






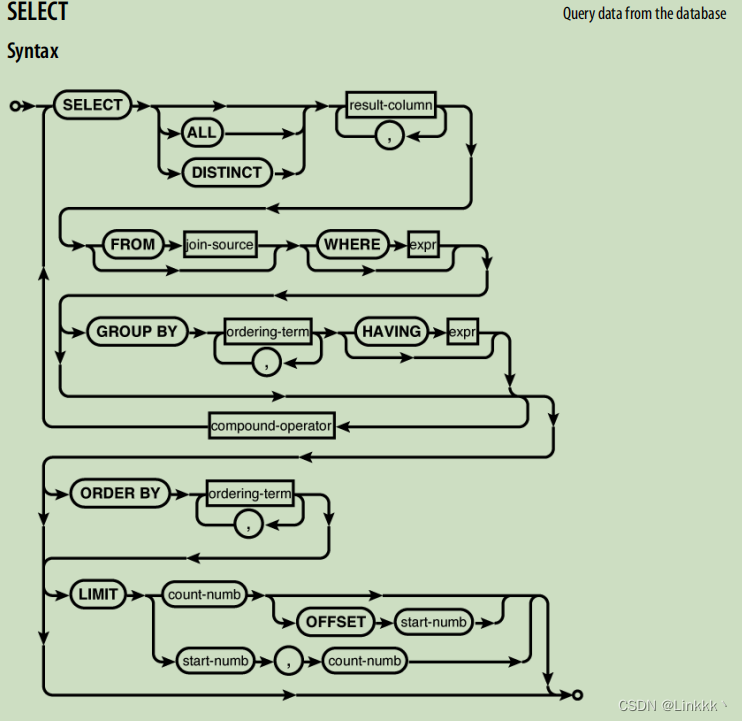
SQL:SELECT 命令
SQL 表
主要的 SQL 数据结构是表。表被用于存储和数据管理。
表由表头和表体组成。表头定义每列的名字和类型。列名在表中必须唯一。表头也定义列的排序,它被固定为表定义的一部分。
表体全部由行组成。行由数据元素组成,一列一个。每个元素保存一个数据值 (或一个 NULL)。
SQL 表允许保存重复的行。表能保存这样的多个行,其每个用户定义的列对应都有完全等价的值。重复的行通常在实践中是不期望的,但它们确实被允许。
SQL 表中的行是无序的。 当一个表被展示或写入,它可能具有某种固有的顺序,但是在概念上,表是无序的。插入的顺序对表来说毫无意义。
一个非常常见的错误是假定一个给定的查询总是以相同的顺序返回。除非你显式的指定查询将返回的行进行排序,并不能保证返回的列依然保持相同的顺序。不要让你的应用代码依赖一个无序查询的自然排序。不同版本的 SQLite 可能对查询进行不同的优化,导致不同的行顺序。甚至简单地添加或丢弃一个索引都可能改变一个无序结果的行顺序。
SELECT 管道
SELECT 语法致力于表示一个通用的框架,能够表达多种不同类型的查询。为了实现这一目的,SELECT 有大量可选的子句,每个都有它自己的选项集和格式。
标准 SQLite SELECT 语句最通用的格式看起来就像这样:
SELECT [DISTINCT] select_heading
FROM source_tables
WHERE filter_expression
GROUP BY grouping_expressions
HAVING filter_expression
ORDER BY ordering_expressions
LIMIT count
OFFSET count
每个 SELECT 命令必须有一个 select heading,它定义了返回值。每个额外的行 (FROM,WHERE,GROUP BY,等) 表示一个可选子句。
每个子句表示 SELECT 管道中的某一步骤。理论上,SELECT 语句的结果是通过产生一个工作表,然后就表穿过管道,这样计算出来的。每一个步骤都将工作表视作一个输入,执行特定的操作,然后将修改后的表传入下一个步骤。操作在整个表上执行,类似于数组或矩阵操作。事实上,数据库引擎在查询时会采取一些快捷的方式,并做出大量的优化,但是产生的结果应当总是与按序单独执行每个步骤产生的结果匹配。
SELECT 语句中的子句并非以它们被写入的顺序进行计算。相反,计算顺序看上去就像这样:
- FROM source tables
指定一个或多个源表,并将它们结合到一起形成一个大的工作表。 - WHERE filter_expression
过滤工作表中的指定行。 - GROUP BY grouping_expressions
基于相似的值对工作表中的行进行分组。 - SELECT select_heading
定义结果列集合并 (如果可以应用的话) 进行分组聚合。 - HAVING filter_expression
将特定的行从分组后的表中过滤出去。需要 GROUP BY。 - DISTINCT
剔除重复的行。 - ORDER BY ordering_experssions
对结果集中的行进行排序。 - OFFSET
从结果集的开始跳过多少行。需要 LIMIT。 - LIMIT
限制结果集输出指定数量的行数。
不管 SELECT 语句多大多么复杂,它们都遵循基础模式。为了理解查询如何工作,将其分解为单个步骤。确保你能理解在每一步前工作表是什么样的,该步骤如何操作和修改工作表,在传递到下一步骤前,工作表看起来像什么样。
FROM 子句
FROM 子句使用一个或多个来自数据库的源表,并将它们结合成一个大表。源表通常是数据库中的命名表,但是它们也可是视图或子查询。
使用 JOIN 操作符将表结合到一起。每个 JOIN 结合两个表成为一个更大的表。通过将一系列 JOIN 操作符串联到一起以连接三个或更多的表。JOIN 操作符从左向右进行计算,但是有几种不同类型的连接,不是所有的都是可交换或可结合的。这是的排序和分组变得十分重要。必要的话,可以使用括号对连接进行分组使其正确。
连接是最重要也是最强大的数据库操作符。连接是唯一将存储于数据库中不同表的信息聚集到一起的方法。
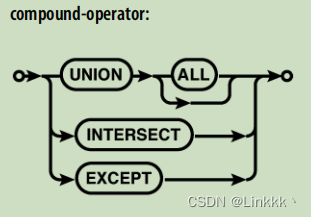
SQL 定义了三种连接的主要类型:CROSS JOIN,INNER JOIN,OUTER JOIN。
CROSS JOIN
CROSS JOIN 匹配第一个表中每行到第二个表中的每行。如果输入的表分别有 x 列和 y 列,结果表将有 x + y 列。如果输入表分别有 m 和 n 行,则结果表将有 m*n 行。在数学上,CROSS JOIN 被称为笛卡尔积。
CROSS JOIN 的语法非常简单:
SELECT ... FROM t1 CROSS JOIN t2 ...
下图展示了 CROSS JOIN 是如何被计算的。
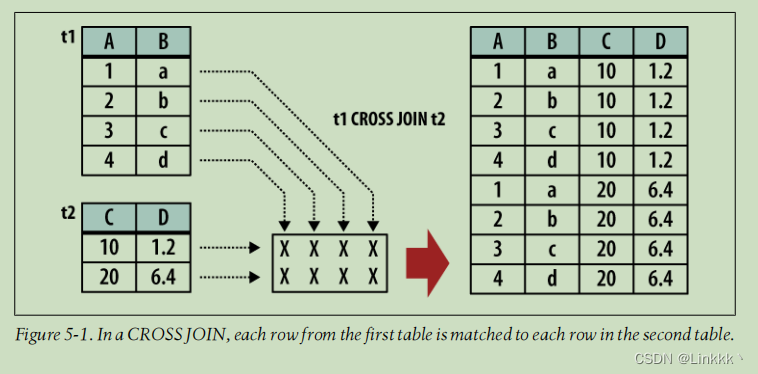
因为 CROSS JOIN 可能生成很大的表,注意仅在合适的时候使用它们。
INNER JOIN
INNER JOIN 与 CROSS JOIN 十分类似,但是它有一个内置的条件用于限制结果表的行数。这一条件通常被用于配对或匹配两个源表中的行。没有任何类型的条件表达式 (或者一个总是返回 TRUE 的条件表达式) 的 INNER JOIN 将会导致一个 CROSS JOIN。 如果输入表分别有 x 和 y 列,结果表中的列数将不会超过 x+y 列 (在某些情况下,列数可能更少)。如果输入表分别有 n 和 m 行,则结果表可能有 0 到 n*m 之间的任意行数,取决于条件。INNER JOIN 是最常见的连接类型,也是默认的连接类型。这使 INNER 关键词变成了是可选的。
有三种基本的方法用于指定条件。第一种是使用 ON 表达式。它提供一个简单的表达式为每个潜在的行求值。只有求值为真的行才能真正连接。JOIN…ON 看起来像这样:
SELECT ... FROM t1 JOIN t2 ON condition_expression ...
下图展示一个例子:
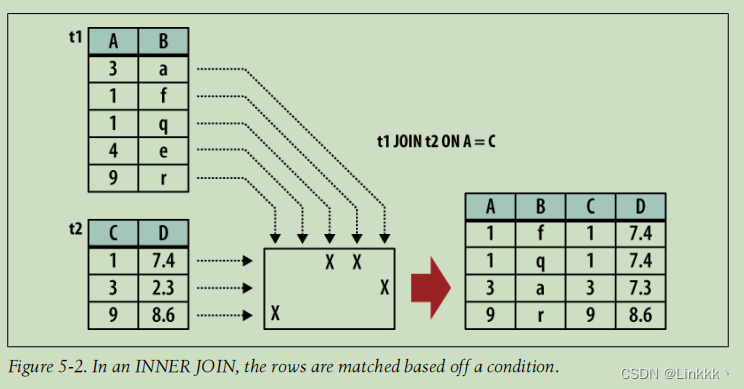
如果输入表分别有 C 和 D 列,JOIN…ON 将总是产生 C + D 列。
条件表达式可以被用于测试任何事,但是最常见的表达式测试类型是测试两个表中相似列之间的等价性。例如:
SELECT ... FROM employee
JOIN resource ON employee.eid = resource.eid ...
这种 JOIN 有两个问题。首先,ON 条件需要进行很多输入。其次,结果表将有两个 eid 列,但是对于任何所给的列,这两列的值完全等价。为了去除冗余并保证输入简短,内部连接条件可以使用 USING 表达式声明。该表达式指定一个单个或多个列的列表:
SELECT ... FROM t1 JOIN t2 USING ( col1 ,... ) ...
例如:
SELECT ... FROM t1 JOIN t2 USING ( eid )...
为了满足 USING 条件,列名必须存在于两个表中。对每一个列出的列名,USING 条件将测试列对之间的等价性。结果表将持有列出列的唯一实例。
如果这还不够简洁,SQL 提供另一个快捷方式。NATURAL JOIN 类似于 JOIN…USING,它自动地测试存在于两个表中的每一列的值之间的等价性:
SELECT ... FROM ti NATURAL JOIN t2 ...
如果输入表分别有 x 和 y 列,JOIN…USING 或 NATURAL JOIN 将产生 max(x, y) 到 x+y 列数的结果表。例如:
SELECT ... FROM employee NATURAL JOIN resource ...
NATURAL JOIN 十分方便,因为它们非常简洁,且允许改变不同表的键结构,而不必更新所有对应的查询。如果不同表中的两列具有相同的名字,NATURAL JOIN 将自动的将它们包含到连接条件中。
OUTER JOIN
OUTER JOIN 是 INNER JOIN 的拓展。SQL 标准定义了三种类型的 OUTER JOIN:LEFT,RIGHT,和 FULL。
OUTER JOIN 有一个与 INNER JOIN 等价的条件,使用 ON,USING,NATURAL 关键词表示。初始结果表以相同的方式计算。一旦基本的 JOIN 完成,OUTER 连接将获取一个或两个表中没有被连接的行,使用 NULLs 填充它们,并将它们追加到结果表中。在 LEFT OUTER JOIN 中,对第一个表 (出现在 JOIN 左侧的表) 中不匹配的行执行这样的操作。
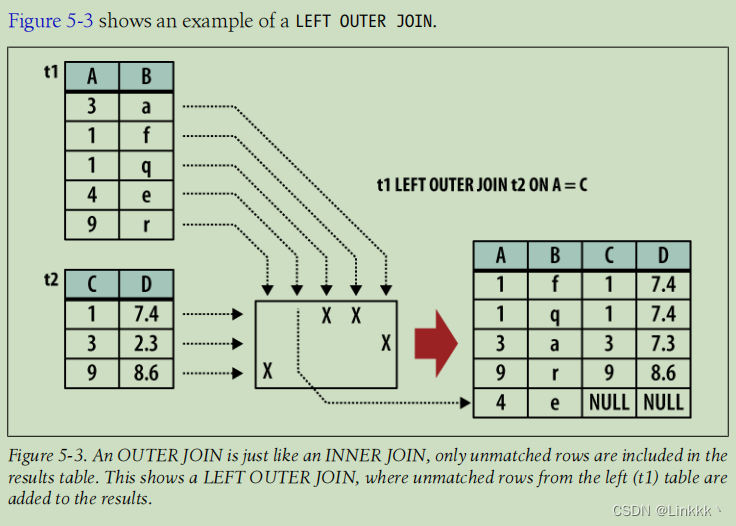
LEFT OUTER JOIN 的结果至少包含来自左边表的每一行的一个实例。如果输入表分别有 x 和 y 列,结果表将不会超过 x+y 列 (具体的列数取决于使用的条件)。如果输入表分别有 m 和 n 行,结果表可能有 n 到 n*m 行。
因为包含未匹配的行,OUTER JOIN 通常专门用于搜索未解决的或“悬挂”的行。
Table 别名
因为 JOIN 结合不同表中的列到一个更大的表中,产生的结果工作表可能有多个具有相同名字的列。为了避免歧义,SELECT 语句的任何部分都能使用源表名来限定列引用。然而,在一些情况下,这样仍然不够。例如,一些情况下你需要连接一个表到它自己身上,导致工作表包含相同源表的两个实例。这样不仅仅使列名变得模糊,使用源表名也不能对它们进行区分。另一个问题是使用子查询,因为它们没有具体的源表名。
为了避免 SELECT 语句中的歧义,任何源表,视图,或子查询的实例都能被分配一个别名。这通过 AS 关键词完成。例如:
SELECT ... FROM x AS x1 JOIN x AS x2 ON x1.col1 = x2.col2...
或者在子查询的例子中:
SELECT ... FROM (SELECT ...) AS sub ...
技术上,AS 关键词是可选的,每个源表名都能简单地跟随一个别名。
如果任何子查询列与标准源表列相冲突,你可以使用 sub 标识符作为一个表名。例如,sub.col1。
一旦分配一个别名,源表名则变得非法,且不能再被用于列标识符,必须使用别名。
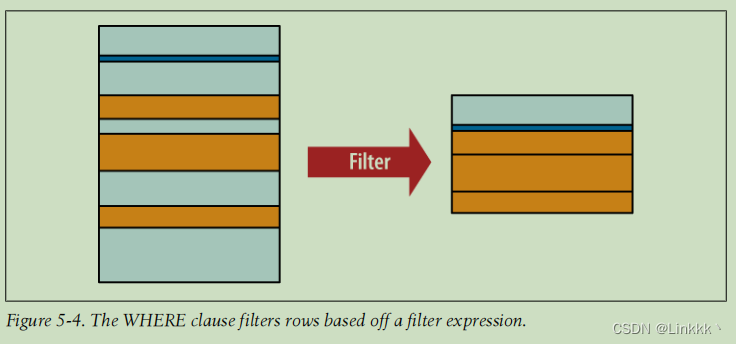
WHERE 子句
WHRER 子句用于过滤 FROM 子句产生的工作表中的行。WHRER 子句提供一个表达式,对每个行进行计算。任何使用表达式的值为假或为 NULL 的行被丢弃。结果表与源表有相同的列数,但可能有更少的行。WHERE 子句可能会剔除源表中的每一行,这不被认为是一个错误。
一些 WHERE 子句可能很复杂,导致很长一串 AND 操作符将子表达式连接到一起。然而,大部分过滤器都是针对特定行搜索特定键值。
GROUP BY 子句
GROUP BY 子句被用于折叠,或“压平”,一组行。组能被计数,平均化,或聚合在一起。如果你需要执行任何类型的行间操作,该操作需要超过一行数据,你可能需要一个 GROUP BY。
GROUP BY 子句提供分组表达式和可选的排序的列表。表达式是简单的行引用的情况非常常见,但是它们可以是任意表达式。语法看上去像是这样:
GROUP BY grouping_expression [COLLATE collation_name] [,...]
分组过程有两步。第一步,GROUP BY 表达式列表被用于分派表中的行到不同的组中。一旦组被定义,SELECT header 定义这些组如何被压扁成一行。结果表每个组都有一行。
为了将工作表划分为组,表达式列表在表的每行上求值。所有产生相等的值的行被划分到一组。每个表达式可以指定一个可选的排序规则。如果分组的表达式涉及文本值,使用的排序规则决定值是否相等。
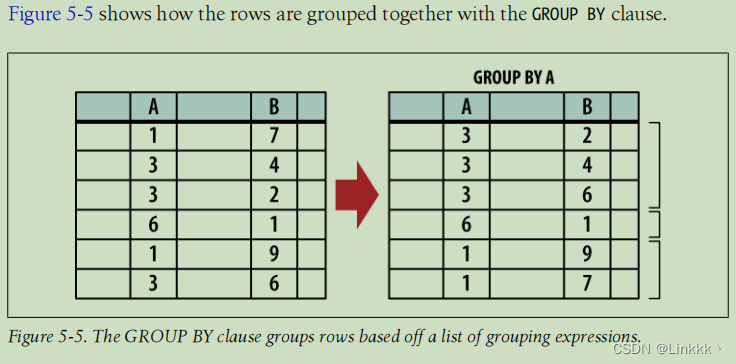
一旦被分组到一起,每个行的集合都被折叠成一行。通常使用 SELECT header 中定义的聚合函数来完成这一操作。
因为 GROUP BY 使用定义于 SELECT header 中的表达式的情况十分常见,可能能简化 GROUP BY 表达式列表对 SELECT header 表达式的引用。如果 GROUP BY 表达式是一个字面值整数,该整数被用作 SELECT header 中定义的结果表中的列索引。最左侧的列的索引为 1。GROUP BY 表达式也能引用结果列别名。
SELECT Header
SELECT header 被用于定义格式和最终结果表的内容。任何你希望在最终结果表中出现的列必须在 SELECT header 中通过表达式定义。在 SELECT 命令管道中,SELECT heading 是唯一需要的步骤。
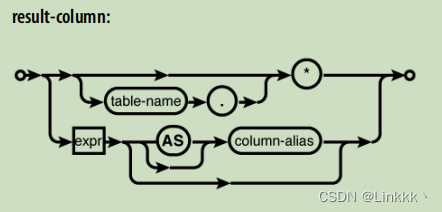
header 的格式十分简单,由表达式列表组成。每个表达式在每行的上下文中进行求值,产生最终的结果表。表达式是简单的列引用这种场景十分常见,但是它可以是关于列引用,字面量值,或 SQL 函数的任何表达式。为了生成最终的查询结果,表达式列表对工作表中的每行进行一次求值。
另外,你可以使用 AS 关键词提供一个行名:
SELECT expression [AS column_name][,...]
不要把在 SELECT header 中使用的 AS 关键词与在 FROM 子句中使用的 AS 关键词弄混淆。SELECT header 中使用的 AS 关键词为输出列中某列分配一个列名,而 FROM 子句中使用的 AS 关键词为源表提供一个别名。
提供一个输出列名是可选的,但是推荐这样做。分配给结果表的列名没有严格定义,除非用户提供一个 AS 列别名。如果在查询结果中搜索特定的列名,确保使用 AS 分配一个已知的名字。分配列名也允许 SELECT 语句的其他部分使用名字引用输出列。在 SELECT header 前处理的 SELECT 管道中的步骤,例如 WHERE 或 GROUP BY 子句,也能引用使用名字引用输出列,只要表达式不包含聚合函数即可。
如果没有工作表 (没有 FROM 子句),表达式只进行一次求值,产生一行。该行随后被用作工作表。这对测试和对独立的表达式进行求值十分有用。
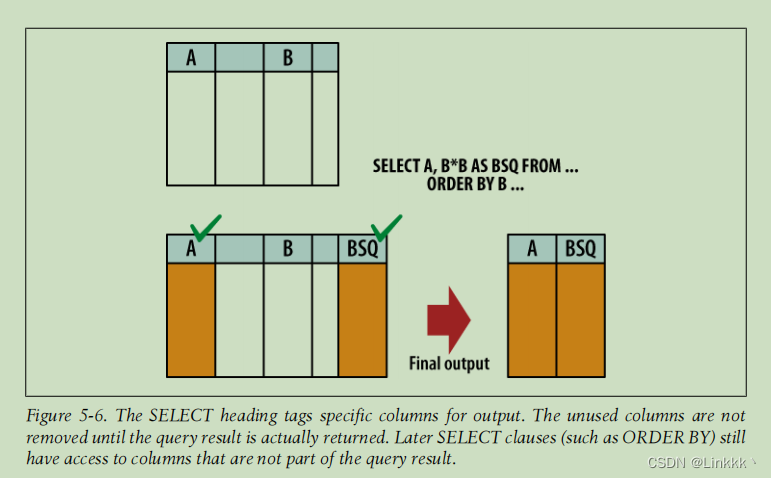
虽然 SELECT header 好像过滤了工作表中的列,就像 WHERE 子句过滤行一样,这不是完全正确的。所有来自源表的列对在 SELECT header 之后处理的子句依然可用。例如,使用没有出现在查询输出中的列对结果进行排序 (使用 ORDER BY,它在 SELECT header 之后处理)。
更具体地说是,SELECT header 标记输出中指定的行。直到整个 SELECT 管道已经处理完成了,结果已经准备好返回了,未使用的行才会被剔除。下图解释了这一点:
除了标准表达式,SELECT 支持两种通配符。星号(*)通配符将导致 FROM 子句产生的每个源表中的每个用户定义的列被输出。你可以使用格式 table_name.* 将目标设定为特定的表 (或表别名)。虽然这些统配符都能返回多行,但它们可以与表达式列表中的其他表达式一起使用。统配符不能使用列别名,因为它们通常返回多列。
注意 SELECT 通配符不会返回自动生成的 ROWID 列。为了返回 ROWID 列和用户自定义的列,简单地同时请求二者:
SELECT ROWID, * FROM table;
通配符包含任何用户定义的替换标准的 ROWID 列的 INTEGER PRIMARY KEY 列。
除了确定查询结果中的列,SELECT 确定行组 (由 GROUP BY 子句产生) 如何平摊到单行中。这通过使用聚合函数完成。聚合函数将一个列表达式作为输入,产生一个输出值。常见的聚合函数包含 count(), min(), max(), avg()。
任何没有传入聚合函数的列或表达式将假设为组中最后一行中包含的值。然而,因为 SQL 表是无序的,也因为 SELECT header 在 ORDER BY 子句之前处理,我们实际上并不知道谁是最后一行。这意味着任何未聚合的输出的值将从组中某些本质上是随机的的行中选取。 如下图:
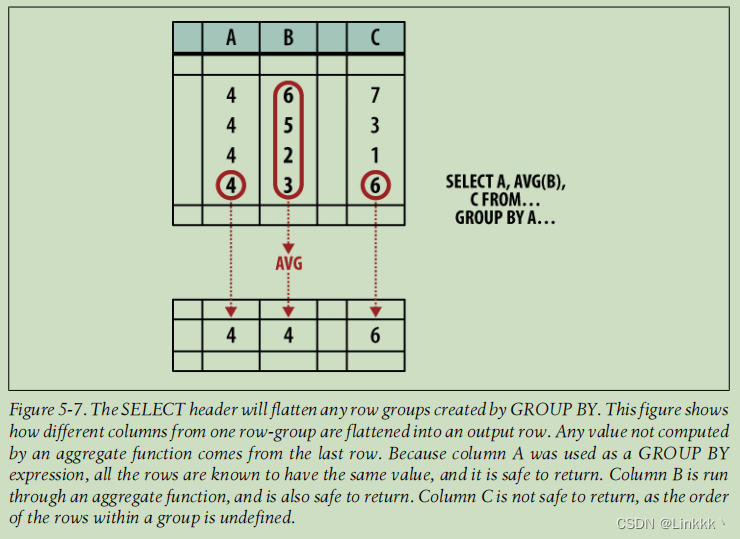
在某些情况下,从随机行中选择一个值并不是一件坏事。例如,如果 SELECT header 表达式也被用于 GROUP BY 表达式,我们知道组中的每个行都具有完全相等的值。无论你选择哪一行,你总会得到相同的值。
当 SELECT header 使用的列引用不是 GROUP BY 子句的一部分,或它没有被传递给某个聚合函数时,你可能会遇到麻烦。在这些情况下,无法确定输出值是什么。为了避免这样,当时用 GROUP BY 子句时,SELECT header 应当仅使用列引用作为聚合函数的输入,或者 header 表达式应该与 GROUP BY 子句中使用的表达式相匹配。例如:
SELECT col1, sum(col2) FROM tb1 GROUP BY col1;
虽然对于被用左分组的键的列或表达式来说,每一行都应该有相同的值,但这并不意味着这些值总是完全相同的。如果使用诸如 NOCASE 的排序规则,不同的值 (例如 ‘ABC’ 和 ‘abc’) 可能被认为是相等的。在这些情况下,没办法知道 SELECT header 中返回的值是哪个。例如:
CREATE TABLE tb1(t);
INSERT INTO t VALUES('ABC');
INSERT INTO t VALUES('abc');
SELECT t FROM tb1 GROUP BY t COLLATE NOCASE;
最后,如果 SELECT header 包含一个聚合函数,但是 SELECT 语句不包含一个 GROUP BY 子句,则整个工作表被视作一个组。因为 flattened 组总是返回一行,这会造成查询仅会返回一行,即使工作表不包含任何行。
HAVING 子句
功能上,HAVING 子句与 WHERE 子句相同。HAVING 子句由一个过滤表达式组成,过滤表达式对工作表中的每一行进行求值。任何求值结果为假或 NULL 的行呗过滤掉并移除。结果表具有相同的列数,但是行数可能更少。
WHERE 子句和 HAVING 子句间的主要不同点是它们在 SELECT 管道中出现的位置不同。HAVING 子句在 GROUP BY 和 SELECT 子句之后处理,这允许 HAVING 基于 GROUP BY 聚合的结果过滤行。HAVING 子句甚至能有它们自己的聚合,允许它们基于不是 SELECT header 中的部分的聚合结果进行过滤。
HAVING 子句应当仅包含依赖 GROUP BY 输出的过滤表达式。所有其他的过滤都应当由 WHERE 子句完成。
HAVING 和 WHERE 子句都能引用使用 AS 关键词定义于 SELECT header 中的结果行名。主要的不同是 WHERE 子句仅能引用不包含聚合函数的表达式,HAVING 子句能引用任何结果行。
DISTINCT 关键词
DISTINCT 关键词将扫面结果集,并剔除重复的行。这确保返回的行组成一个正确的集合。当确定行是否重复时,仅考虑 SELECT header 中指定的列和值。这是为数不多的 NULLs 被认为具有 “等价性” 的情况之一,重复的 NULLs 将被剔除。
因为 SELECT DISTINCT 必须将某行与其他所有行进行比较,这是一个昂贵的操作。在一个涉及良好的数据库中,很少需要这样的操作。因此它的使用并不常见。
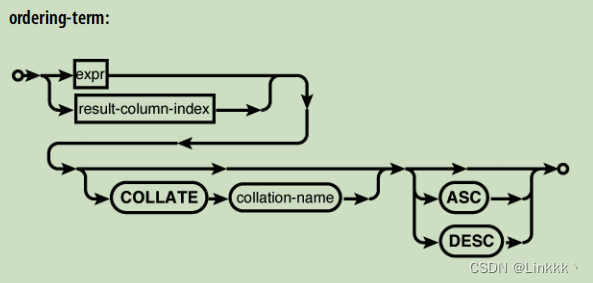
ORDER BY 子句
ORDER BY 子句被用于对结果表中的行进行排序。提供具有一个或多个排序表达式的列表。第一个表达式用于对表进行排序。第二个表达式用于对第一次排序后相等的行进行排序,如此反复。每个表达式都可以指定为增序或降序。
基本的 ORDER BY 子句的格式如下:
ORDER BY expression [COLLATE collation_name] [ASC|DESC] [,...]
表达式对每一行进行求值。表达式是一个简单的列引用的情况十分常见,但是它可以是任何表达式。结果值随后与其他行产生的结果值进行比较。如果有的话,使用命名的排序规则进行排序。排序规则为文本值定义了特殊的排序顺序。ASC 和 DESC 关键词指定排序为增序还是降序。默认情况下,使用默认的排序规则以增序的方式对值进行排序。
ORDER BY 表达式可以使用源列,包括哪些没有出现在查询结果中的源列。如同 GROUP BY,如果 ORDER BY 的表达式由字面量整数组成,它被假设为列的索引值。列索引从左侧列开始,起始值为 1。
数字值天然就由很好的排序顺序。文本值由当前活动的排序规则进行排序,BLOB 值总是使用 BINARY 排序规则进行排序。SQLite 有三种内置的排序函数。你可以使用 API 来定义你自己的排序函数。三个内置的排序方式是:
- BINARY: 根据 POSIX memcmp() 调用的语义对文本值进行排序。不考虑文本值的编码,本质上是将它视作一个大的二进制字符串。BLOB 值总是以这一排序规则进行存储。这是默认的排序规则。
- NOCASE:与 BINARY 相同,只是在比较完成前,所有的 ASCII 大写字符被转换为小写字符。大小写转换严格地在 7 位的 ASCII 值上执行。
- RTRIM:与 BINARY 相同,只是末尾的空格被忽略。
ORDER BY 十分有用,它应该仅在需要的时候使用,特别是对很大的结果表来说。虽然 SQLite 有时能使用索引来按序计算查询结果,在很多情况下,SQLite 必须首先计算出整个结果集,然后在行返回前对它进行排序。在这种情况下,中间的结果表必须存储在内存或硬盘中,直到完全计算完毕,然后进行排序。
总之,很多情况下 ORDER BY 是合理的,但是不必要。注意使用它是有一些重大的成本,不应该随意的使用它。
LIMIT 和 OFFSET 子句
LIMIT 和 OFFSET 子句允许你提前最终结果表中的行的特定子集。LIMIT 定义将要返回的行的最大数量,OFFSET 定义在返回第一行前跳过的行数。如果没有提供 OFFSET,LIMIT 被应用于表的顶部。如果提供了一个负的 LIMIT,LIMIT 被移除,且将返回整个表。
有三种定义 LIMIT 和 OFFSET 的方法:
LIMIT limit_count
LIMIT limit_count OFFSET offset_count
LIMIT offset_count, limit_count
注意 OFFSET 值定义跳过的行数,不是第一行的位置。
虽然不是严格需要的,你在使用 LIMIT 时通常想要定义一个 ORDER BY。没有 ORDER BY,就没有良好定义顺序的结果,使限制和偏移稍微有点没有意义。















 4180
4180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









