







在日常生活中,我们经常需要使用百度图片来搜索相关的图片资源。而如果需要大量获取特定关键字的图片资源,手动一个个下载无疑十分繁琐且费时费力。因此,本文将介绍如何通过Python爬虫技术,自动化地获取百度图片。
要爬取的是百度图片,大概的思路就是得到要爬取的url、拿到网页源码、得到图片链接、保存图片。在做这些工作之前,我们要先导入需要的第三方库requests、re和os。下面我将教你如何一步一步实现。
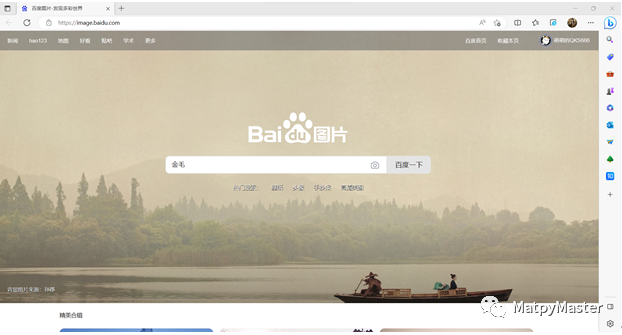
(1)打开百度图片首页百度图片-发现多彩世界 (baidu.com),输入金毛进行搜索:
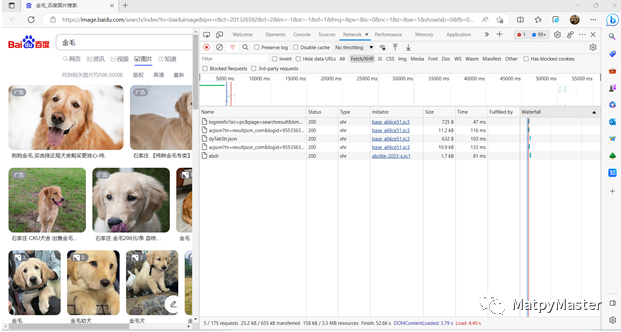
(2)右键鼠标,选择检查,依次点击Network→Fetch/XHR,然后刷新一下网页:
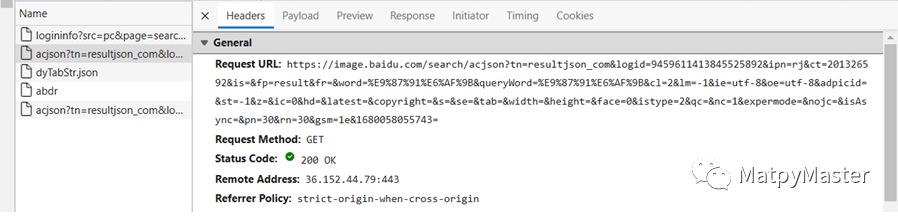
(3)点击以acjson开头的一行,查看Headers,可以看到Request URL信息如下:
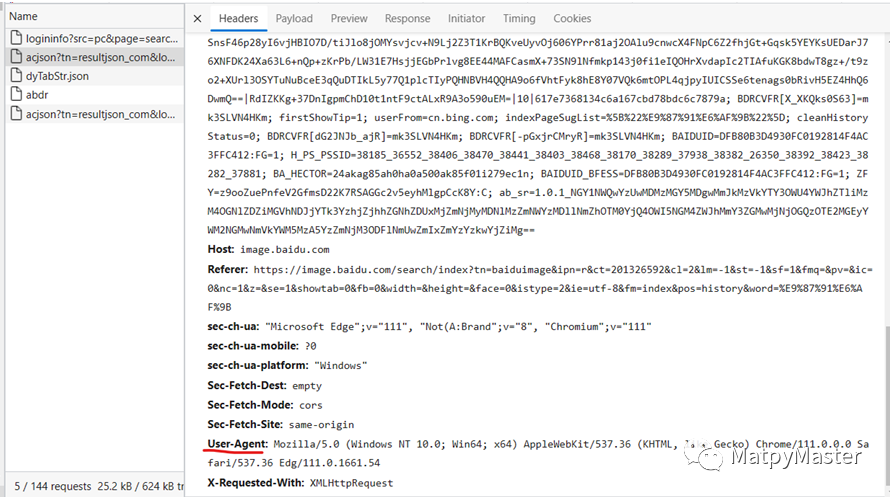
(4)一直往下滑,在底部就是User-Agent:
完整的源代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 29 10:17:50 2023
@author: MatpyMaster
"""
import requests
import os
import re
def get_images_from_baidu(keyword, page_num, save_dir):
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
# 请求的 url
url = 'https://image.baidu.com/search/acjson?'
n = 0
for pn in range(0, 30 * page_num, 30):
# 请求参数
param = {'tn': 'resultjson_com',
'logid': '7603311155072595725',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': '', # 这个参数没公开,但是不可少
'pn': pn, # 显示:30-60-90
'rn': '30', # 每页显示 30 条
'gsm': '1e',
'1618827096642': ''
}
request = requests.get(url=url, headers=header, params=param)
if request.status_code == 200:
print('Request success.')
request.encoding = 'utf-8'
# 正则方式提取图片链接
html = request.text
image_url_list = re.findall('"thumbURL":"(.*?)",', html, re.S)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for image_url in image_url_list:
image_data = requests.get(url=image_url, headers=header).content
with open(os.path.join(save_dir, f'{n:06d}.jpg'), 'wb') as fp:
fp.write(image_data)
n = n + 1
if __name__ == "__main__":
keyword = '金毛'
page_num = 1
page_num = int(page_num)
save_dir = '.\\图片\\'+keyword
get_images_from_baidu(keyword, page_num, save_dir)设置好关键字keyword和爬取页数page_num,运行代码就可以了,最后会在将爬取的图片以关键字为名创建一个文件夹保存至图片文件夹。
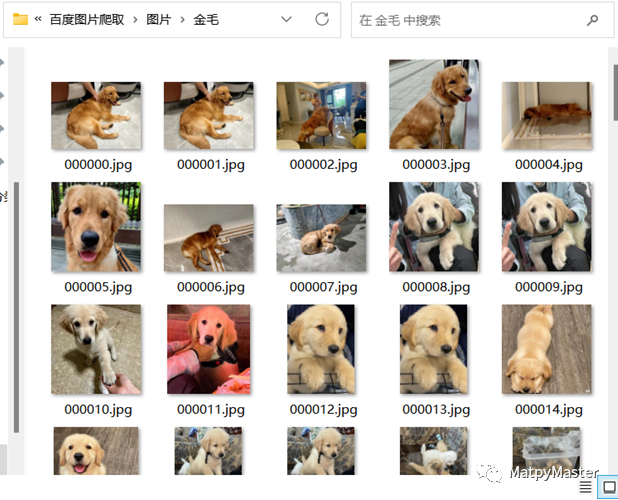
最后:
如果你想要进一步了解Python爬虫的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!



















 2415
2415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











