







一.文本情感分类基础
1.文本的tokenization
将原始文本切分成子单元的过程就叫做tokenization,tokenization就是通常所说的分词,分出的每一个词语我们把它称为token。常用的分词工具有很多,比如:jieba分词(https://github.com/fxsjy/jieba)。
2.N-garm表示
N-Gram是自然语言处理中一个非常重要的概念,通常在NLP中,人们基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理。N-Gram的另外一个作用是用来评估两个字符串之间的差异程度。
import jieba
text = 'N-Gram是自然语言处理中一个非常重要的概念'
cuted = jieba.lcut(text)
print(cuted)
cuted_list = [cuted[i: i+2] for i in range(len(cuted)-1)]
print(cuted_list)在传统的机器学习中,使用N-gram方法往往能够取得非常好的效果,但是在深度学习比如RNN中会自带N-gram的效果。
3.文本向量化
(1).one-hot编码
在one-hot编码中,每一个token使用一个长度为N的向量表示,N表示词典的数量。即把待处理的文档进行分词或者是N-gram处理,然后进行去重得到词典,假设有一个文档“深度学习”,进行one-hot处理后的结果如下。

(2).word embedding
word embedding使用了浮点型的稠密矩阵来表示token。根据词典的大小,我们的向量通常使用不同的维度,例如100,256,300等。其中向量中的每一个值是一个参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得。如果我们文本中有20000个词语,使用word embedding来表示的话,只需要维度20000*300。形象的表示如下。
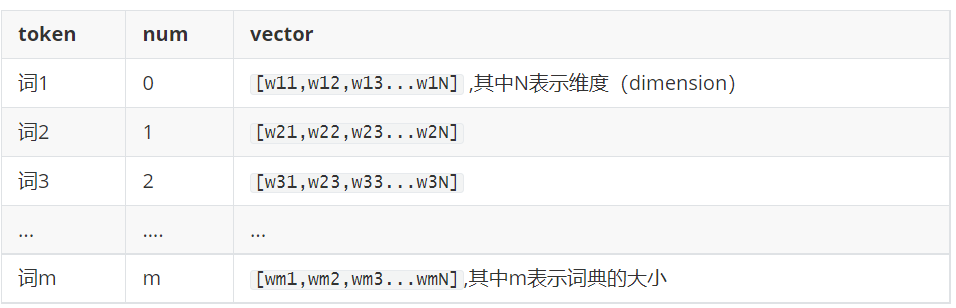
先把token使用数字来表示,再把数字使用向量来表示。即:token---> num ---->vector。
(3).word embedding API
import torch
# num_embeddings:词典的大小
# embedding_dim:embedding的维度
embedding = torch.nn.Embedding(vocab_size,300) #实例化
input_embeded = embedding(input) #进行embedding的操作(4).数据的形状变化
每个batch中的每个句子有10个词语,经过形状为[20,4]的Word emebedding之后,每个词语用长度为4的向量表示,所以,最终句子会变为[batch_size,10,4]的形状。增加了一个维度,这个维度是embedding的dim
二.文本情感分类的实现
1.案例介绍
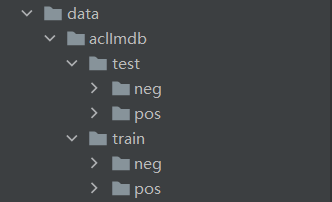
为了对前面的word embedding这种常用的文本向量化的方法进行巩固,这里我们会完成一个文本情感分类的案例,采用的是IMDB数据集:http://ai.stanford.edu/~amaas/data/sentiment/,这是一份包含了5万条流行电影的评论数据,其中训练集25000条,测试集25000条,每个数据集包含neg和pos两类。数据格式如下:txt文件的名称名称包含两部分,分别是序号和情感评分,(1-4为neg,5-10为pos),txt内容为评论内容。
2.思路分析
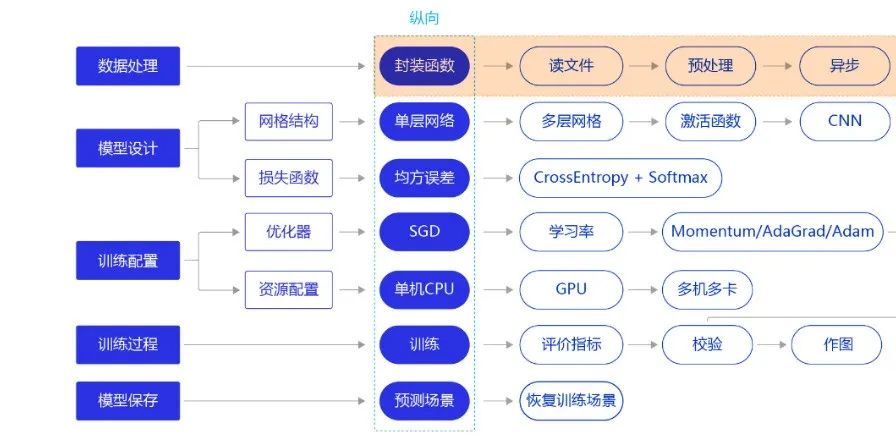
首先可以把上述问题定义为分类问题,情感评分分为1-10,10个类别(也可以理解为回归问题,这里当做分类问题考虑)。那么根据之前的经验,我们的大致流程如下:准备数据集、构建模型、模型训练、模型评估。
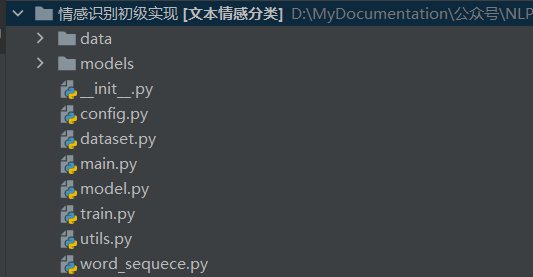
完整代码目录:
3.准备数据集
(1).定义tokenize的方法(utils.py)
import re
def tokenlize(sentence):
"""
进行文本分词
:param sentence: str
:return: [str,str,str]
"""
fileters = ['!', '"', '#', '$', '%', '&', '\(', '\)', '\*', '\+', ',', '-', '\.', '/', ':', ';', '<', '=', '>',
'\?', '@', '\[', '\\', '\]', '^', '_', '`', '\{', '\|', '\}', '~', '\t', '\n', '\x97', '\x96', '”', '“', ]
sentence = sentence.lower() #把大写转化为小写
sentence = re.sub("<br />"," ",sentence)
# sentence = re.sub("I'm","I am",sentence)
# sentence = re.sub("isn't","is not",sentence)
sentence = re.sub("|".join(fileters)," ",sentence)
result = [i for i in sentence.split(" ") if len(i)>0]
return result(2).配置文件(config.py)
import pickle
train_batch_size = 512
test_batch_size = 500
ws = pickle.load(open("./models/ws.pkl","rb"))
max_len = 50(3).准备dataset(dataset.py)
from torch.utils.data import DataLoader,Dataset
import torch
import os
import utils
import config
class ImdbDataset(Dataset):
def __init__(self,train=True):
# super(ImdbDataset,self).__init__()
data_path = r"data\aclImdb"
data_path += r"\train" if train else r"\test"
self.total_path = [] #保存所有的文件路径
for temp_path in [r"\pos",r"\neg"]:
cur_path = data_path + temp_path
self.total_path += [os.path.join(cur_path,i) for i in os.listdir(cur_path) if i.endswith(".txt")]
def __getitem__(self, idx):
file = self.total_path[idx]
review = utils.tokenlize(open(file, encoding='utf-8').read())
label = int(file.split("_")[-1].split(".")[0])
label = 0 if label <5 else 1
return review,label
def __len__(self):
return len(self.total_path)
def collate_fn(batch):
"""
对batch数据进行处理
:param batch: [一个getitem的结果,getitem的结果,getitem的结果]
:return: 元组
"""
reviews,labels = zip(*batch)
reviews = torch.LongTensor([config.ws.transform(i,max_len=config.max_len) for i in reviews])
labels = torch.LongTensor(labels)
return reviews,labels
def get_dataloader(train=True):
dataset = ImdbDataset(train)
batch_size = config.train_batch_size if train else config.test_batch_size
return DataLoader(dataset,batch_size=batch_size,shuffle=True,collate_fn=collate_fn)
if __name__ == '__main__':
for idx,(review,label) in enumerate(get_dataloader(train=True)):
print(idx)
print(review)
print(label)
break(4).文本序列化(word_sequece.py)
class WordSequence:
UNK_TAG = "<UNK>" #表示未知字符
PAD_TAG = "<PAD>" #填充符
PAD = 0
UNK = 1
def __init__(self):
self.dict = { #保存词语和对应的数字
self.UNK_TAG:self.UNK,
self.PAD_TAG:self.PAD
}
self.count = {} #统计词频的
def fit(self,sentence):
"""
接受句子,统计词频
:param sentence:[str,str,str]
:return:None
"""
for word in sentence:
self.count[word] = self.count.get(word,0) + 1 #所有的句子fit之后,self.count就有了所有词语的词频
def build_vocab(self,min_count=5,max_count=None,max_features=None):
"""
根据条件构造 词典
:param min_count:最小词频
:param max_count: 最大词频
:param max_features: 最大词语数
:return:
"""
if min_count is not None:
self.count = {word:count for word,count in self.count.items() if count >= min_count}
if max_count is not None:
self.count = {word:count for word,count in self.count.items() if count <= max_count}
if max_features is not None:
#[(k,v),(k,v)....] --->{k:v,k:v}
self.count = dict(sorted(self.count.items(),lambda x:x[-1],reverse=True)[:max_features])
for word in self.count:
self.dict[word] = len(self.dict) #每次word对应一个数字
#把dict进行翻转
self.inverse_dict = dict(zip(self.dict.values(),self.dict.keys()))
def transform(self,sentence,max_len=None):
"""
把句子转化为数字序列
:param sentence:[str,str,str]
:return: [int,int,int]
"""
if len(sentence) > max_len:
sentence = sentence[:max_len]
else:
sentence = sentence + [self.PAD_TAG] *(max_len- len(sentence)) #填充PAD
return [self.dict.get(i,1) for i in sentence]
def inverse_transform(self,incides):
"""
把数字序列转化为字符
:param incides: [int,int,int]
:return: [str,str,str]
"""
return [self.inverse_dict.get(i,"<UNK>") for i in incides]
def __len__(self):
return len(self.dict)
if __name__ == '__main__':
# sentences = [["今天","天气","很","好"],
# ["今天","去","吃","什么"]]
# ws = WordSequence()
# for sentence in sentences:
# ws.fit(sentence)
# ws.build_vocab(min_count=1)
# print(ws.dict)
# ret = ws.transform(["好","好","好","好","好","好","好","热","呀"],max_len=3)
# print(ret)
# ret = ws.inverse_transform(ret)
# print(ret)
pass4.构建模型(model.py)
这里使用word embedding,所以模型只有一层,即数据经过word embedding。通过全连接层返回结果,计算log_softmax。
import torch.nn as nn
import config
import torch.nn.functional as F
class ImdbModel(nn.Module):
def __init__(self):
super(ImdbModel,self).__init__()
self.embedding = nn.Embedding(num_embeddings=len(config.ws),embedding_dim=200,padding_idx=config.ws.PAD)
self.fc = nn.Linear(config.max_len*200,2)
def forward(self, input):
"""
:param input:[batch_size,max_len]
:return:
"""
input_embeded = self.embedding(input) #input embeded :[batch_size,max_len,200]
#变形
input_embeded_viewed = input_embeded.view(input_embeded.size(0),-1)
#全连接
out = self.fc(input_embeded_viewed)
return F.log_softmax(out,dim=-1)5.模型训练和评估(train.py)
设计实例化模型,损失函数,优化器。遍历dataset_loader,梯度置为0,进行向前计算。计算损失,反向传播优化损失,更新参数。
import torch
from model import ImdbModel
from dataset import get_dataloader
from torch.optim import Adam
from tqdm import tqdm
import torch.nn.functional as F
model = ImdbModel()
optimizer = Adam(model.parameters())
def train(epoch):
print("epcoh:{}".format(epoch))
train_dataloader = get_dataloader(train=True)
bar = tqdm(train_dataloader, total=len(train_dataloader))
correct = 0
total = 0
for idx, (input, target) in enumerate(bar):
optimizer.zero_grad()
output = model(input)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
# 计算准确率
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
total += target.shape[0]
acc = correct / total
bar.set_description("Train:idx:{} loss:{:.6f} acc:{:.4f}".format(idx, loss.item(), acc))
# 加上测试集代码
def test():
test_dataloader = get_dataloader(train=False)
bar = tqdm(test_dataloader, total=len(test_dataloader))
correct = 0
total = 0
for idx, (input, target) in enumerate(bar):
with torch.no_grad():
output = model(input)
loss = F.nll_loss(output, target)
# 计算准确率
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
total += target.shape[0]
acc = correct / total
bar.set_description("Test:idx:{} loss:{:.6f} acc:{:.4f}".format(idx, loss.item(), acc))
if __name__ == '__main__':
for i in range(10):
train(i)
test()
这里我们仅仅使用了一层全连接层,所以其分类效果不会很好,重点是理解常见的模型流程和word embedding的使用方法。后续小编会整理基于卷积神经网络的方法,敬请期待!
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!

















 733
733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











