







引言
通过上一个看得吃力的视频,现在word embedding给我的印象就是cv中的auto-encoder,只不过网络不一样。目测不难,接下来看个究竟。
word represent(word2vec)
- 1-of-N Encoding
cv中的one-hot。如果1w个单词,vector的维度也是1w。每个vector只有一个维是1,其余是0。
vector之间没有任何联系,生活中猫和狗属于动物;没有充分利用vector的空间,网络无法训练这么长的vector。 - Word Embedding
专业说法:把每一个word映射到高维空间,高维空间由一定长度的vector表示,但远比one-hot的vector要短。
每一维代表了不同的语义特征,如:第一维决定动物还是植物。这个我们无从得知,全靠网络training。

如何Embedding
目的:machine learn the meaning of words from reading a lot of documents without supervision。无监督学习
训练数据:a lot of text
无法用auto-encoder来解决,因为输入是什么?所以引言打脸了
思想:

方法:
- Count based
w i w_i wi和 w j w_j wj表示两个词汇,word vector分别用 V ( w i ) V(w_i) V(wi)和 V ( w j ) V(w_j) V(wj)来表示。如果两个词汇常常在同一篇文章中同时出现(co-occur), V ( w i ) V(w_i) V(wi)和 V ( w j ) V(w_j) V(wj)会比较接近。
N i , j N_{i,j} Ni,j是 w i w_i wi和 w j w_j wj这两个词汇在相同文章里同时出现的次数,我们希望它与 V ( w i ) ⋅ V ( w j ) V(w_i)\cdot V(w_j) V(wi)⋅V(wj)的内积越接近越好。 - Prediction based

1. 类似auto-encode,但是网络输入为 w i − 1 w_{i-1} wi−1需要预测 w i w_i wi。假设使用1-of-N encoding表示word,输出的维度与输入一样,只不过每一维都是小数,表示每个词的概率。
2. 把第一个hidden layer的input z 1 , z 2 , . . . z_1,z_2,... z1,z2,...拿出来,它们所组成的 Z Z Z就是word的另一种表示方式。第一层hidden layer的维数可以自由决定,而input唯一确定了一个word,因此提取出第一层hidden layer的input,实际上就得到了一组可以自定义维数的Word Embedding的表示向量。
问题:直接auto-encode不行,预测下一个word又work呢
回答:(1)预测下一个词目的:根据词汇的上下文来了解该词汇的含义
(2)存在两个语义近似的词,为了使这两个不同的input通过NN能得到相同的output,就必须在进入hidden layer之前,就通过weight的转换将这两个input vector投影到位置相近的低维空间上。 - Prediction based改进sharing Parameters
问题:一个词并不能决定下一个词
回答:使用10个及以上的词汇去预测下一个词汇,可以帮助得到较好的结果

step1:
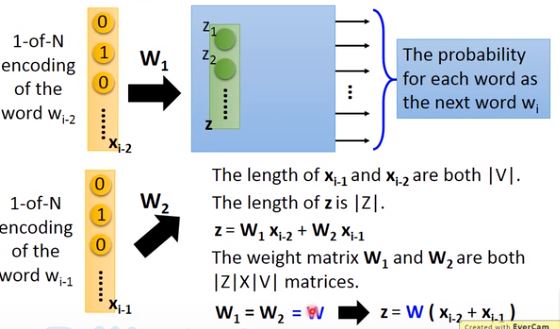
这多个vector拼接成一个更长的vector作为input。但我们更希望看到这些vector独立,即 w i − 2 w_{i-2} wi−2与 w i − 1 w_{i-1} wi−1的相同dimension对应到第一层hidden layer相同neuron之间的连线拥有相同的weight。
否则把同一个word放在 w i − 2 w_{i-2} wi−2的位置和放在 w i − 1 w_{i-1} wi−1的位置,得到的Embedding结果是会不一样的。
这么做还可以通过共享参数的方式有效地减少参数量,不会由于input的word数量增加而导致参数量剧增。
step2:
保证
W
1
W_1
W1和
W
2
W_2
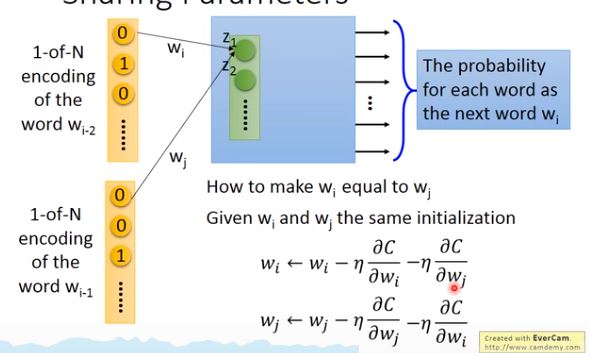
W2一样。好像没见过一个权值给两个输入,因为每个layer类,如conv2,都有自己的权值。
首先要给它们一样的初始值,然后分别计算loss function
C
C
C对
w
i
w_i
wi和
w
j
w_j
wj的偏微分,并对其进行更新
w
i
=
w
i
−
η
∂
C
∂
w
i
w
j
=
w
j
−
η
∂
C
∂
w
j
w_i=w_i-\eta \frac{\partial C}{\partial w_i}\ w_j=w_j-\eta \frac{\partial C}{\partial w_j}
wi=wi−η∂wi∂C wj=wj−η∂wj∂C 这个时候=,
C
C
C对
w
i
w_i
wi和
w
j
w_j
wj的偏微分是不一样的,这意味着即使给了
w
i
w_i
wi和
w
j
w_j
wj相同的初始值,更新过一次之后它们的值也会变得不一样,因此我们必须保证两者的更新过程是一致的,即:
w
i
=
w
i
−
η
∂
C
∂
w
i
−
η
∂
C
∂
w
j
w
j
=
w
j
−
η
∂
C
∂
w
j
−
η
∂
C
∂
w
i
w_i=w_i-\eta \frac{\partial C}{\partial w_i}-\eta \frac{\partial C}{\partial w_j}\ w_j=w_j-\eta \frac{\partial C}{\partial w_j}-\eta \frac{\partial C}{\partial w_i}
wi=wi−η∂wi∂C−η∂wj∂C wj=wj−η∂wj∂C−η∂wi∂C这样就保证了
w
i
w_i
wi和
w
j
w_j
wj始终相等。使用one-hot类型,使用如cv那样minimize它们之间的cross entropy
step3:
word-to-vector现在流行神经网络,但这个network只有一个linear的hidden layer。
把1-of-N编码输入给神经网络,经过weight的转换得到Word Embedding,再通过第一层hidden layer就可以直接得到输出。即不需要deep network。
Prediction-based多种变形
- CBOW(Continuous bag of word model):拿前后的词汇去预测中间的词汇
- Skip-gram:拿中间的词汇去预测前后的词汇
科普区
性质:把word vector两两相减,再投影到下图中的二维平面上,如果某两个word之间有类似包含于的相同关系,它们就会被投影到同一块区域。(鸡-公鸡,狗-警犬)
则 鸡-公鸡≈狗-警犬 那我们可以已知3个,求剩下一个的vector。
应用:
- 建立起不同语言之间的联系,分别训练一个英文的语料库(corpus)和中文的语料库,你会发现两者的word vector之间是没有任何关系的,因为Word Embedding只体现了上下文的关系。
但是,如果你知道某些中文词汇和英文词汇的对应关系,你可以先分别获取它们的word vector,然后再去训练一个模型,把具有相同含义的中英文词汇投影到新空间上的同一个点。属于监督学习吧
接下来遇到未知的新词汇,无论是中文还是英文,你都可以采用同样的方式将其投影到新空间,就可以自动做到类似翻译的效果。 - 假设你已经得到horse、cat和dog这些词汇的vector在空间上的分布情况,你就可以去训练一个模型,把一些已知的horse、cat和dog图片去投影到和对应词汇相同的空间区(维度相同)域上。
对模型输入一张图像,使之输出一个跟word vector具有相同维数的vector,如使dog图像的映射向量就散布在dog词汇向量的周围。
图像分类大部分情况下都是事先定好要分为哪几个具体的类别,因为输出维度要固定。由于我们无法在训练的时候穷尽所有类别的图像;或者需要识别的类的数据集太少,只能舍弃该类别。
而使用image+word Embedding的方法,就算输入的图像类别在训练时没有被遇到过,比如上图中的cat,但如果这张图像能够投影到cat的word vector的附近,根据词汇向量与图像向量的对应关系,你自然就可以知道这张图像叫做cat。属于0样本学习吧,可惜不弄cv了
结束
最后给出关于word2vec,可以参考博客:http://blog.csdn.net/itplus/article/details/37969519
这个不急着看,急的是看看RNN究竟怎么运用,代码如何写。
40分钟…















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









