







前言
AI绘画工具的发展历史可以追溯到2014年,当时生成对抗网络模型(GAN)被首次用于图片生成。GAN模型由Ian Goodfellow提出,其核心思想是让两个内部程序 “生成器 (generator)” 和"判别器 (discriminator)" 互相博弈,从而达到生成逼真图片的效果。随着时间的推移,越来越多的AI绘画工具被开发出来,例如Stable Diffusion(SD)和Midjourney。其中,Stable Diffusion是2022年发布的深度学习文本到图像生成模型,它是一种潜在扩散模型。而Midjourney则是一款由总部位于旧金山的独立研究实验室Midjourney, Inc.创建和托管的人工智能程序和服务。Midjourney基于Discord平台提供服务,可以根据自然语言描述(称为“提示”)生成图像,也支持图生图功能。Stable Diffusion和Midjourney都能够通过prompt(提示词)来进行文生图 ,或是 图生图 的方式来生成想要的图片。
AI绘画模型发展如此迅速,而且使用场景如此之广,很多小伙伴肯定都已经按捺不住了,纷纷表示,自己要体验一波,众所周知,Midjourney官网在海外,想要随时访问来用,还是不太方便的。但是Stable Diffusion 可是提供了开源的包,而且有一大堆教程叫你如何跑起来的。
我想你肯定是已经做过了尝试,第一批被劝退的就是,昂贵的显卡价格。另外一批人不差钱,买到了显卡,然而被各种环境搭建折腾到发际线都后移了0.1cm,最终放弃。 还有残存的一批人终于搭建好可以用了,又被本地搭建的服务,外网无法随时访问给折腾疯了。
没错,我就是这些人其中的一部分!!!
现在这些烦恼统统都没了!因为 腾讯云HAI服务器 它来了!
智能选型
根据应用匹配推选GPU算力资源,实现最高性价比。同时,打通必备云服务组件,大幅简化云服务配置流程。
一键部署
分钟级自动构建LLM、AI作画等应用环境。提供多种预装模型环境,包含如StableDiffusion、ChatGLM等热门模型。
可视化界面
提供开发者友好的图形界面,支持jupyterlab、webui等多种算力连接方式,AI研究调试超低门槛。
它将所有的复杂繁琐流程都打包进去,让用户只需轻松点击几下便可完成搭建,享受服务。并且是按时计费,把你的钱都花在刀刃上。
接下来就让我带领你们学习一下如何使用腾讯云HAI服务器搭建自己的AI绘画大模型,并且生成自己喜欢的图片吧!
环境准备
高性能应用服务 HAI资格申请
1 . 点击链接进入 高性能应用服务 HAI 申请体验资格
2. 等待审核通过后,进入 高性能应用服务 HAI
3. 点击 前往体验HAI 即可进入控制台。
购买HAI高性能服务
1.在控制台点击新建,进入选择AI模型以及其他参数的页面。
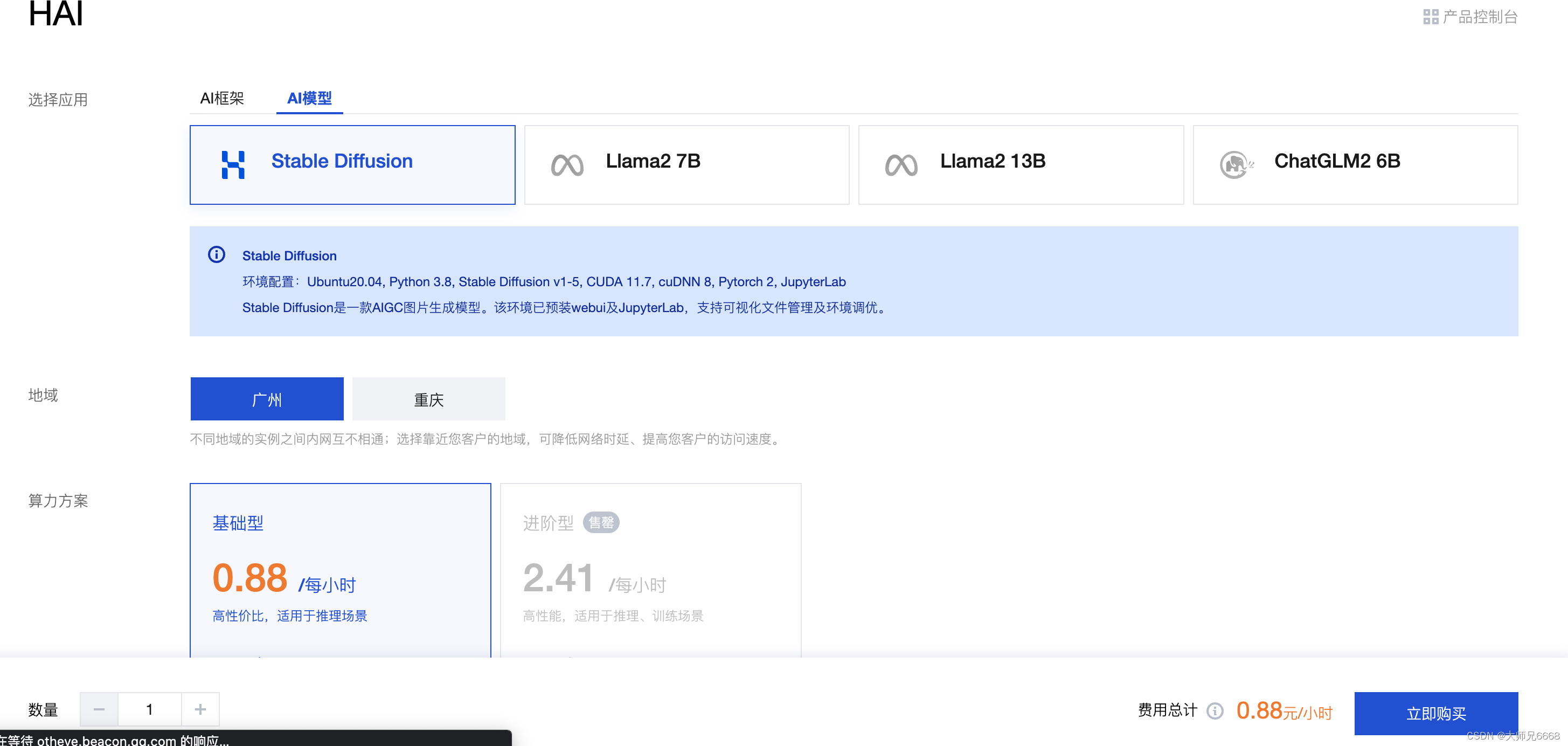
2.在页面中,应用选择AI模型,地域和算力方案,填写这个实例的名称(自己给自己的这个服务器起个名,方便辨认),然后根据需要选择硬盘容量以及数量,然后点击立即购买,就会开始进行创建。
3.购买成功后,HAI服务就开始自动部署相应的环境了,稍等5~10分钟,即可创建成功。
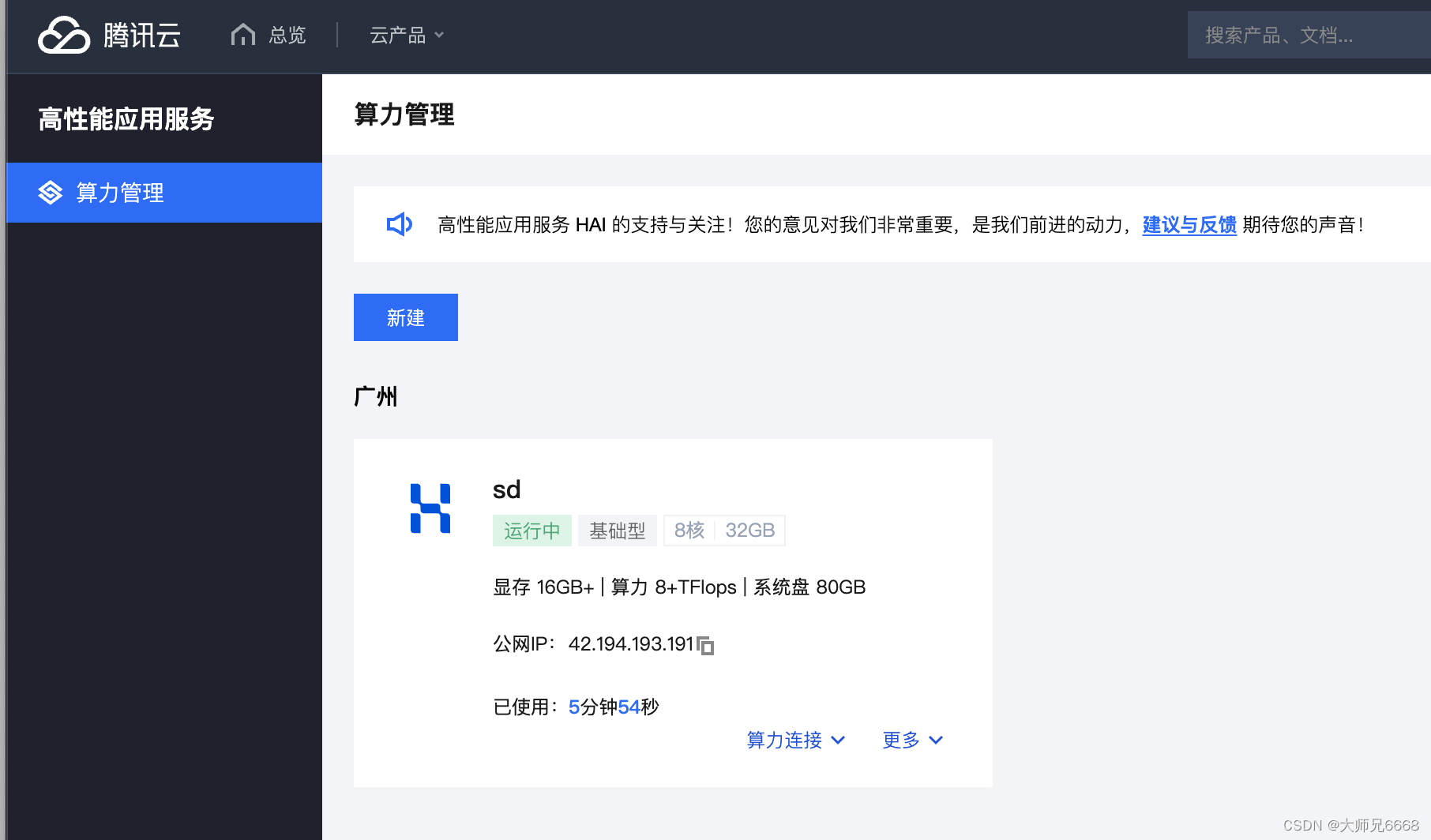
4.服务创建成功之后,点击算力链接,选择下方的stable_diffusion_webui即可进入我们熟悉的页面。
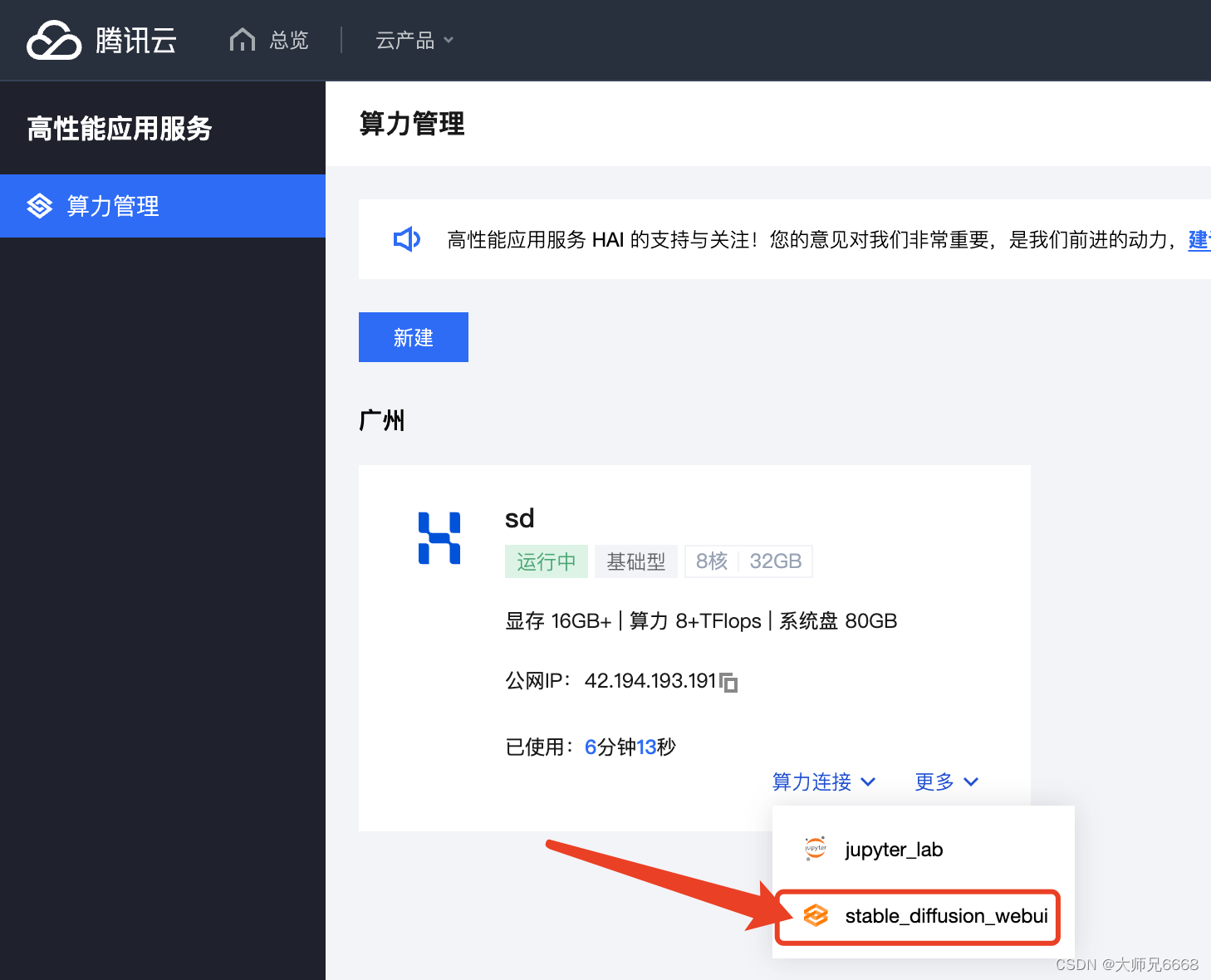
至此,准备工作就完成啦!接下来开始准备生成自己喜欢的图片吧!
生成图片
界面汉化:
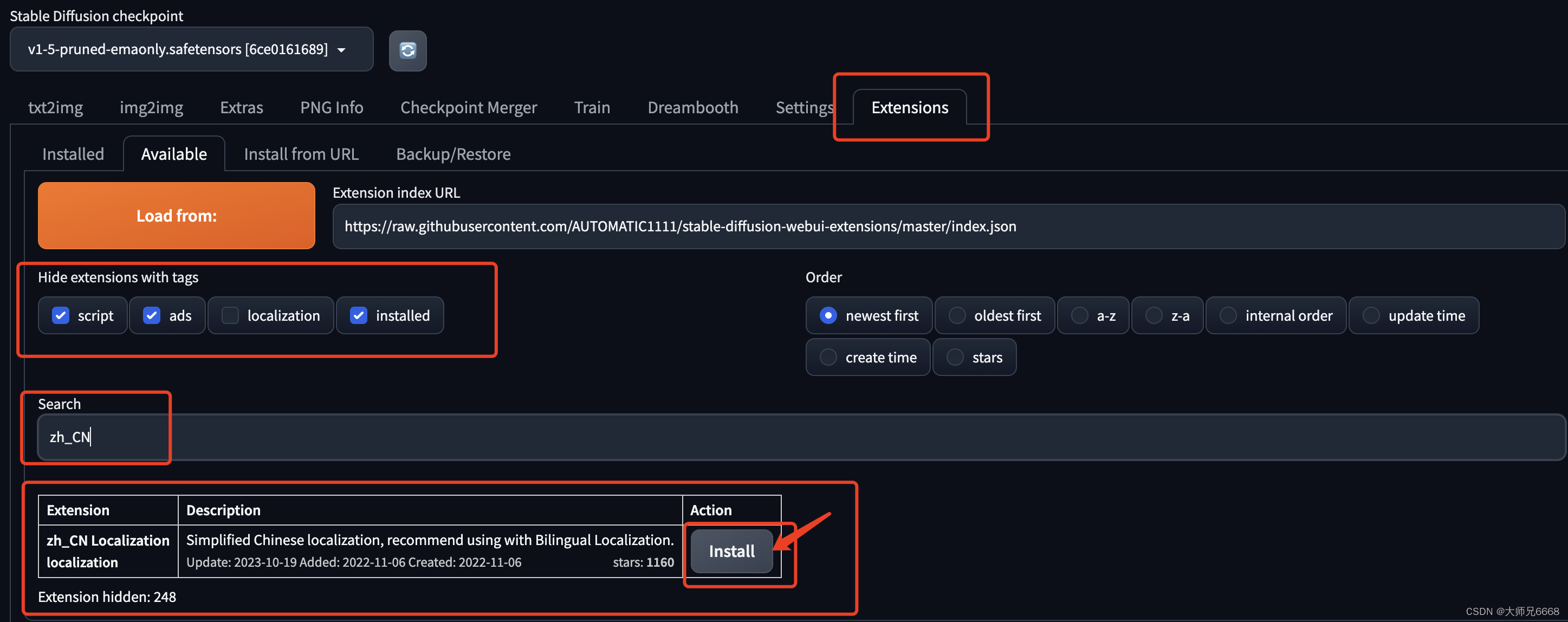
按照以下截图中的操作,依次进行,点击install之后,就安装了汉化插件。
然后在设置中,重启UI,这个插件就可以生效。

重启完成之后,你会发现还是英文的,别慌,现在已经有选项可以设置成中文的了。
按照以下步骤:
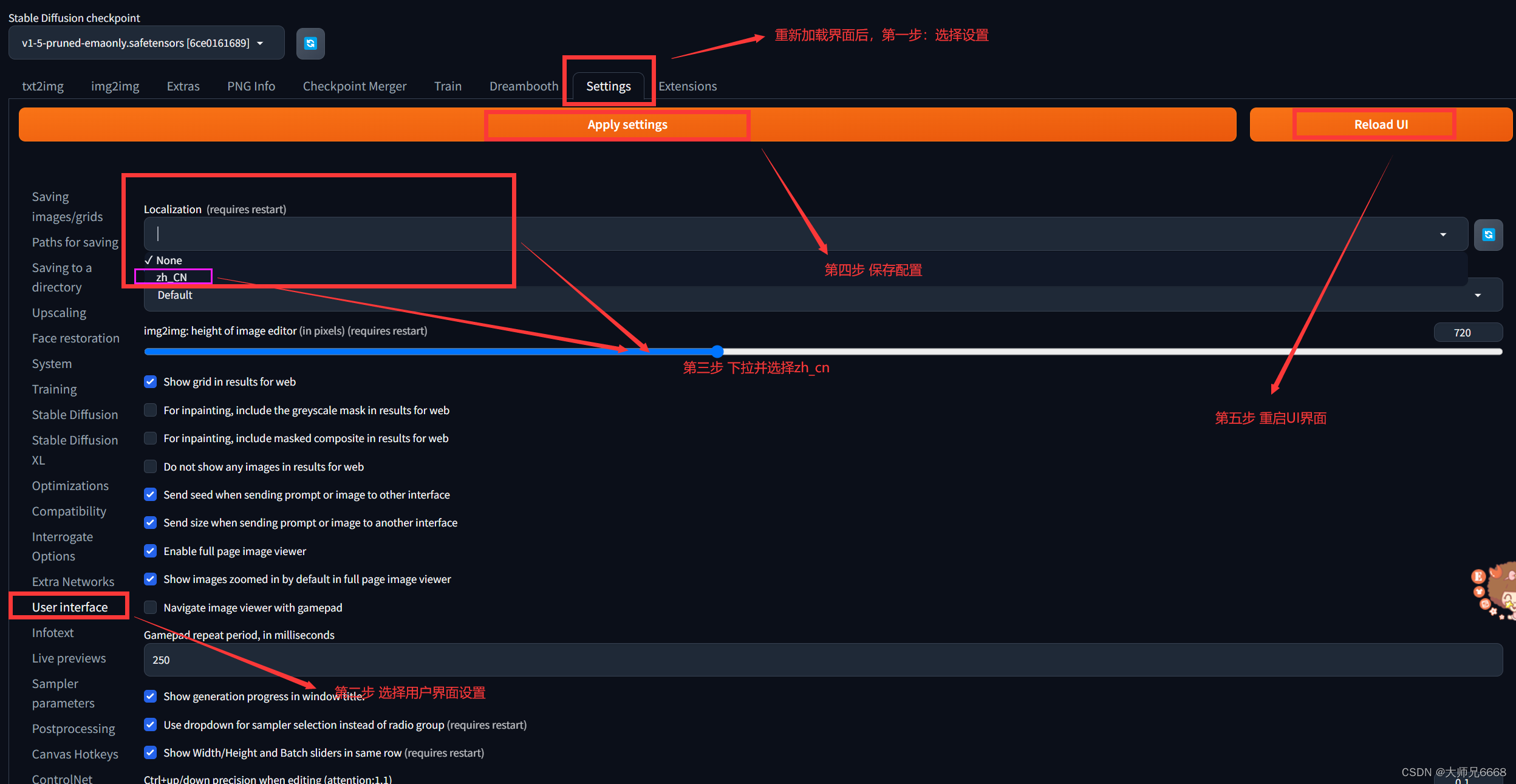
选中zh_CN之后,应用设置,然后重启UI界面,现在就变成了中文版的界面!
让我们来重新认识一下:
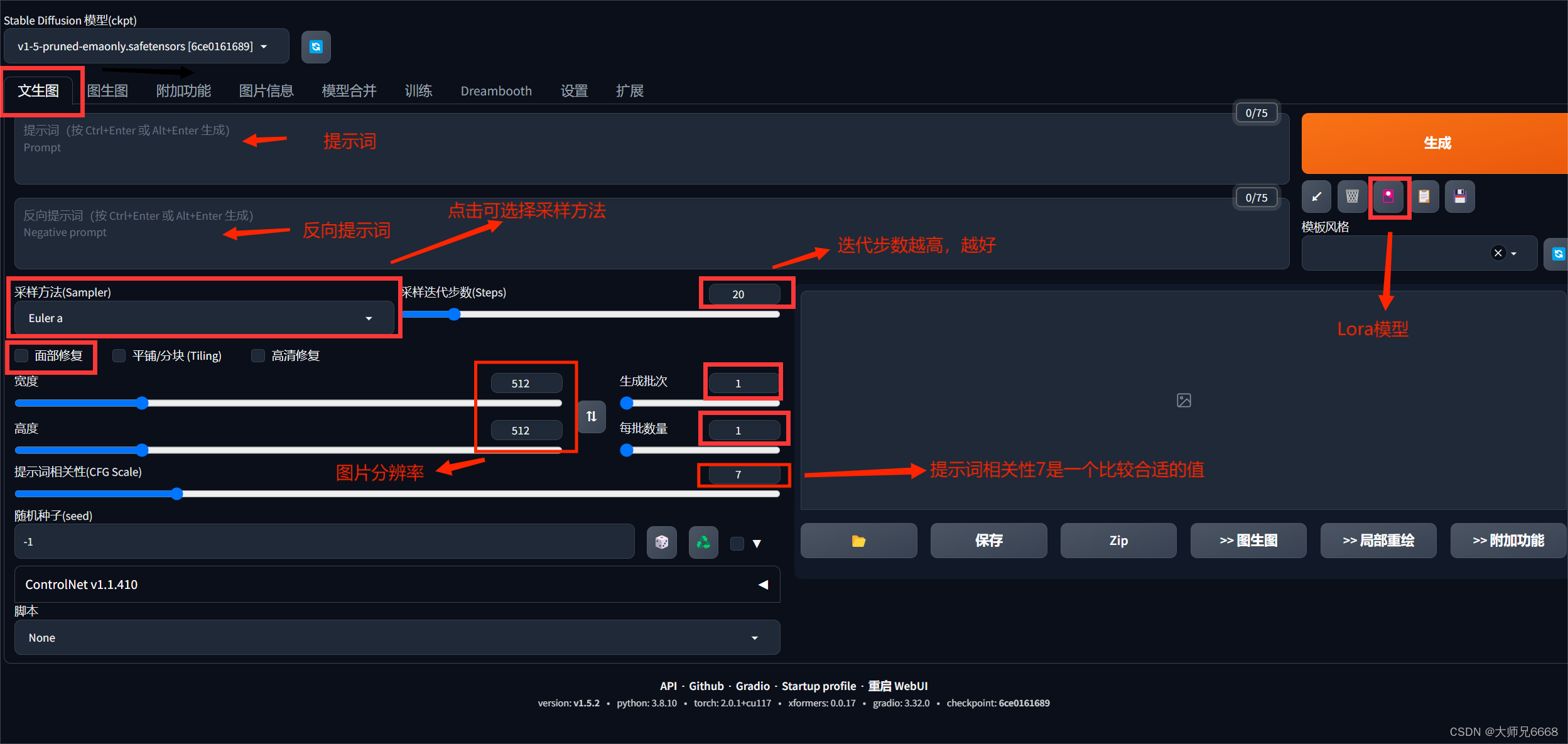
输入提示词生成图片
参数列表:
| 参数名 | 描述 |
|---|---|
| 提示词 | 主要描述图像,包括内容风格等信息,原始的webui会对这个地方有字数的限制,可以安装一些插件突破字数的限制 |
| 反向提示词 | 为了提供给模型,我们不需要的风格 |
| 提示词相关性(CFG scale) | 分类器自由引导尺度——图像与提示符的一致程度——越低的值产生的结果越有创意,数值越大成图越贴近描述文本。一般设置为7 |
| 采样方法(Sampling method) | 采样模式,即扩散算法的去噪声采样模式会影响其效果,不同的采样模式的结果会有很大差异,一般是默认选择euler,具体效果我也在逐步尝试中。 |
| 采样迭代步数(Sampling steps) | 在使用扩散模型生成图片时所进行的迭代步骤。每经过一次迭代,AI就有更多的机会去比对prompt和当前结果,并作出相应的调整。需要注意的是,更高的迭代步数会消耗更多的计算时间和成本,但并不意味着一定会得到更好的结果。然而,如果迭代步数过少,则图像质量肯定会下降 |
| 随机种子(Seed) | 随机数种子,生成每张图片时的随机种子,这个种子是用来作为确定扩散初始状态的基础。不懂的话,用随机的即可 |
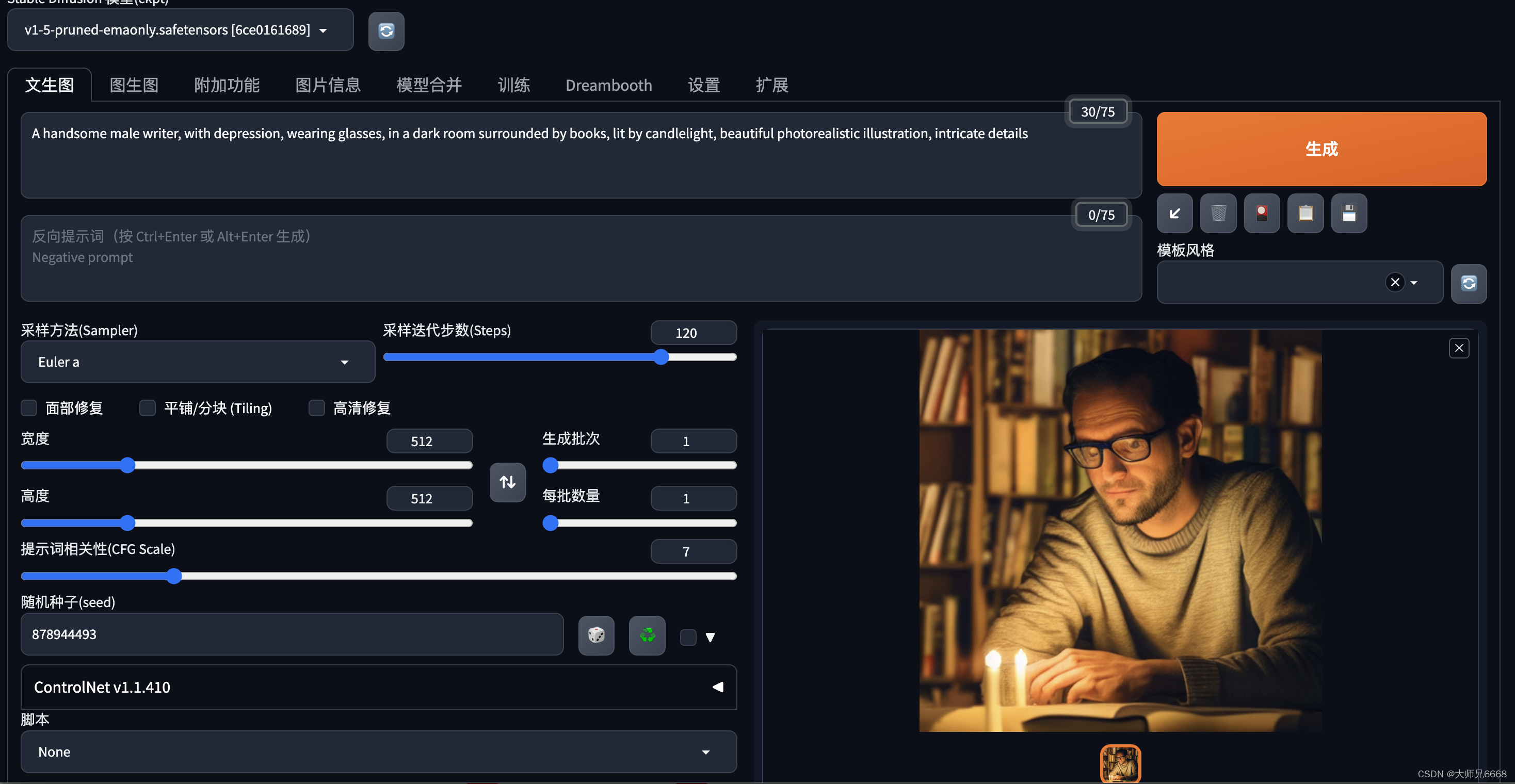
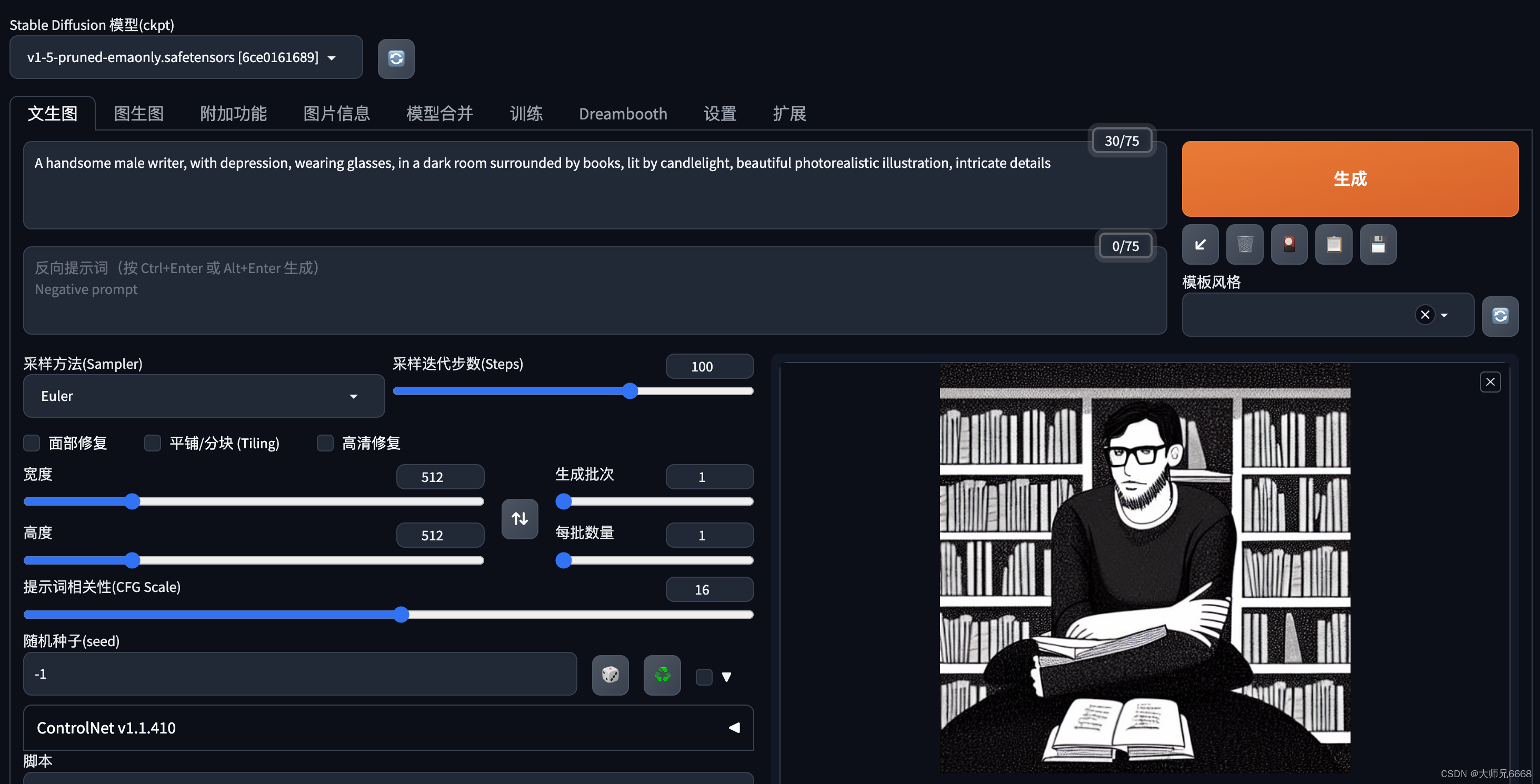
根据提示词生成图片
下面给大家提供几组提示词:
1.孤独之灵:
A handsome male writer, with depression, wearing glasses, in a dark room surrounded by books, lit by candlelight, beautiful photorealistic illustration, intricate details
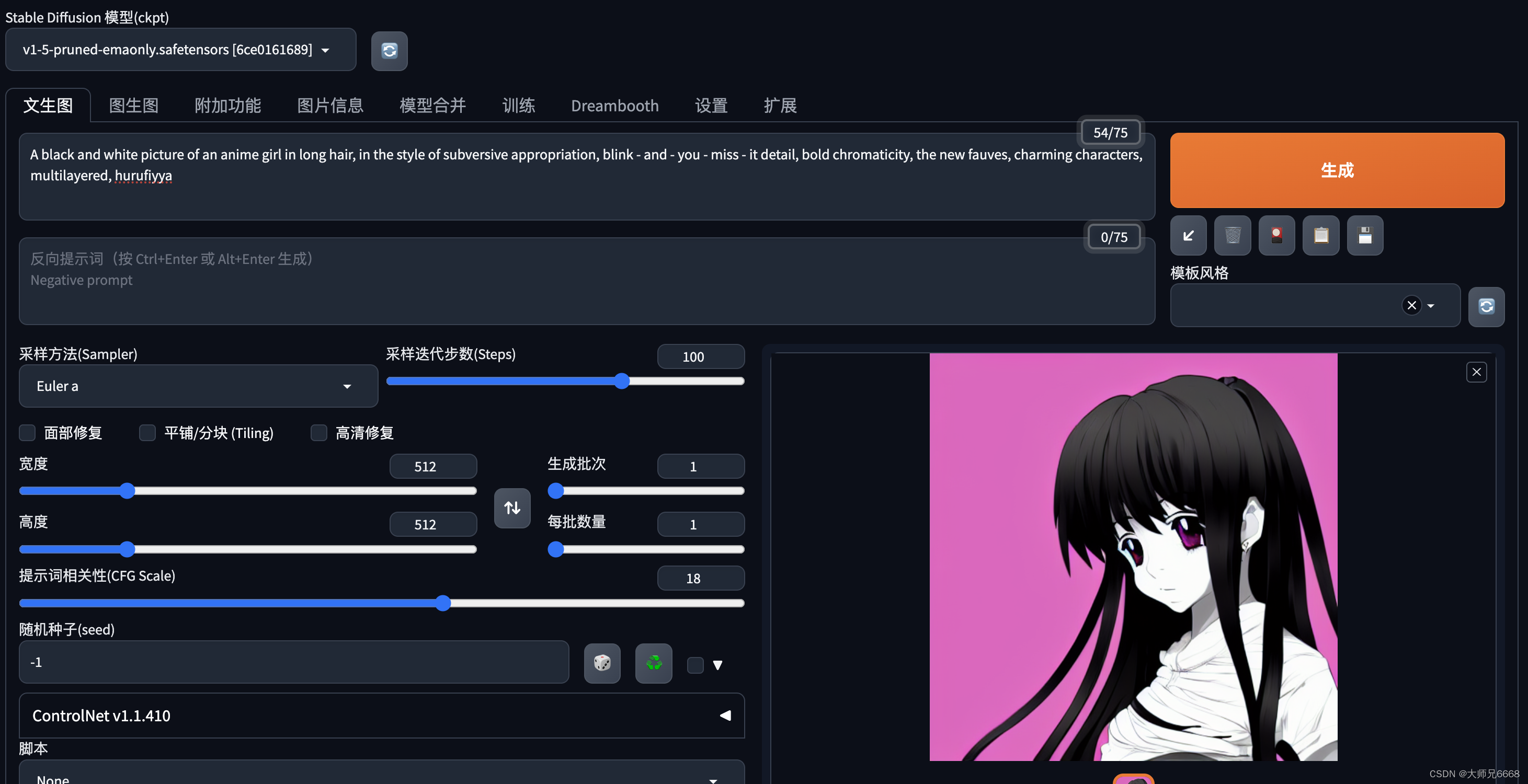
2.斑驳现实中的黑白动漫少女
A black and white picture of an anime girl in long hair, in the style of subversive appropriation, blink - and - you - miss - it detail, bold chromaticity, the new fauves, charming characters, multilayered, hurufiyya
3.机械哲思者
Create a hyper-realistic, 4K, lifelike digital image that show a humanoid robot in a exact position as The Thinker, by Rodin

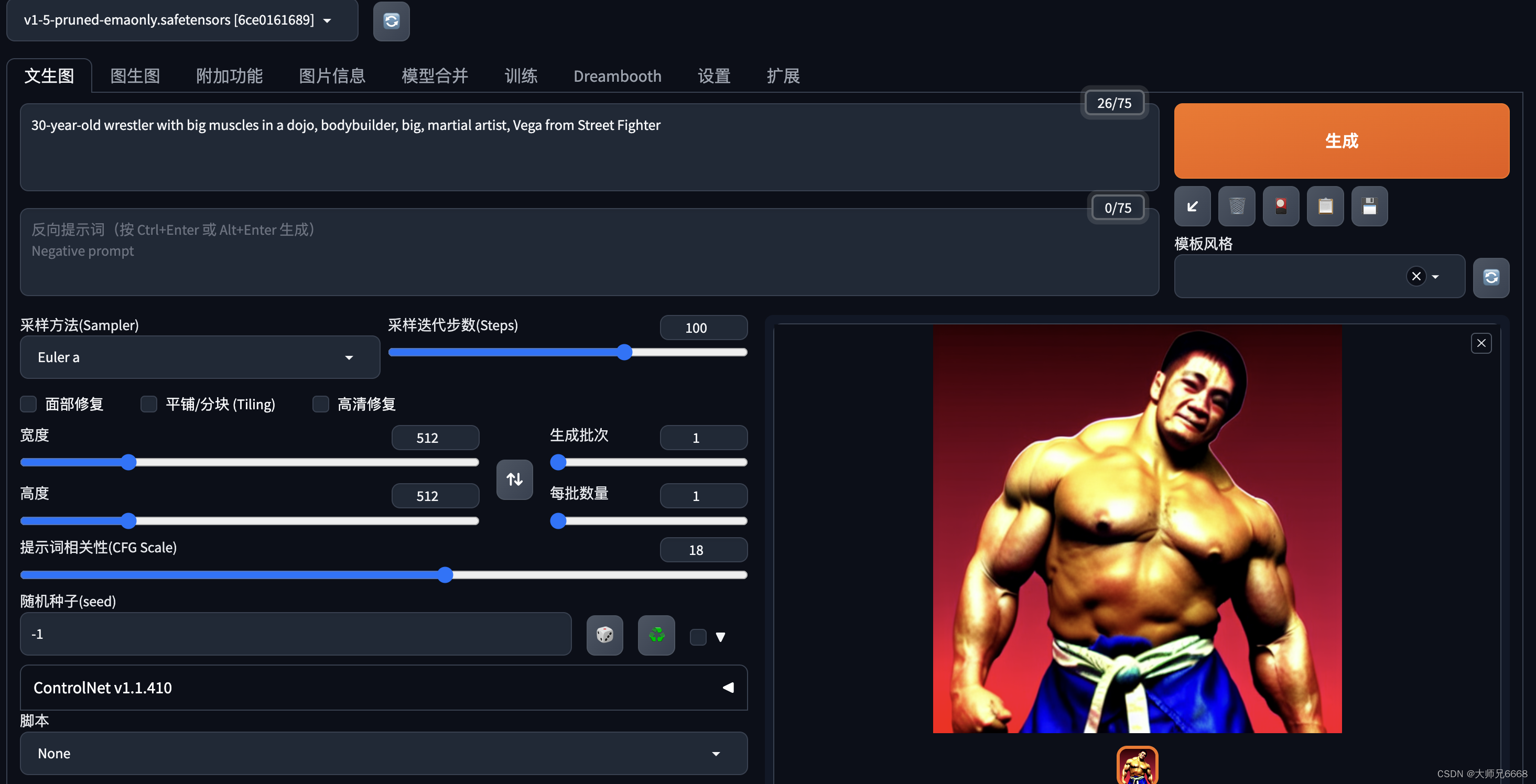
铁肌铜墙
30-year-old wrestler with big muscles in a dojo, bodybuilder, big, martial artist, Vega from Street Fighter
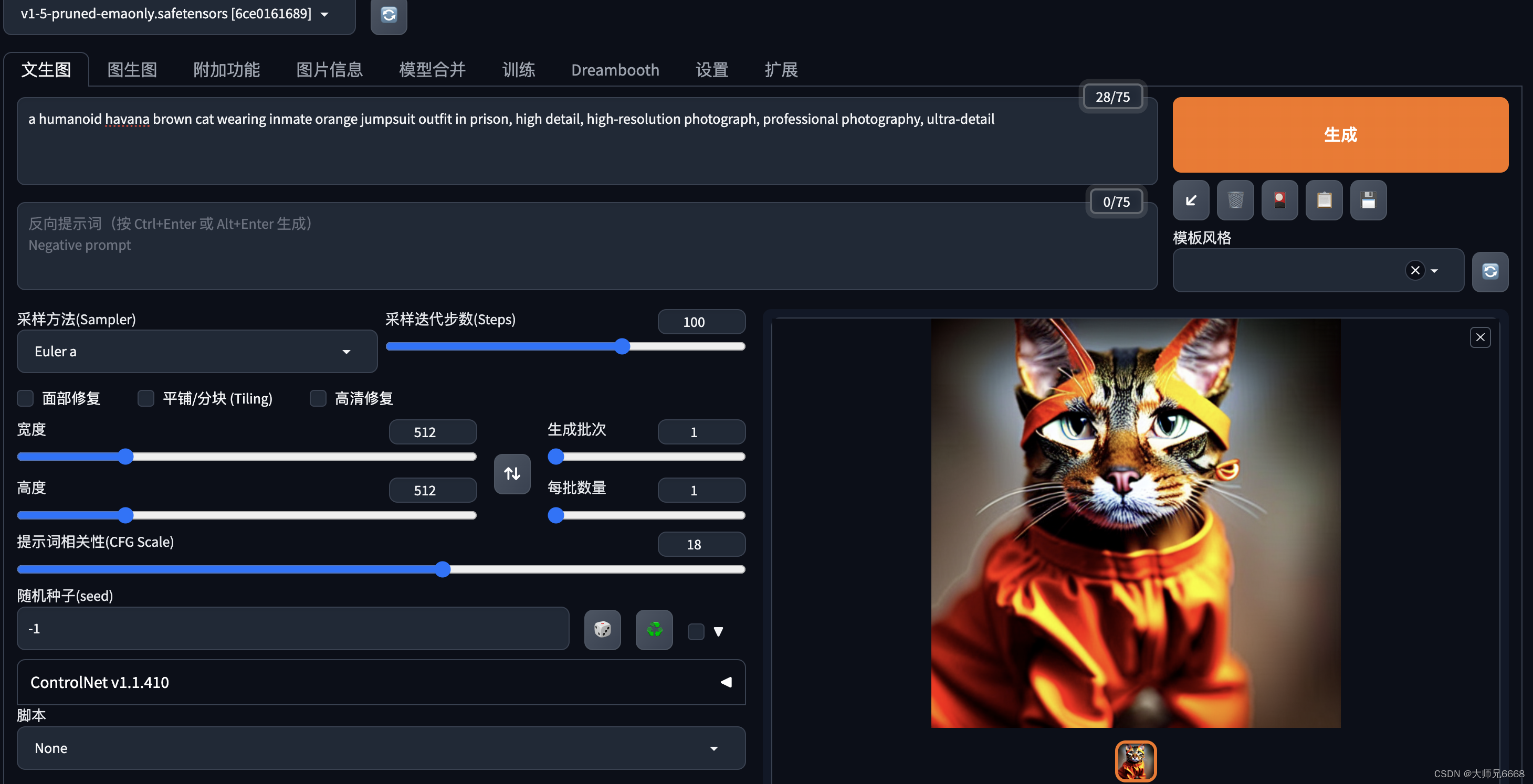
禁锢的叛逆
a humanoid havana brown cat wearing inmate orange jumpsuit outfit in prison, high detail, high-resolution photograph, professional photography, ultra-detail

总结:
腾讯云 HAI 服务整体表现非常顺畅,极其高效地支持用户搭建各种大型模型服务和环境。在当前市场需求不断增加的情况下,该服务具有巨大的发展前景。在我的使用过程中,我发现该服务存在一些优势和缺点,以下是我的总结:
优点:
1.操作简便,门槛低,傻瓜式购买和使用。
2.上限高,提供了各种大型模型所需的工具和功能,包括微调模型和终端编程等。
3.精确计费(按小时),真正实现了精打细算。
缺点:
1.人脸修复功能不稳定,使用后系统会死机,必须重启才能继续使用。
2.提供的绘图模型只有一个,希望能增加更多预置的模型可供选择。
3.使用过程中不能暂停,如果需要稍后再用,也得一直开着,但是这样就会一直计费,肉疼。要么就得销毁,下次使用时还需要重新搭建,这个体验欠佳,希望可以增加暂停的功能。
期待腾讯云 HAI 服务持续优化,越来越易用,真正实现随时随地可用,同时与 CloudStudio 配合使用,为开发者提供更广阔的想象空间。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











