






在角色控制方面,我们都了解到midjourney的局限性,其无法稳定地实现目标控制。然而,Stable Diffusion 提供了出色的可控性,使我们能够有效地弥补这一缺陷。
今天就通过一个简单案例,给大分享如何使用 Stable Diffusion 中的 ControlNet 插件实现角色稳定控制与线稿上色。
首先我们利用midjourney生成线稿(手依然是硬伤,有能力朋友可以在软件中自己处理一下,咱们这边先忽略),效果如下:

咒语如下:Iron man standing on the ruins, coloring book style, no color, white background, black and white, ink lines, anime style --ar 9:16 --q 2 --s 750 --niji 5 (好像目前只有在niji模式出来这样的效果)
翻译:钢铁侠站在废墟上,涂色书风格,无色彩,白底,黑白,墨线,动漫风格
利用Stable Diffusion对生成的线稿进行上色,生成效果如下:

–步骤如下:
1.打开Stable Diffusion文生图模式,输入正反向提示词:
**正向提示词:**hyper HD, Masterpiece, Anatomically correct, ccurate, Textured skin, Super detail, High quality, High details, Award-Awarded, Best quality, A high resolution,Iron Man stands on the ruins of destruction,lora:3DMM\_V12:0.8,3DMM
翻译:超高清,杰作,解剖学正确,准确,纹理皮肤,超细节,高品质,高细节,获奖,最佳品质,高分辨率,钢铁侠站在毁灭的废墟上,lora:3DMM\_V12:0.8, 3DMM
反向提示词:(nsfw:1.5),verybadimagenegative_v1.3, ng_deepnegative_v1_75t, (ugly face:0.8),cross-eyed,sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, bad anatomy, DeepNegative, facing away, tilted head, {Multiple people}, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worstquality, low quality, normal quality, jpegartifacts, signature, watermark, username, blurry, bad feet, cropped, poorly drawn hands, poorly drawn face, mutation, deformed, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, extra fingers, fewer digits, extra limbs, extra arms,extra legs, malformed limbs, fused fingers, too many fingers, long neck, cross-eyed,mutated hands, polar lowres, bad body, bad proportions, gross proportions, text, error, missing fingers, missing arms, missing legs, extra digit, extra arms, extra leg, extra foot, ((repeating hair)),(这里基本是常用的反向词)
翻译:(nsfw:1.5),verybadimage Negative_v1.3,ng_deep Negative_v1_75t,(丑陋的脸:0.8),斗鸡眼,草图,(最差质量:2),(低质量:2),(正常质量:2),低分辨率,正常质量 , ((单色)), ((灰度)), 皮肤斑点, 痤疮, 皮肤瑕疵, 不良解剖结构, DeepNegative, 背向, 倾斜头部, {多人}, 低分辨率, 不良解剖结构, 不良手, 文本, 错误, 缺失 手指、多余的数字、较少的数字、裁剪、质量最差、低质量、正常质量、jpegartifacts、签名、水印、用户名、模糊、脚不好、裁剪、手画得不好、脸画得不好、突变、变形、质量最差、质量低 , 正常质量, jpeg 伪影, 签名, 水印, 额外的手指, 数字较少, 额外的肢体, 额外的手臂, 额外的腿, 畸形的肢体, 融合的手指, 手指太多, 长脖子, 斗鸡眼, 变异的手, 极性低分辨率, 坏 身体、比例不良、总体比例、文本、错误、缺少手指、缺少手臂、缺少腿、多余的手指、多余的手臂、多余的腿、多余的脚、((重复头发))
**2.大模型选择:**RevAninmate_v122 **Lroa选择:**3DMM_V12
3.ControlNet 设置:
将线稿上传,选择ControlNet预处理器:invert,模型选择lineart_anime。
此步是关键,个人简单理解的原理就是,利用 ControlNet插件 识别并控制线稿中的内容,然后根据stable diffusion的图像扩散原理进行渲染绘制;
详细设置请查看下面的截图,这里就不赘述了。
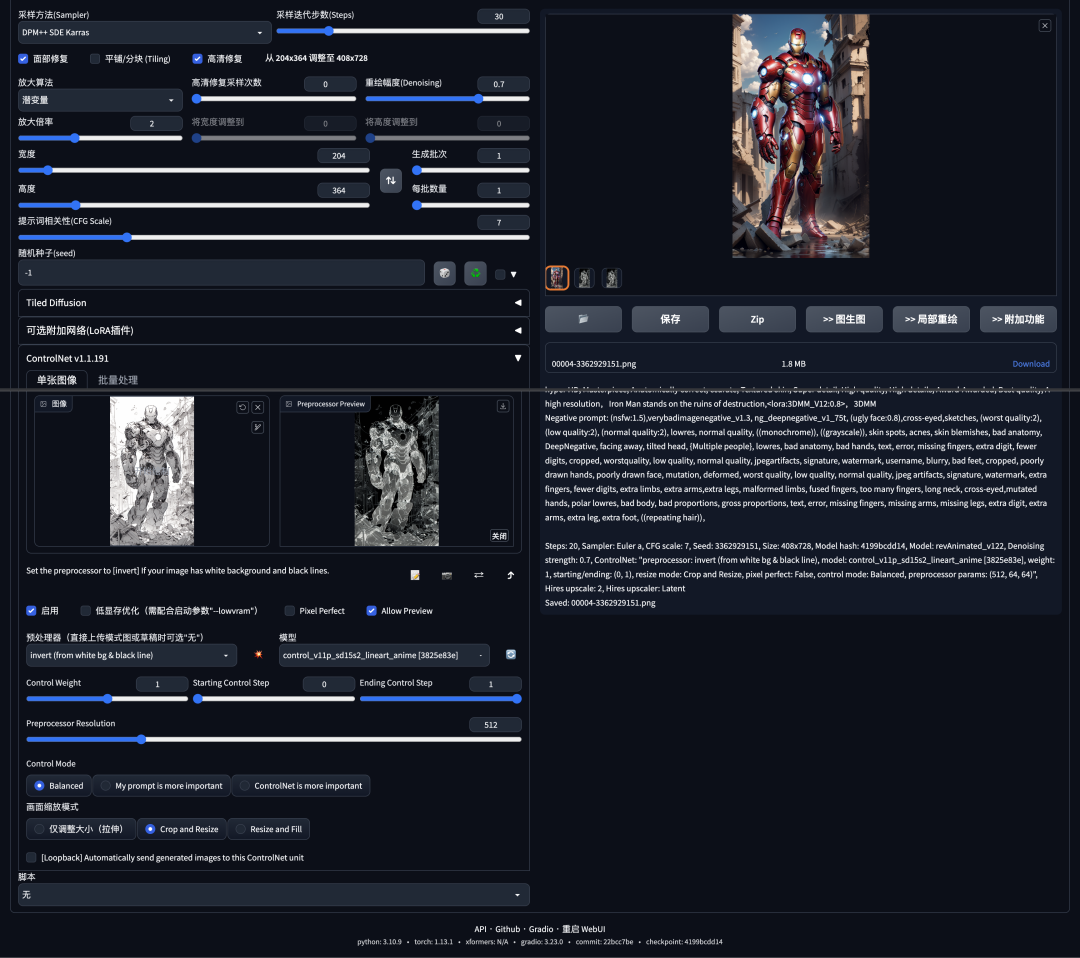
这样很快就能完成了,由于个人电脑显卡的问题,生成的效果不是特别完美,我们将线稿和上色稿放在一起对比看下效果;


整体感觉还好,局部细节因为线稿本身没有交代特别清楚,需要微调,有条件的朋友可以多生成几张图可抽卡看看…
以上就是基本操作流程了,实现起来很简单,大家可以试试。
文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,。有需要的小伙伴文末扫码自行获取。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除














 9774
9774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









