增加趣味性,每个管道还有自己的独立设置和生命周期,您可以调整它们以匹配该数据源所需的相应工作负载配置文件。 例如,您可能希望为高容量日志记录管道分配更多的管道工作线程,并为较低强度的本地度量标准管道节流资源。多管道的官方文档:https://www.elastic.co/guide/en/logstash/6.0/multiple-pipelines.html
多管道的博客地址:https://www.elastic.co/blog/logstash-multiple-pipelines
用Elastic Stack集中管理管道:
在过去,管理pipeline配置或者是手动任务,或者使用像Puppet或Chef这样的配置管理工具来协助操作自动化。 在Logstash 6.0,集中管道管理功能现在使您能够通过Kibana单一窗格直接使用Elastic Stack管理和自动编排Logstash部署。
此功能为Kibana带来了管道管理UI,您可以使用它来创建,编辑和删除pipeline。 在这个UI下面,我们使用Elasticsearch来存储你的pipelines配置。 通过几个简单的设置,您的Logstash节点可以配置为监视这些管道上的变化,让您可以无缝地推出管道更改,而无需额外的运营基础架构。#集中管道管理可作为X-Pack功能使用。
#文档连接:https://www.elastic.co/guide/en/logstash/6.0/logstash-centralized-pipeline-management.html
可视化管道逻辑和性能:
Pipeline Viewer,这是对Logstash Monitoring UI的一个补充。 有了这个新工具,您可以看到您的管道配置,并排除插件级别的性能瓶颈。 管道查看器将Logstash管道显示为DAG(定向非循环图)。 在这个DAG上重叠是个别输入,过滤器和输出的相关性能指标。 突出显示潜在的性能问题,以便快速确定管道的哪些部分可能是瓶颈。
用户应该注意,这是一个测试版功能,可能会有所变化。 一个已知的问题是缺乏清晰渲染非常大的管道的能力。 这是一个积极的工作领域,所以当我们进一步改进并将其转化为全面可用性时,期待对此功能进行重大改进。从导入节点到Logstash的Smooth path:
一些用户在开始使用Elastic Stack时享受Elasticsearch摄取节点的便利。 但是,在一定程度的复杂性中,Ingest节点可能不具备解决您的问题所需的所有功能,并且可能需要迁移到Logstash。 为了简化这些转换,我们创建了一个随Logstash 6.0一起提供的Ingest管道转换工具。 转换器将一个接收节点管道作为输入,并将相应的Logstash管道 spits out。使用新的JRuby 9k:
我们花了很多时间把Logstash项目转移到JRuby的最新版本:JRuby 9000,它支持现代的Ruby语法和增强的内部结构,更适合优化。 对于插件开发者来说,这意味着你的老插件将继续在除了最罕见的情况之外的所有工作。 此升级还意味着您可以继续使用新的Ruby功能,以及使用仅与JRuby 9k兼容的Ruby库。1.2 跟着官网了解下logstash的基本流程
INPUTS
提取所有形式、大小、来源的数据:
数据通常以多种格式散布或分布在许多系统中。 Logstash支持各种输入,可以同时从多个常见的源中获取事件。 轻松从日志,指标,Web应用程序,数据存储和各种AWS服务中进行采集,所有这些都以连续,流式的方式进行。
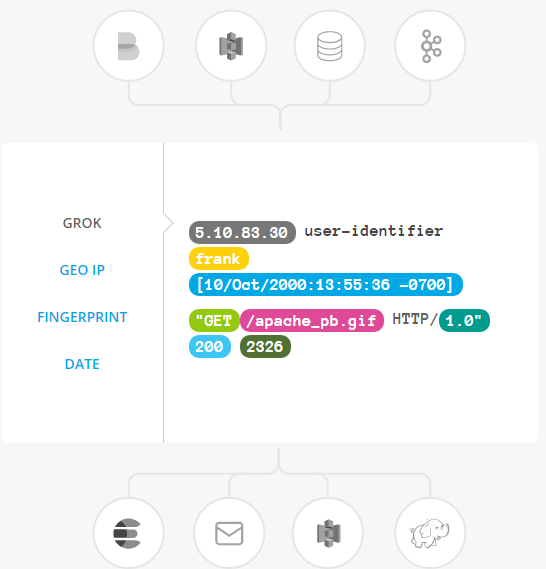
FILTERS
即时分析和转换您的数据:
当数据从源传输到存储时,Logstash过滤器解析每一个事件,识别命名的字段来构建结构,并将它们转换为一种通用格式,以方便、加速的分析和业务价值。
Logstash动态转换和准备您的数据,无论其格式或复杂性如何:
通过grok从非结构化数据派生结构
从IP地址解读地理坐标
Anonymize PII数据,完全排除敏感字段
简化独立于数据源,格式或模式的整体处理过滤器库:https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
OUTPUTS
选择你的Stash,传输你的数据:
虽然Elasticsearch是我们的首选输出,开创了搜索和分析可能性的世界,但并不是唯一可用的。Logstash有多种输出,可以让您在需要的地方路由数据,从而可以灵活地释放大量的下游用例。
输出插件:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
#大概流程就是流入==》过滤==》流出,下面还有点其他介绍。
可扩展性:
创建和配置自己的Pipeline:
Logstash有一个可插拔的框架,拥有超过200个插件。 混合,匹配和编排不同的输入,滤波器和输出以实现在管道中和谐工作。
Logstash plugins创建很容器构建,为插件开发和插件生成器通过了API,可以从自定义应用程序中获取数据(https://www.elastic.co/guide/en/logstash/current/contributing-to-logstash.html)。
耐用性和安全性:
内置数据传输的信任管道:
如果Logstash节点发生故障,Logstash会保证至少一次为您的进行中的事件传递其持续队列。未成功处理的事件可以被分流到一个死信队列中进行自省和回放。通过吸收吞吐量的能力,Logstash通过吞吐峰值进行扩展,而无需使用外部排队层。
无论您是运行10或1000个Logstash实例,我们都可以让您充分保护您的采集管道。 来自Beats(https://www.elastic.co/products/beats)的输入数据以及其他输入可以通过网络加密,并且与安全的Elasticsearch集群(https://www.elastic.co/products/x-pack/security)完全集成。
监测:
对部署具有完全可见性:
Logstash管道经常是多功能的,并且可以变得复杂,使得对管道性能,可用性和瓶颈的深入理解是非常宝贵的。 借助X-Pack中的监视和管道查看器功能(https://www.elastic.co/products/x-pack/monitoring),您可以轻松观察和研究活动Logstash节点或完整部署。
管理和编排:
使用单个UI集中管理部署:
使用Pipeline Management UI来执行Logstash部署,这使得编排和管理管道变得轻而易举。 管理控制还可以与内置的X-Pack安全功能无缝集成,以防止任何意外重新连接。
博文来自:www.51niux.com
二、Logstash的安装部署
#这里先用一台做下日志的收集工作。我们就选择192.168.14.65这台机器作为Logstash的机器。
#还是先要贴一下官网部署以及使用文档:https://www.elastic.co/guide/en/logstash/current/index.html
#Logstash和filebeat的几个示例:https://www.elastic.co/guide/en/logstash/current/logstash-config-for-filebeat-modules.html
#filebeat的正则:https://www.elastic.co/guide/en/beats/filebeat/6.0/regexp-support.html
2.1 安装Logstash
安装java
#Logstash需要Java 8。不支持Java 9。
# java -version
java version "1.8.0_74"
Java(TM) SE Runtime Environment (build 1.8.0_74-b02)
Java HotSpot(TM) 64-Bit Server VM (build 25.74-b02, mixed mode)#在某些Linux系统上,在尝试安装之前,可能还需要导出JAVA_HOME环境,特别是如果您从tarball安装了Java。 这是因为Logstash在安装过程中使用Java来自动检测您的环境并安装正确的启动方法(SysV init脚本,Upstart或systemd)。 如果Logstash在软件包安装期间无法找到JAVA_HOME环境变量,则可能会收到错误消息,并且Logstash将无法正常启动。
下载安装Logstash
# wget https://artifacts.elastic.co/downloads/logstash/logstash-6.0.1.tar.gz #线上用的是2.3.4的版本,这里用最新版......
# tar zxf logstash-6.0.1.tar.gz
# useradd elk
# cp -r logstash-6.0.1 /home/elk/
# ln -s /home/elk/logstash-6.0.1 /home/elk/logstash
# chown -R elk:elk /home/elk/
测试Logstash
#首先,我们通过运行最基本的Logstash管道来测试Logstash安装。Logstash管道有两个必需的元素,即输入和输出,以及一个可选元素filter。 输入插件使用来自数据源的数据,过滤器插件根据您的指定修改数据,输出插件将数据写入目标。
#要测试Logstash安装,请运行最基本的Logstash管道。 例如:
# su - elk
$ ./logstash -e 'input { stdin { } } output { stdout {} }' #定义了一个叫“stdin”的input还有一个“stdout”的output,无论输入什么字符,Logstash都会按照结构化格式将输入输出。
/home/elk/logstash/vendor/bundle/jruby/2.3.0/gems/manticore-0.6.1-java/lib/manticore/client.rb:108: warning: already initialized constant DEFAULT_MAX_POOL_SIZE
/home/elk/logstash/vendor/bundle/jruby/2.3.0/gems/manticore-0.6.1-java/lib/manticore/client.rb:110: warning: already initialized constant DEFAULT_REQUEST_TIMEOUT
/home/elk/logstash/vendor/bundle/jruby/2.3.0/gems/manticore-0.6.1-java/lib/manticore/client.rb:111: warning: already initialized constant DEFAULT_SOCKET_TIMEOUT
/home/elk/logstash/vendor/bundle/jruby/2.3.0/gems/manticore-0.6.1-java/lib/manticore/client.rb:112: warning: already initialized constant DEFAULT_CONNECT_TIMEOUT
/home/elk/logstash/vendor/bundle/jruby/2.3.0/gems/manticore-0.6.1-java/lib/manticore/client.rb:113: warning: already initialized constant DEFAULT_MAX_REDIRECTS
/home/elk/logstash/vendor/bundle/jruby/2.3.0/gems/manticore-0.6.1-java/lib/manticore/client.rb:114: warning: already initialized constant DEFAULT_EXPECT_CONTINUE
/home/elk/logstash/vendor/bundle/jruby/2.3.0/gems/manticore-0.6.1-java/lib/manticore/client.rb:115: warning: already initialized constant DEFAULT_STALE_CHECK
/home/elk/logstash/vendor/bundle/jruby/2.3.0/gems/manticore-0.6.1-java/lib/manticore/client.rb:590: warning: already initialized constant ISO_8859_1
/home/elk/logstash/vendor/bundle/jruby/2.3.0/gems/manticore-0.6.1-java/lib/manticore/client.rb:641: warning: already initialized constant KEY_EXTRACTION_REGEXP
Sending Logstash's logs to /home/elk/logstash/logs which is now configured via log4j2.properties
[2017-12-07T17:00:51,114][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/home/elk/logstash/modules/fb_apache/configuration"}
[2017-12-07T17:00:51,118][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/home/elk/logstash/modules/netflow/configuration"}
[2017-12-07T17:00:51,346][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2017-12-07T17:00:51,561][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2017-12-07T17:00:51,924][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>1000, :thread=>"#<Thread:0x7c079096@/home/elk/logstash/logstash-core/lib/logstash/pipeline.rb:290 run>"}
[2017-12-07T17:00:51,957][INFO ][logstash.pipeline ] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2017-12-07T17:00:51,971][INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]}
hello world #手工输入一个hello world
2017-12-07T09:03:32.065Z localhost.localdomain hello world #可以返回一个hello world,测试成功了。
[2017-12-07T17:07:14,815][INFO ][logstash.pipeline ] Pipeline terminated {"pipeline.id"=>"main"} #CTRL+D退出#Logstash将时间戳和IP地址信息添加到消息中。 通过在运行Logstash的shell中发出CTRL-D命令来退出Logstash。
博文来自:www.51niux.com
三、解析日志与Logstash
3.1 配置Filebeat发送日志到Logstash
先跟着官网介绍一下:
在创建Logstash管道之前,将配置Filebeat以将日志行发送到Logstash。Filebeat客户端是一个轻量级的,资源友好的工具,它从服务器上的文件中收集日志,并将这些日志转发给Logstash实例进行处理。 Filebeat专为可靠性和低延迟而设计。 Filebeat在主机上占用的资源较少,Beats输入插件最大限度地减少了Logstash实例的资源需求。
默认的Logstash安装包括Beats输入插件。 Beats输入插件允许Logstash从Elastic Beats框架接收事件,这意味着任何Beat框架编写的Beat框架(如Packetbeat和Metricbeat)都可以将事件数据发送到Logstash。
客户端安装Filebeat:
#正常生产场景下,哪台机器需要收集日志如web日志等会在其机器上安装Filebeat客户端。这里搞一个192.168.14.67来做此次web日志测试的客户机。
# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.0.1-linux-x86_64.tar.gz #还是下载最新版,线上用的是5.1.1版的
# useradd elk
# tar zxf filebeat-6.0.1-linux-x86_64.tar.gz
# cp -r filebeat-6.0.1-linux-x86_64 /home/elk/filebeat-6.0.1
# ln -s /home/elk/filebeat-6.0.1 /home/elk/filebeat
# chown -R elk:elk /home/elk/filebeat-6.0.1
配置Filebeat:
#su - elk
$ vim /home/elk/filebeat/filebeat.yml #只粘贴修改部分
#=========================== Filebeat prospectors =============================
- type: log
paths:
#- /var/log/*.log #目前按照Go语言的glob函数处理。没有对配置目录做递归处理,比如配置的如果是:/var/log/* /*.log则只会去/var/log目录的所有子目录中寻找以”.log”结尾的文件,而不会寻找/var/log目录下以”.log”结尾的文件。
#- c:\programdata\elasticsearch\logs\*
- /usr/local/nginx/logs/access.log
tags: ["nginx-access","test.51niux.com"]
#================================ General =====================================
name: "192.168.14.67"
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["192.168.14.65:5066"]
loadbalance: true
compression_level: 6$ cat /home/elk/filebeat/filebeat.yml #把样例配置都贴出来
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
#每个 - 是一个prospectors。大多数选项可以在prospectors级别设置,因此您可以使用不同的prospectors进行各种配置。 以下是prospectors特定的配置。
- type: log
enabled: false ##更改为true以启用此prospectors配置。
paths: ##应该被抓取和抓取的路径。 基于Glob的路径。
- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
#exclude_lines: ['^DBG'] #排除行。 要匹配的正则表达式列表。 它删除与列表中任何正则表达式匹配的行。
#include_lines: ['^ERR', '^WARN'] #包括行。 要匹配的正则表达式列表。 它从列表中导出与任何正则表达式匹配的行。
#exclude_files: ['.gz$'] #排除文件。 要匹配的正则表达式列表。 Filebeat会从列表中删除与任何正则表达式匹配的文件。 默认情况下,没有文件被丢弃。
#fields: #可选的附加字段。 可以自由选择这些字段,以将其他信息添加到搜寻的日志文件中进行过滤
# level: debug
# review: 1
###多行选项
#Multiline可以用于跨越多行的日志消息。 这在Java Stack Traces或C-Line Continuation中很常见
#multiline.pattern: ^\[ #必须匹配的正则表达式模式。 示例模式匹配所有以[
#multiline.negate: false #定义模式下的模式是否应该被否定。 默认是false。
#multiline.match: after ##匹配可以设置为“after”或“before”。 它用于定义行是否应该附加到之前或之后(不匹配)的模式,或者只要模式不匹配,则基于否定。 注意:相当于之前和之前相当于Logstash中的下一个
#============================= Filebeat modules ===============================
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml #配置加载的全局模式
reload.enabled: false #设置为true以启用配置重新加载
#reload.period: 10s #应检查路径下文件的更改时间间隔
#==================== Elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 3
#index.codec: best_compression
#_source.enabled: false
#================================ General =====================================
#name: #发布网络数据的发送人的名称。 它可以用于将单个发货人在Web界面中发送的所有传输进行分组。
#tags: ["service-X", "web-tier"] #发送人的标签包含在他们自己的字段中,每次传输都会发布。
#fields: ##可选字段,可以指定将其他信息添加到输出。
# env: staging
#============================== Dashboards =====================================
#setup.dashboards.enabled: false #这些设置控制将示例仪表板加载到Kibana索引。 加载仪表板默认是禁用的,可以通过在这里设置选项来启用,或者使用`-setup` CLI标记或`setup`命令启用。
#setup.dashboards.url: #从哪里下载仪表板归档的URL。 默认情况下,这个URL的值是根据节拍名称和版本计算的。 对于发布的版本,此URL指向artifacts.elastic.co网站上的仪表板存档。
#============================== Kibana =====================================
#从Beats版本6.0.0开始,仪表板通过Kibana API加载。这需要一个Kibana端点配置。
setup.kibana:
#host: "localhost:5601"
#============================= Elastic Cloud ==================================
#这些设置简化了使用Elastic Cloud(https://cloud.elastic.co/)的filebeat。
#cloud.id: #cloud.id设置将覆盖`output.elasticsearch.hosts`和`setup.kibana.host`选项。 可以在Elastic Cloud Web UI中找到
#cloud.auth: #cloud.auth设置将覆盖`output.elasticsearch.username`和`output.elasticsearch.password`设置。 格式是<user>:<pass>`。
#================================ Outputs =====================================
#配置发送beat收集的数据时使用的输出。
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
hosts: ["localhost:9200"] #要连接的主机数组。
#protocol: "https" ##可选协议和基本认证凭证。
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
#output.logstash:
#hosts: ["localhost:5044"] #Logstash主机
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] #可选的SSL。默认是关闭的。HTTPS服务器验证的根证书列表
#ssl.certificate: "/etc/pki/client/cert.pem" #SSL客户端认证证书
#ssl.key: "/etc/pki/client/cert.key" #客户证书密钥
#================================ Logging =====================================
#logging.level: debug ##设置日志级别。 默认的日志级别是info。可用的日志级别是:critical, error, warning, info, debug
#logging.selectors: ["*"] ##在调试级别,您可以选择性地启用仅针对某些组件的日志记录。 要启用所有选择器,请使用[“*”]。 其他选择器的例子是“beat”,“publish”,“service”。启动Filebeat:
$ ./filebeat -e -c filebeat.yml -d "publish"
2017/12/07 11:12:04.686924 beat.go:426: INFO Home path: [/home/elk/filebeat] Config path: [/home/elk/filebeat] Data path: [/home/elk/filebeat/data] Logs path: [/home/elk/filebeat/logs]
2017/12/07 11:12:04.687210 metrics.go:23: INFO Metrics logging every 30s
2017/12/07 11:12:04.687390 beat.go:433: INFO Beat UUID: d85b9ebe-c3c4-4ae3-91ed-0826a7bb8382
2017/12/07 11:12:04.687448 beat.go:192: INFO Setup Beat: filebeat; Version: 6.0.1
2017/12/07 11:12:04.689131 logger.go:18: DBG start pipeline event consumer
2017/12/07 11:12:04.689185 module.go:80: INFO Beat name: 192.168.14.67
2017/12/07 11:12:04.709937 beat.go:260: INFO filebeat start running.
2017/12/07 11:12:04.710061 registrar.go:71: INFO No registry file found under: /home/elk/filebeat/data/registry. Creating a new registry file.
2017/12/07 11:12:04.733832 registrar.go:108: INFO Loading registrar data from /home/elk/filebeat/data/registry
2017/12/07 11:12:04.733922 registrar.go:119: INFO States Loaded from registrar: 0
2017/12/07 11:12:04.735009 filebeat.go:260: WARN Filebeat is unable to load the Ingest Node pipelines for the configured modules because the Elasticsearch output is not configured/enabled. If you have already loaded the Ingest Node pipelines or are using Logstash pipelines, you can ignore this warning.
2017/12/07 11:12:04.735072 crawler.go:44: INFO Loading Prospectors: 1
2017/12/07 11:12:04.736376 registrar.go:150: INFO Starting Registrar
2017/12/07 11:12:04.737264 prospector.go:103: INFO Starting prospector of type: log; id: 16430255320212846879
2017/12/07 11:12:04.737538 crawler.go:78: INFO Loading and starting Prospectors completed. Enabled prospectors: 1
2017/12/07 11:12:04.737692 reload.go:128: INFO Config reloader started
2017/12/07 11:12:04.750387 reload.go:220: INFO Loading of config files completed.
2017/12/07 11:12:04.752227 harvester.go:207: INFO Harvester started for file: /usr/local/nginx/logs/access.log
2017/12/07 11:12:34.689285 metrics.go:39: INFO Non-zero metrics in the last 30s: beat.memstats.gc_next=4473924 beat.memstats.memory_alloc=3062112 beat.memstats.memory_total=3062112 filebeat.events.added=1 filebeat.events.done=1 filebeat.harvester.open_files=1 filebeat.harvester.running=1 filebeat.harvester.started=1 libbeat.config.module.running=0 libbeat.config.reloads=1 libbeat.output.type=logstash libbeat.pipeline.clients=1 libbeat.pipeline.events.active=0 libbeat.pipeline.events.filtered=1 libbeat.pipeline.events.total=1 registrar.states.current=1 registrar.states.update=1 registrar.writes=2
2017/12/07 11:13:04.688099 metrics.go:39: INFO Non-zero metrics in the last 30s: beat.memstats.gc_next=4473924 beat.memstats.memory_alloc=3088000 beat.memstats.memory_total=3088000 filebeat.harvester.open_files=1 filebeat.harvester.running=1 libbeat.config.module.running=0 libbeat.pipeline.clients=1 libbeat.pipeline.events.active=0 registrar.states.current=1
2017/12/07 11:13:34.687919 metrics.go:39: INFO Non-zero metrics in the last 30s: beat.memstats.gc_next=4473924 beat.memstats.memory_alloc=3107840 beat.memstats.memory_total=3107840 filebeat.harvester.open_files=1 filebeat.harvester.running=1 libbeat.config.module.running=0 libbeat.pipeline.clients=1 libbeat.pipeline.events.active=0 registrar.states.current=13.2Logstash端配置
$ mkdir conf
$ cd conf
$mkdir /home/elk/logstash/patterns #我们要转换的格式文件就存放在此目录下
$ cat /home/elk/logstash/patterns/51niux
NGUSERNAME [a-zA-Z\.\@\-\+_%]+ #这些现在还用不到,以后就会用到先粘贴在这里了
NGUSER %{NGUSERNAME}
NOTQUOTE [^\"]*
SPACE \s*
NOTDOT [^,]*
TEST_HTTP_ACCESS %{HTTPDATE:timestamp}\|%{IP:remote_addr}\|%{IPORHOST:http_host}\|(?:%{DATA:http_x_forwarded_for}|-)\|%{DATA:request_method}\|%{DATA:request_uri}\|%{DATA:server_protocol}\|%{NUMBER:status}\|(?:%{NUMBER:body_bytes_sent}|-)\|(?:%{DATA:http_referer}|-)\|%{DATA:http_user_agent}\|(?:%{DATA:request_time}|-)\|"
#主要是这里这句话,定义了一个TEST_HTTP_ACCESS,这就相当于模板,后面是通过log_format来匹配对应的正则。message是每段读进来的日志,IPORHOST、USERNAME、HTTPDATE等都是patterns/grok-patterns中定义好的正则格式名称,对照日志进行编写。
#grok pattren的语法为:%{SYNTAX:semantic},":" 前面是grok-pattrens中定义的变量,后面可以自定义变量的名称。(?:%{SYNTAX:semantic}|-)这种形式是条件判断。如果有双引号""或者中括号[],需要加 \ 进行转义。$ cat /home/elk/logstash/conf/logstash-nginx.conf #定义被logstash引用的配置文件
input { #定义客户端发送到哪个IP的哪个端口
beats {
host => "192.168.14.65"
port => 5066
}
}
filter {
if "nginx-access" in [tags]{ #如果tags里面是nginx-access匹配到了就进行下面的判断,if判断是用在收集多业务nginx日志的时候,这里先把框架写在这里,然后如果不是的话就可以在下面再定义else if
if "test.51niux.com" in [tags]{ #如果tags匹配到是test.51niux.com的话
grok { #就进行我们指定的TEST_HTTP_ACCESS这个模板里面的格式进行grok的格式转换。
patterns_dir => "/home/elk/logstash/patterns"
match => {
"message" => "%{TEST_HTTP_ACCESS}"
}
}
mutate { #类型转换,可以转换类型包括:"integer","float" 和 "string"。示例如下:
convert => { "nginx_request_time" => "float"}
convert => { "nginx_body_bytes_sent" => "integer"}
}
}
}
}
output {
if "nginx-access" in [tags]{ #如果是带着nginx-access的tags的消息
if "test.51niux.com" in [tags]{ #如果是带着tags是test.51niux.com的消息
elasticsearch { #写入到elasticsearch中
hosts => ["192.168.14.60","192.168.14.61","192.168.14.62","192.168.14.63","192.168.14.64"] #这里是elasticsearch集群
index => "logstash-nginx-access-test-51niux-com-%{+YYYY.MM}" #这里是创建的索引的格式以logstash开头然后以年月结尾。
}
}
}
}$ /home/elk/logstash/bin/logstash -t -f /home/elk/logstash/conf/logstash-nginx.conf #上面文件if判断了{}有点多,可以用-t来验证一下配置文件而不启动,结尾出现下面就是可以了
Configuration OK
[2017-12-07T19:38:07,082][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash$ /home/elk/logstash/bin/logstash -f /home/elk/logstash/conf/logstash-nginx.conf #指定配置文件前台启动,我们先看看输出。
[2017-12-07T19:52:04,304][INFO ][logstash.outputs.elasticsearch] Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://192.168.14.60:9200/, http://192.168.14.61:9200/, http://192.168.14.62:9200/, http://192.168.14.63:9200/, http://192.168.14.64:9200/]}}
[2017-12-07T19:52:04,307][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://192.168.14.60:9200/, :path=>"/"}
[2017-12-07T19:52:04,401][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://192.168.14.60:9200/"}
[2017-12-07T19:52:04,438][INFO ][logstash.outputs.elasticsearch] ES Output version determined {:es_version=>nil}
[2017-12-07T19:52:04,438][WARN ][logstash.outputs.elasticsearch] Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>6}
[2017-12-07T19:52:04,439][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://192.168.14.61:9200/, :path=>"/"}
[2017-12-07T19:52:04,449][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://192.168.14.61:9200/"}
[2017-12-07T19:52:04,455][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://192.168.14.62:9200/, :path=>"/"}
[2017-12-07T19:52:04,464][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://192.168.14.62:9200/"}
[2017-12-07T19:52:04,475][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://192.168.14.63:9200/, :path=>"/"}
[2017-12-07T19:52:04,486][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://192.168.14.63:9200/"}
[2017-12-07T19:52:04,494][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://192.168.14.64:9200/, :path=>"/"}
[2017-12-07T19:52:04,502][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://192.168.14.64:9200/"}
[2017-12-07T19:52:04,514][INFO ][logstash.outputs.elasticsearch] Using mapping template from {:path=>nil}
[2017-12-07T19:52:04,518][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
[2017-12-07T19:52:04,534][INFO ][logstash.outputs.elasticsearch] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["//192.168.14.60", "//192.168.14.61", "//192.168.14.62", "//192.168.14.63", "//192.168.14.64"]}
[2017-12-07T19:52:04,627][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>1000, :thread=>"#<Thread:0x139581ec@/home/elk/logstash/logstash-core/lib/logstash/pipeline.rb:290 run>"}
[2017-12-07T19:52:05,179][INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"192.168.14.65:5066"}
[2017-12-07T19:52:05,238][INFO ][logstash.pipeline ] Pipeline started {"pipeline.id"=>"main"}
[2017-12-07T19:52:05,251][INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]}
[2017-12-07T19:52:05,260][INFO ][org.logstash.beats.Server] Starting server on port: 5066#可以看到日志输出基本是没毛病的。
# netstat -lntup|grep 5066 #查看端口已经有了
tcp6 0 0 192.168.14.65:5066 :::* LISTEN 1683/java# lsof -i :5066
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 1683 elk 165u IPv6 18794 0t0 TCP 192.168.14.65:stanag-5066 (LISTEN)
java 1683 elk 166u IPv6 26958 0t0 TCP 192.168.14.65:stanag-5066->192.168.14.67:56018 (ESTABLISHED)#可以看到除了本地有一个5066监听端口外,还有一个客户端192.168.14.67的连接,注意了,也就是客户端发送日志的时候才会跟logstash的端口进行连接。
3.3 测试一下并配置Kibana
# for num in `seq 1 10000`;do curl -I http://192.168.14.67;done #随便找个 客户端,发它个10000次请求。
HTTP/1.1 200 OK
Server: nginx/1.12.2
Date: Thu, 07 Dec 2017 12:21:35 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Thu, 07 Dec 2017 09:42:54 GMT
Connection: keep-alive
ETag: "5a290d1e-264"
Accept-Ranges: bytes
HTTP/1.1 200 OK
Server: nginx/1.12.2
Date: Thu, 07 Dec 2017 12:21:35 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Thu, 07 Dec 2017 09:42:54 GMT
Connection: keep-alive
ETag: "5a290d1e-264"
Accept-Ranges: bytes#然后我们看看192.168.14.67的beat的输出界面
2017/12/07 12:21:36.284411 processor.go:262: DBG Publish event: {
"@timestamp": "2017-12-07T12:21:36.284Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.0.1"
},
"tags": [
"nginx-access",
"test.51niux.com"
],
"prospector": {
"type": "log"
},
"beat": {
"name": "192.168.14.67",
"hostname": "localhost.localdomain",
"version": "6.0.1"
},
"source": "/usr/local/nginx/logs/access.log",
"offset": 1792332,
"message": "192.168.14.64 - - [07/Dec/2017:20:21:35 +0800] \"HEAD / HTTP/1.1\" 200 0 \"-\" \"curl/7.29.0\""
}
2017/12/07 12:21:49.206552 metrics.go:39: INFO Non-zero metrics in the last 30s: beat.memstats.gc_next=4194304 beat.memstats.memory_alloc=1456736 beat.memstats.memory_total=332163248 filebeat.events.active=-128 filebeat.events.added=2201 filebeat.events.done=2329 filebeat.harvester.open_files=1 filebeat.harvester.running=1 libbeat.config.module.running=0 libbeat.output.events.acked=2329 libbeat.output.events.batches=18 libbeat.output.events.total=2329 libbeat.output.read.bytes=108 libbeat.output.write.bytes=45691 libbeat.pipeline.clients=1 libbeat.pipeline.events.active=0 libbeat.pipeline.events.published=2201 libbeat.pipeline.events.total=2201 libbeat.pipeline.queue.acked=2329 registrar.states.current=1 registrar.states.update=2329 registrar.writes=18
2017/12/07 12:22:19.206515 metrics.go:39: INFO Non-zero metrics in the last 30s: beat.memstats.gc_next=4194304 beat.memstats.memory_alloc=1485824 beat.memstats.memory_total=332192336 filebeat.harvester.open_files=1 filebeat.harvester.running=1 libbeat.config.module.running=0 libbeat.pipeline.clients=1 libbeat.pipeline.events.active=0 registrar.states.current=1#这是最后的窗口输出消息,可以看到它的发送过程。
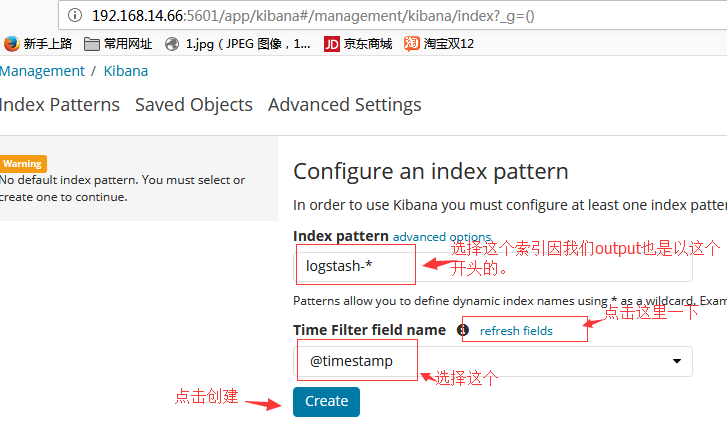
Kibana界面的配置和查看:
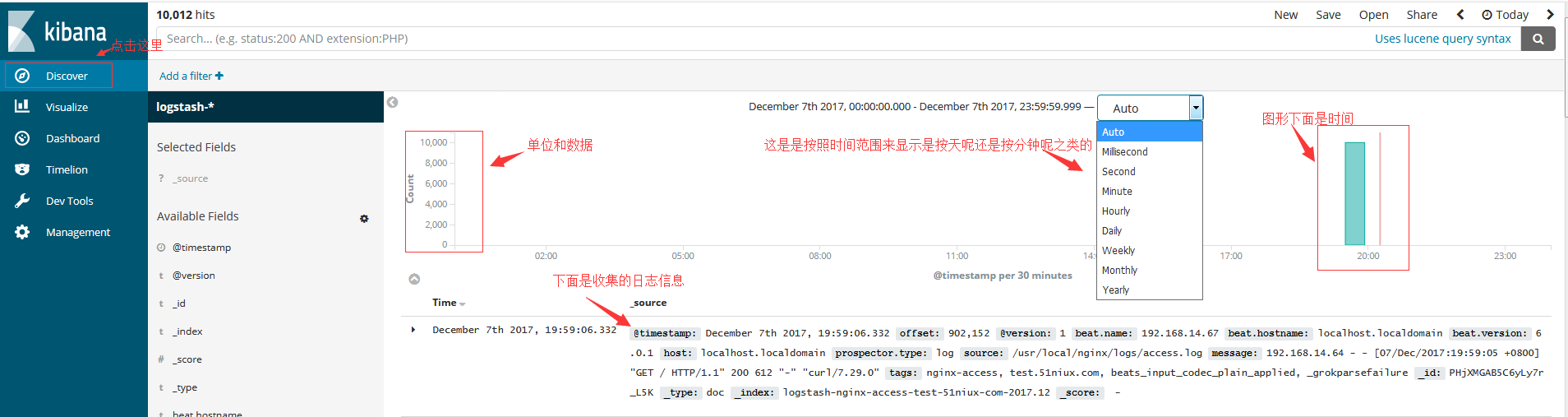
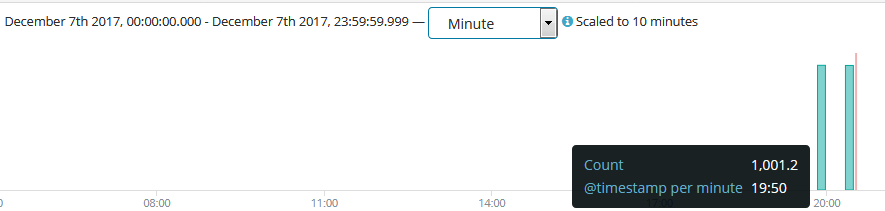
#按分钟来显示,然后将鼠标移动到左边的数据柱可以看到时间和Count次数。
3.4 跟着官网翻译一下grok过滤插件
官网链接:https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
描述:
解析任意文本并构造它。Grok是将非结构化日志数据解析为结构化和可查询的好方法。这个工具非常适合syslog日志,apache和其他web服务器日志,mysql日志,以及通常为人类而不是计算机消耗的任何日志格式。
默认情况下,Logstash附带约120个模式。 你可以在这里找到它们:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
Grok基础:
Grok通过将文本模式组合成与日志匹配的东西来工作。Grok模式的语法是%{SYNTAX:SEMANTIC}。语法是与您的文本相匹配的模式的名称。 例如,3.44将被NUMBER模式匹配,55.3.244.1将被IP模式匹配。 语法是你如何匹配。SEMANTIC是您为正在匹配的文本的标识符。 例如,3.44可能是一个事件的持续时间,所以你可以称之为持续时间。 此外,字符串55.3.244.1可以识别发出请求的客户端。对于上面的例子,你的Grok过滤器看起来像这样:
%{NUMBER:duration} %{IP:client}#或者,您可以将数据类型转换添加到您的grok模式。 默认情况下,所有的语义都保存为字符串。 如果您希望转换语义的数据类型,例如将字符串更改为整数,则将其后缀与目标数据类型。 例如%{NUMBER:num:int}将num语义从一个字符串转换为一个整数。 目前唯一支持的转换是int和float。
例子:有了这个语法和语义的思想,我们可以从一个样本日志中提取有用的字段,就像这个虚构的http请求日志:
55.3.244.1 GET /index.html 15824 0.043这种模式可能是:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}一个更现实的例子,让我们从文件中读取这些日志:
input {
file {
path => "/var/log/http.log"
}
}
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}在grok过滤器之后,事件将会有一些额外的字段:
client: 55.3.244.1
method: GET
request: /index.html
bytes: 15824
duration: 0.043常用正则表达:
Grok位于正则表达式之上,所以任何正则表达式在grok中都是有效的。 正则表达式库是Oniguruma,您可以在Oniguruma网站上看到完整支持的regexp语法:https://github.com/kkos/oniguruma/blob/master/doc/RE
下面翻译一下这个链接:
Oniguruma正式表达版本6.7.0 2017/12/08
语法:ONIG_SYNTAX_ONIGURUMA(默认)
语法元素:
\ #转义(启用或禁用元字符)
| #轮流交替
(...) #组
[...] #字符类,这里一般代表一个范围字符:
\t #水平制表符(0x09)
\v #垂直制表符(0x0B)
\n #换行符(换行符)(0x0A)
\r #回车(0x0D)
\b #退格(0x08)
\f #换页(0x0C)
\a #bell (0x07)
\e #转义(0x1B)
\nnn #八进制字符(编码字节值)
\o{17777777777} #宽八进制字符(字符代码点值)
\uHHHH #宽十六进制字符(字符码值)
\xHH #十六进制字符(编码字节值)
\x{7HHHHHHH} #宽十六进制字符(字符码值)
\cx #控制字符(字符码值)
\C-x #控制字符(字符码值)
\M-x #meta(x | 0x80)(字符码值)
\M-\C-x #元控制字符(字符码点值)
#(* \b作为退格仅在字符类中有效)字符类型:
. #任何字符(除了换行符)
\w #单词字符 不是Unicode:字母数字,“_”和多字节字符。
\W #非字字符
\s #空白字符 不是Unicode:\t,\n,\v,\f,\r,\x20
\S #非空白字符
\d #十进制数字字符 Unicode:General_Category - Decimal_Number
\D #非十进制数字字符
\h #十六进制数字字符[0-9a-fA-F]
\H #非十六进制字符
\R #通用换行符(*不能用于字符类)"\r\n" or \n,\v,\f,\r(*但不会从\r\n回溯到\r) Unicode情况下:"\r\n" or \n,\v,\f,\r or U+0085, U+2028, U+2029
\N #负面的换行符(?-m :.)
\O #true anychar(?m :.)(*原始函数)
\X #扩展字形集群 (?>\O(?:\Y\O)*) \X不检查匹配的起始位置是否是边界。写为\y \X如果你想确保它。
#字符属性
* \p{property-name}
* \p{^property-name} (negative)
* \P{property-name} (negative)
property-name:
+适用于所有编码 #Alnum, Alpha, Blank, Cntrl, Digit, Graph, Lower,Print, Punct, Space, Upper, XDigit, Word, ASCII
+在EUC_JP,Shift_JIS上工作 # Hiragana, Katakana
+工作在UTF8,UTF16,UTF32 #请参阅doc / UNICODE_PROPERTIES。量词:
#greedy
? #1或0次
* #0或更多次
+ #1次或更多次
{n,m} #至少n但不超过m次
{n,} #至少n次
{,n} #至少为0但不超过n次({0,n})
{n} #n次
#reluctant
?? #1或0次
*? #0次或更多次
+? #1次或更多次
{N,M}? #至少n但不超过m次
{N,}? #至少n次
{,N}? #至少为0但不超过n次(== {0,n}?)
#possessive (greedy and does not backtrack once match)
?+ #1或0次
*+ #0或更多次
++ #一次或多次
({n,m}+, {n,}+, {n}+ #仅在ONIG_SYNTAX_JAVA中占有)
# ex. /a*+/ === /(?>a*)/Anchors:
^ #行的开头
$ #行结束
\b #字边界
\B #非单词边界
\y #扩展的字形集群边界
\Y #扩展的字形集群非边界
\A #字符串的开始
\Z #结尾的字符串,或换行符在结尾处
\z #字符串的结尾
\G #当前的搜索尝试开始
\K #保留(保留结果字符串的起始位置)字符类:
^... #负面的类(最低优先)
x-y #范围从x到y
[...] #设置(字符类中的字符类)
..&&.. #相交(低优先级,只高于^)
# ex. [a-w&&[^c-g]z] ==> ([a-w] AND ([^c-g] OR z)) ==> [abh-w]
*如果您想使用'[',' - '或']'作为普通字符。在字符类中,你应该用'\'来转义它们。
#POSIX括号([:xxxxx:],否定[:^ xxxxx:])
#不是Unicode的情况下:
alnum #字母或数字字符
alpha #字母
ascii #代码值:[0 - 127]
blank #\t,\x20
cntrl
digit #0-9
graph #包括所有多字节编码字符
lower
print #包括所有多字节编码字符
punct
space #\t, \n, \v, \f, \r, \x20
upper
xdigit #0-9,a-f,A-F
word #单词字母数字,“_”和多字节字符
#Unicode案例:
alnum #字母| 标记|十进制数
alpha #字母| 标记
ascii # 0000 - 007F
blank #Space_Separator | 0009
cntrl #Control | Format | Unassigned | Private_Use | Surrogate
digit #十进制数
graph # [[:^space:]] && ^Control && ^Unassigned && ^Surrogate
lower #Lowercase_Letter
print #[[:graph:]] | [[:space:]]
punct #Connector_Punctuation | Dash_Punctuation | Close_Punctuation | Final_Punctuation | Initial_Punctuation | Other_Punctuation | Open_Punctuation
space #Space_Separator | Line_Separator | Paragraph_Separator | U+0009 | U+000A | U+000B | U+000C | U+000D | U+0085
upper # Uppercase_Letter
xdigit #U+0030 - U+0039 | U+0041 - U+0046 | U+0061 - U+0066 (0-9, a-f, A-F)
word #Letter | Mark | Decimal_Number | Connector_Punctuation#剩下的看链接吧......
自定义模式:
有时logstash没有你需要的模式。 为此,有几个选项。
首先,可以使用Oniguruma语法来命名捕获,这将使您匹配一段文本并将其保存为一个字段:
(?<field_name>the pattern here)例如,后缀日志的队列ID是10或11个字符的十六进制值。 我可以很容易地捕捉到这一点:
(?<queue_id>[0-9A-F]{10,11})或者,可以创建一个自定义模式文件。
创建一个名为patterns的目录,其中包含一个名为extra的文件(文件名无关紧要,但为自己命名)
在该文件中,将需要的模式写为模式名称,空格,然后是该模式的正则表达式。例如,像上面那样做postfix队列id的例子:
# contents of ./patterns/postfix:
POSTFIX_QUEUEID [0-9A-F]{10,11}然后使用此插件中的patterns_dir设置来告知logstash您的自定义模式目录。 以下是一个带有示例日志的完整示例:
Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>过滤例子:
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}以上内容将匹配并导致以下字段:
timestamp: Jan 1 06:25:43
logsource: mailserver14
program: postfix/cleanup
pid: 21403
queue_id: BEF25A72965
syslog_message: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>The timestamp, logsource, program, and pid fields come from the SYSLOGBASE pattern ,它本身是由其他模式定义的。
另一种选择是使用pattern_definitions在过滤器中内联定义模式。 这主要是为了方便,并允许用户定义可以在该过滤器中使用的模式。 pattern_definitions中新定义的模式在特定的Grok过滤器之外将不可用。
Grok过滤器配置选项:
该插件支持以下配置选项和稍后介绍的通用选项。
break_on_match #值类型是布尔值,默认值为truegrok的第一个成功的匹配将导致过滤器被完成。如果你想grok尝试所有的模式(也许你是解析不同的东西),然后将其设置为false。
keep_empty_captures #值类型是布尔值,默认值是false。如果为true,则将空捕获保留为事件字段。
match #值类型是hash,默认值是{}。 field ⇒ value的匹配散列
named_captures_only #值类型是布尔值,默认值为true。如果为true,则只存储grok的命名捕获。
overwrite #值类型是数组,默认值是[]。要覆盖的字段。这使可以覆盖已存在的字段中的值。
pattern_definitions #值类型是hash。默认值是{}。模式名称和模式元组的散列,用于定义当前过滤器要使用的自定义模式。 匹配现有名称的模式将覆盖预先存在的定义。 把这个想象成可用的内联模式就是grok的这个定义
patterns_dir #值类型是数组,默认值是[]。Logstash默认带有一堆模式,所以你不一定需要自己定义这个,除非你添加额外的模式。 您可以使用此设置指向多个模式目录。 请注意,Grok将读取与patterns_files_glob匹配的目录中的所有文件,并假定它是一个模式文件(包括任何波形备份文件)。
patterns_files_glob #值类型是字符串,默认值是“*”。Glob模式,用于在由patterns_dir指定的目录中选择模式文件
tag_on_failure #值类型是数组,默认值是[“_grokparsefailure”]。没有成功匹配时,将值追加到标签字段
tag_on_timeout #值类型是字符串,默认值是“_groktimeout”。如果grok正则表达式超时,则应用标记。
timeout_millis #值类型是数字,默认值是30000。尝试在这段时间后终止正则表达式。 这适用于每个模式,如果应用多个模式这将永远不会提前超时,但可能需要一些时间超时。 实际的超时时间是基于250ms量化的近似值。 设置为0以禁用超时下面是overwrite的例子:
filter {
grok {
match => { "message" => "%{SYSLOGBASE} %{DATA:message}" }
overwrite => [ "message" ]
}
}#例如,如果在消息字段中有syslog行,则可以使用部分匹配覆盖消息字段,如下所示:在这种情况下,像一条lineMay 29 16:37:11 sadness logger: hello world 将被解析和hello world将覆盖原来的消息。
通用选项:
add_field:
值类型是hash。默认值是{}。如果此过滤器成功,请将任意字段添加到此事件。 字段名称可以是动态的,并使用%{field}来包含事件的一部分。
例:
filter {
grok {
add_field => { "foo_%{somefield}" => "Hello world, from %{host}" }
}
}
# You can also add multiple fields at once:
filter {
grok {
add_field => {
"foo_%{somefield}" => "Hello world, from %{host}"
"new_field" => "new_static_value"
}
}
}#如果事件的字段为“somefield”==“hello”,那么这个过滤器在成功时将添加字段foo_hello(如果存在),并且上面的值和%{host}部分被来自事件的值替换。 第二个例子也会添加一个硬编码的字段。
add_tag:
值类型是array,默认值是[]。如果此过滤器成功,请向该事件添加任意标签。 标签可以是动态的,并使用%{field}语法包含事件的一部分。
例子:
filter {
grok {
add_tag => [ "foo_%{somefield}" ]
}
}
# You can also add multiple tags at once:
filter {
grok {
add_tag => [ "foo_%{somefield}", "taggedy_tag"]
}
}如果事件的字段为“somefield”==“hello”,那么这个过滤器会成功添加一个标签foo_hello(而第二个例子当然会添加一个taggedy_tag标签)。
enable_metric:
值类型是布尔值,默认值为true.
为特定的插件实例禁用或启用度量标准日志记录,我们默认记录所有的度量标准,但是您可以禁用特定插件的度量标准收集。
id:
值类型是字符串,这个设置没有默认值。为插件配置添加一个唯一的ID。 如果没有指定ID,Logstash将会生成一个。 强烈建议在您的配置中设置此ID。 当你有两个或多个相同类型的插件时,这是非常有用的,例如,如果你有2个grok过滤器。 在这种情况下添加一个命名的ID将有助于在使用监视API时监视Logstash。
filter {
grok {
id => "ABC"
}
}periodic_flush:
值类型是布尔值,默认值是false。定期调用过滤器刷新方法。 可选的。
remove_field:
值类型是数组,默认值是[]。如果此过滤器成功,请从此事件中删除任意字段。 例:
filter {
grok {
remove_field => [ "foo_%{somefield}" ]
}
}
# You can also remove multiple fields at once:
filter {
grok {
remove_field => [ "foo_%{somefield}", "my_extraneous_field" ]
}
}如果事件的字段为“somefield”==“hello”,则此过滤器在成功时将删除名称为foo_hello的字段(如果存在)。 第二个例子会删除一个额外的非动态字段。
remove_tag:
值类型是数组,默认值是[]。如果此过滤器成功,请从该事件中移除任意标签。 标签可以是动态的,并使用%{field}语法包含事件的一部分。
例子:
filter {
grok {
remove_tag => [ "foo_%{somefield}" ]
}
}
# You can also remove multiple tags at once:
filter {
grok {
remove_tag => [ "foo_%{somefield}", "sad_unwanted_tag"]
}
}如果事件的字段为“somefield”==“hello”,那么这个过滤器在成功的时候会删除标签foo_hello(如果存在的话)。 第二个例子会删除一个sad_unwanted_tag的标签。
##############################
转自:http://www.51niux.com/?id=203















 4722
4722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









