






如何将大模型应用落地到自己的业务或工作中?这篇文章整理了7种目前业内最常用的大模型应用方法,以及各个方法的代表论文。通过对各种应用大模型方法的特点对比,找到最适合自己场景的应用方法。
1、Pretrain-Finetune
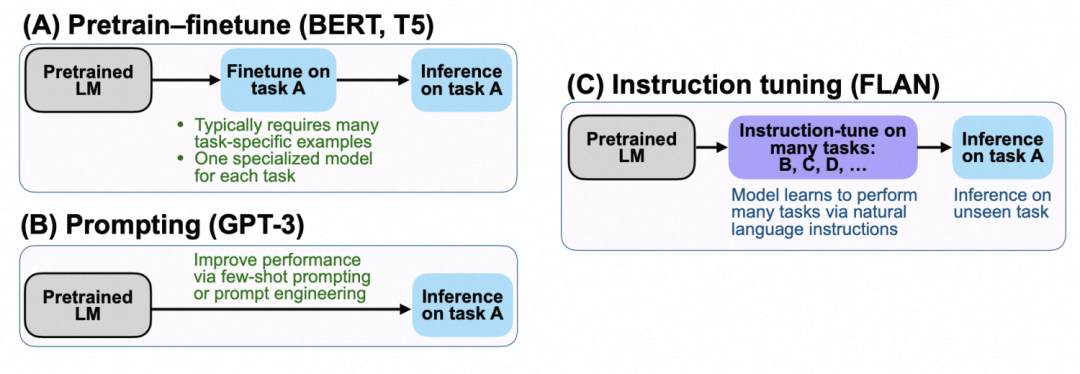
直接针对下游任务进行全量参数或者部分参数的finetune,在BERT时期是主要的大模型应用方式。其局限性是成本较高,灵活性较差,需要针对每个任务单独finetune和保存一组模型,可复用性较低。
2、Prompt
Prompt是GPT以来的一种大模型应用方式,基于生成式语言模型(Transformer Decoder),将下游任务通过prompt的形式转换成完形填空任务,让模型预测缺失部分的文本,再将文本映射回对应任务的label。Prompt方式完全不进行大模型finetune,只利用大模型内部的知识,让下游任务反向适配预训练任务。其缺陷在于效果非常依赖于人工定义的prompt。
3、Prompt-tuning
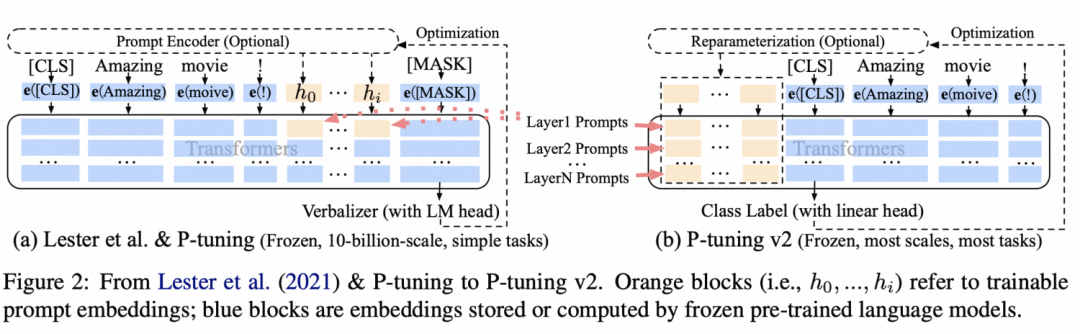
Prompt-tuning不人工设定prompt,而是将其转换为可学习的向量。例如原来的prompt为The capital of Y is …,这里Y是上下文,其他部分是prompt模板,那么prompt-tuning将这些明文的prompt token全部替换成可学习的向量,基于训练数据对模型进行finetune,只finetune这些prompt embedding,模型主体参数固定不变。。这种方式不再依赖人工定义prompt明文模板,交给模型自己去学,同时需要finetune的参数量也比较小。
代表论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks(2021)、GPT Understands, Too(2021)
4、Prefix-tuning
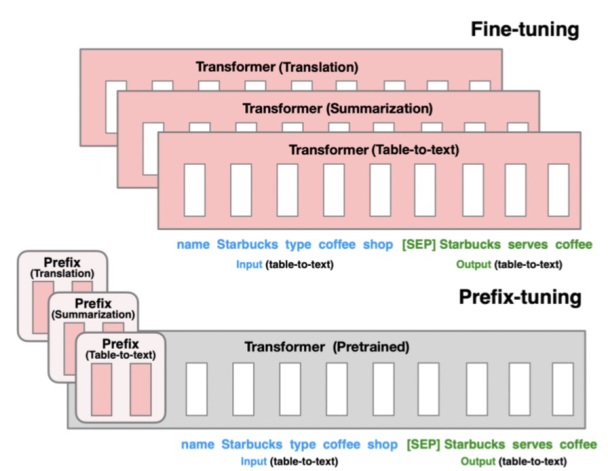
与prompt-tuning的思路非常类似,prefix-tuning在输入文本前面加入一些任务特定的可学习参数,这些参数跟随下游任务做finetune,预训练模型整体参数固定不变。Prefix-tuning和prompt-tuning是同一时期的两类工作,二者核心思路是相同的,都是用一小部分参数的finetune(prefix对应的前缀向量,或prompt对应的模板向量)让大模型适配下游任务,二者区别不大。
代表论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation(2021)
5、Adapter-tuning
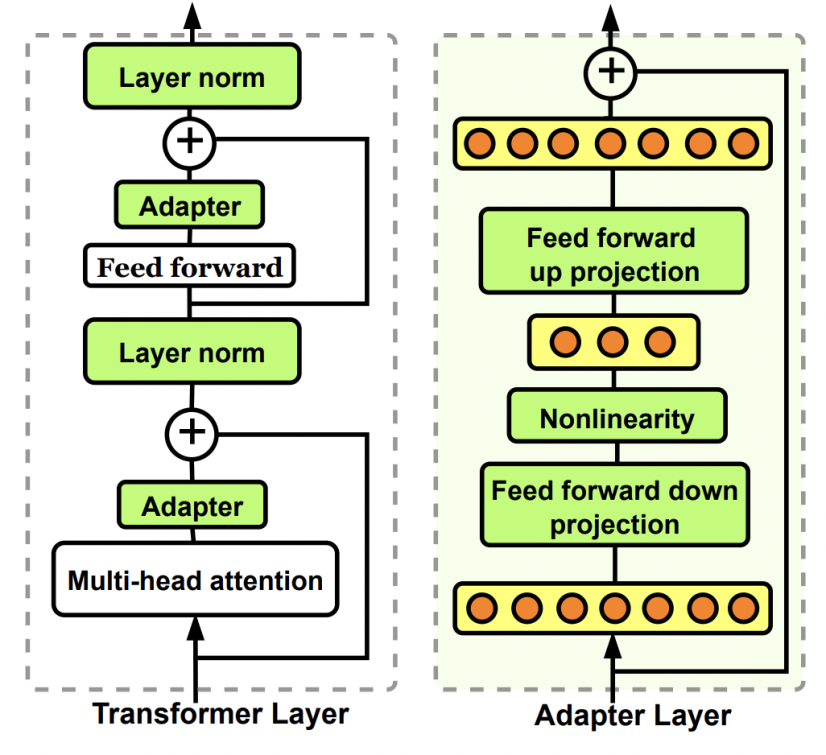
在大模型的中间部分加一个参数量较小的网络结构(即adapter),大模型整体参数freeze不变,只更新adapter部分的参数。Adapter一般采用bottleneck的结构,缩小参数量。本质上也是一种通过少量参数的更新影响大模型整体参数的finetune方式。
代表论文:Parameter-Efficient Transfer Learning for NLP(ICML 2019)
6、Instruction-tuning
Instruction-tuning将所有下游的各类NLP任务都转换为自然语言,在大模型的基础上finetune全部参数,finetune的目标就是语言模型,通过这种方式让预训练大模型适应人类的指令(即人类描述各类NLP任务,并要求模型给出答案的语言范式),进而有效解决各类NLP任务,具备强大的zero-shot learning能力。
7、Knowledge Distillition
从大模型中获取数据,用获取到的数据训练尺寸更小的模型,过程中结合思维链等技术,让模型生成更有价值更准确的训练数据。这种方式也是成本最低,但是可能很有效果的方法。最简单的就是直接调用ChatGPT或者GPT4的接口获取想要的数据,核心是如何设计prompt让黑盒大模型输出我们想要的结果。
代表论文:Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料。包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程扫描领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程扫描领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程扫描领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程扫描领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程扫描领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









