







前言
在看李宏毅的hw8:seq-to-seq时,发现要动手完成下面任务,懵了。
我还是个初学者,虽然我最近看了李宏毅关于语音辨识部分,也看完hw4,但代码能力还是0。
网上找不到这次作业任务的实现,找到pytorch官网关于seq-to-seq的实现,先学一下。

资料
知识都是借鉴和查出来的。
pytorch官网,建议还是看英文。
csdn博客,也是应用attention原理在hw4作业的那一位,but他也没实现hw8。
torchtext:对此模块没了解过
We hope after you complete this tutorial that you’ll proceed to learn how torchtext can handle much of this preprocessing for you in the three tutorials immediately following this one.
网络的介绍:编码器与解码器通过Context Vector来连接
sequence to sequence network , in which two recurrent neural networks work together to transform one sequence to another. An encoder network condenses an input sequence into a vector, and a decoder network unfolds that vector into a new sequence.
attention的作用
To improve upon this model we’ll use an attention mechanism, which lets the decoder learn to focus over a specific range of the input sequence.

数据集
and better yet, someone did the extra work of splitting language pairs into individual text files here: https://www.manythings.org/anki/
说上面网站的数据太多,使用下方链接的数据:download
The English to French pairs are too big to include in the repo, so download to data/eng-fra.txt before continuing. The file is a tab separated list of translation pairs:
将词作为输入
we will be representing each word in a language as a one-hot vector. So the encoding vector is much larger. We will however cheat a bit and trim the data to only use a few thousand words per language
记录每个词出现次数
a count of each word word2count to use to later replace rare words.
数据的预处理,更具体的原文每一步有解释。
The files are all in Unicode, to simplify we will turn Unicode characters to ASCII, make everything lowercase, and trim most punctuation.
筛选简单且短的句子
we’ll trim the data set to only relatively short and simple sentences. Here the maximum length is 10 words
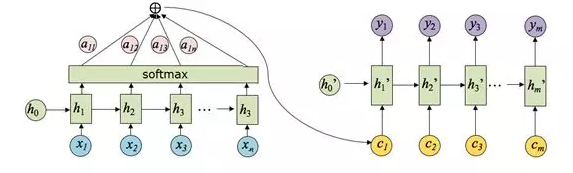
注意力机制
引用上述博主:iteapoy
问题:很难真正把输入序列的所有信息都压缩到一个向量中,context vector。
注意力机制:解码器(decoder)在每一步(time step t)解码的时候,给编码器(encoder)的隐藏层(hidden layer)赋上不同的权重,得到不同的上下文向量 C t C_t Ct,t代表时间。
容易误导:对象不是不同的隐藏层,layer 1 ,layer2 …
而是对同一个隐藏层,不同时间的隐藏层状态。
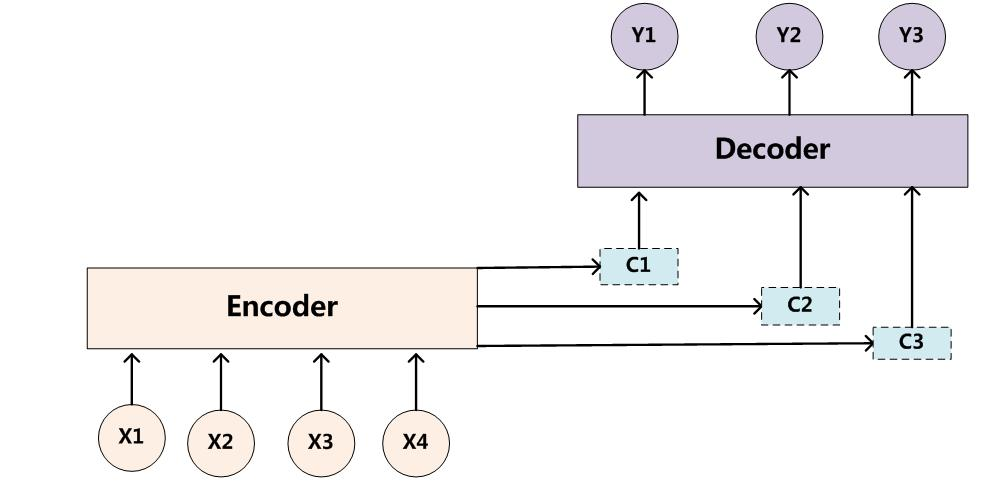
区别:不在用encoder最后一次输出作为decoder的输入
假设 h i h_i hi是编码器第 i i i步的隐藏层状态; h t h_t ht是解码器第 t t t步的隐藏层状态,上下文向量 C t C_t Ct的计算公式为,t=1,2,3…(decoder要循环的次数):
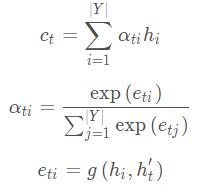
a
t
i
a_{ti}
ati是注意力的权重,权重代表更关注encoder的哪一次输出。
e
t
i
e_{ti}
eti是两个隐藏层通过矩阵转换,点积后的值,scaler(标量)形式。当前decoder的隐藏状态与encoder每个时间步的隐藏状态进行计算。
C
t
C_t
Ct计算当前decoder时,encoder所以隐藏状态的权重和。
Y
Y
Y指的是encoder循环的次数。
代码
数据预处理
The full process for preparing the data is:
- Read text file and split into lines, split lines into pairs
- Normalize text, filter by length and content
- Make word lists from sentences in pairs
这里不像原文分步骤了,找函数麻烦
import re
import unicodedata
import random
SOS_token = 0
EOS_token = 1
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {} #记录每个单词出现次数
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS,记录单词总数
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word) #把句中每个单词都加入词典
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
#---------------------
# Turn a Unicode string to plain ASCII, thanks to
# https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
#--------------------
def readLangs(lang1, lang2, reverse=False):
print("Reading lines...")
# Read the file and split into lines
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
# Reverse pairs, make Lang instances
if reverse: #原来的文件是英译法,如果想法译英,把输入序列和输出序列交换
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
#--------------------
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
) #指定的字符或者子字符串。(可以使用元组,会逐一匹配)
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH and \
p[1].startswith(eng_prefixes)
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
#--------------------
def prepareData(lang1, lang2, reverse=False):
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)
print("Read %s sentence pairs" % len(pairs))
pairs = filterPairs(pairs)
print("Trimmed to %s sentence pairs" % len(pairs))
print("Counting words...")
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("Counted words:")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('eng', 'fra', True)
print(random.choice(pairs))
结果
Reading lines...
Read 135842 sentence pairs
Trimmed to 10599 sentence pairs
Counting words...
Counted words:
fra 4345
eng 2803
['je suis financierement independant de mes parents .', 'i m economically independent of my parents .']
re.sub,\1意思是匹配到的组
import re
s = "today is mon.so i'm tired, and hungry... how about you?can you bri77ng me a 9cake!Thank''s you!!"
ss = re.sub(r"([.!?])", r" \1", s)
print(ss)
sss = re.sub(r"[^a-zA-Z.!?]+", r" ", ss)
print(sss)
#result
today is mon .so i'm tired, and hungry . . . how about you ?can you bri77ng me a 9cake !Thank''s you ! !
today is mon .so i m tired and hungry . . . how about you ?can you bri ng me a cake !Thank s you ! !
模型
encoder
For every input word the encoder outputs a vector and a hidden state, and uses the hidden state for the next input word.
decoder
another RNN that takes the encoder output vector(s) and outputs a sequence of words to create the translation.
自身理解勘误:我以为是传给decoder是经过RNN得到的1-D向量,实际是hidden layer。 hidden state为1-D,则应该是经过RNN得到的1-D向量。
h_n是形状为(num_layers * num_directions, batch, hidden_size)的tensor
In the simplest seq2seq decoder we use only last output of the encoder. This last output is sometimes called the context vector as it encodes context from the entire sequence. This context vector is used as the initial hidden state of the decoder.
At every step of decoding, the decoder is given an input token and hidden state. The initial input token is the start-of-string <SOS> token, and the first hidden state is the context vector (the encoder’s last hidden state).
input length ≠ output length
With a seq2seq model the encoder creates a single vector which, in the ideal case, encodes the “meaning” of the input sequence into a single vector — a single point in some N dimensional space of sentences.
encoder===》 decoder===》
decoder===》
Attention Decoder
陷于困惑
我的认知:input一维的特征向量
I
i
n
I_{in}
Iin,然后通过权重矩阵
W
i
n
−
s
i
z
e
,
o
u
t
−
s
i
z
e
W_{in-size,out-size}
Win−size,out−size,得到output一维的特征向量
O
o
u
t
O_{out}
Oout。我一直以为hidden state利用的是权重矩阵W,然而这里hidden state就是output
O
1
:
t
O_{1:t}
O1:t。
the encoder’s last hidden state其实就是一维的向量,那其实就是最后一次RNN的output
O
t
O_t
Ot。
而进行attention的权重和,就是对encoder的output
O
1
:
t
O_{1:t}
O1:t进行加权求和。
质疑
我同意的观点,语音辨识LAS,之前的attention机制

是用decoder的hidden state去乘encoder每个time step的hidden state得到权重(通过softmax),求和就得到decoder的输入Context vector。
原文的观点和操作,《pytorch深度学习》用此模型


由另一个前向传播的全连接层 attn来计算注意力权重,它的输入是解码器的输入和隐藏层状态。即它的权重的计算没有联系到encoder。这一步我认为有问题。
后面它确实是用得到的权重让encoder每个time step的hidden state求和。求和得到的attn_applied在与decoder的输入连接,attn_combine又一个全连接。最后作为输入。
Attention allows the decoder network to “focus” on a different part of the encoder’s outputs for every step of the decoder’s own outputs. First we calculate a set of attention weights. These will be multiplied by the encoder output vectors to create a weighted combination. The result (called attn_applied in the code) should contain information about that specific part of the input sequence, and thus help the decoder choose the right output words.
input是编码器的上一步输出 或者 真实的前一个单词
Calculating the attention weights is done with another feed-forward layer attn, using the decoder’s input and hidden state as inputs. Because there are sentences of all sizes in the training data, to actually create and train this layer we have to choose a maximum sentence length (input length, for encoder outputs) that it can apply to. Sentences of the maximum length will use all the attention weights, while shorter sentences will only use the first few.
因此,探索真相。
文本分类任务中几种attention机制的介绍
两大Attention机制解释
关注了该博主
摘要
两大attention机制:Bahdanau 和 Luong。
其他类型没用到 先不看
重点:
在解码的过程中对于中间语义向量C的使用有两种形式:(1)中间语义向量C参与解码的每个时刻(2)中间语义向量只参与解码的第一时刻。对于第一种中间语义向量C的使用方式来说,解码过程中每一时刻的输出与上一时刻的输出,当前时刻的隐层向量和C有关。
Bahdanau的算法 ,GeneralAttn书上没有,后面实战也没用这个模型。

Luong看下面。
摘要
- encoder得到encoder_output和encoder_hidden。
- 在decoder网络的一开始,我们将encoder_hidden传给GRU的decoder_hidden,而不是默认的随机初始化,并且利用sos标志传给GRU网络作为输入,得到de_gru_output.shape为[seq_len, batch, hidden_size]。由于decoder网络的输入是一个单词接一个单词。所以seq_len=1。
- 根据LuongAttention的‘general’模型,首先对encoder_output进行一层线性层,然后再将de_gru_output与结果相乘,得到的score求内积。事实上这个内积之后的score就是attn_weigths, 它的维度为[batch, max(length)]。
- 将atten_weigths与encoder_output进行相乘得到context:[batch, 1, hidden_size]。然后变化维度与decoder的GRU得到的de_gru_output拼接,得到concat_input。然后再经过两层线性层与一层softmax,就得到了最终的输出。
明显这里又不同于上述两种,这个Attention模型得到context之后并不经过gru,lstm之类的,直接经过两层线性层
不是代码
class Attn(nn.Module):
attn_weigths.shape = [batch, 1, max(length)]
encoder_output.transpose(0, 1) = [batch, max(length), hidden_size]
context = torch.bmm(attn_weigths, encoder_output.transpose(0, 1))
减少篇幅,有必要看一下。
实战这一篇与上一篇处理内积不一样。挺详细,也是使用RNN的输出和context向量预测下一个词
class AttnDecoderRNN(nn.Module):
def __init__(self, attn_model, hidden_size, output_size, n_layers=1, dropout_p=0.1):
super(AttnDecoderRNN, self).__init__()
self.attn_model = attn_model
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout_p = dropout_p
# 定义网络中的层
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size * 2, hidden_size, n_layers, dropout=dropout_p)
self.out = nn.Linear(hidden_size * 2, output_size)
# 选择注意力模型
if attn_model != 'none':
self.attn = Attn(attn_model, hidden_size)
def forward(self, word_input, last_context, last_hidden, encoder_outputs):
# 注意:每次我们处理一个time step
# 得到当前输入(上一个输出)的embedding
word_embedded = self.embedding(word_input).view(1, 1, -1) # S=1 x B x N
# 把当前的embedding和上一个context拼接起来输入到RNN里
rnn_input = torch.cat((word_embedded, last_context.unsqueeze(0)), 2)
rnn_output, hidden = self.gru(rnn_input, last_hidden)
# 使用RNN的输出和所有encoder的输出来计算注意力权重,然后计算context向量
attn_weights = self.attn(rnn_output.squeeze(0), encoder_outputs)
context = attn_weights.bmm(encoder_outputs.transpose(0, 1)) # B x 1 x N
# 使用RNN的输出和context向量预测下一个词
rnn_output = rnn_output.squeeze(0) # S=1 x B x N -> B x N
context = context.squeeze(1) # B x S=1 x N -> B x N
output = F.log_softmax(self.out(torch.cat((rnn_output, context), 1)), 1)
return output, context, hidden, attn_weights
文章下面介绍
- 怎么一次训练一个batch 的数据,通过“pad”来把短的序列补到和长的序列一样长
- encoder使用两层双向的GRU
- decoder变成了batch 的输入而已,但是在时间维度还是循环处理的
github地址中英翻译厉害的githuber
摘要
由于encoder-decoder模型在编码和解码阶段始终由一个不变的语义向量C来联系着。造成了 (1)语义向量无法完全表示整个序列的信息,(2)最开始输入的序列容易被后输入的序列给覆盖掉,会丢失许多细节信息。在长序列上表现的尤为明显。
attention: 编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。充分利用输入序列携带的信息。
计算
a
i
j
a_{ij}
aij:
s
i
−
1
s_{i−1}
si−1 先跟每个
h
h
h分别计算得到一个数值,然后使用softmax得到
i
i
i时刻的输出在
T
x
T_x
Tx个输入隐藏状态中的注意力分配向量。这个分配向量也就是计算
c
i
c_i
ci的权重。

要解决的问题:在RNN中可写成
y
t
=
g
(
y
t
−
1
,
h
t
,
C
)
y_t = g(y_{t−1}, h_t, C)
yt=g(yt−1,ht,C),C是作为decoder的输入还是初始化隐藏层???
si 表示解码器 i 时刻的隐藏状态,计算公式
s
i
=
f
(
s
i
−
1
,
y
i
−
1
,
C
i
)
s_i = f(s_{i-1},y_{i-1},C_i)
si=f(si−1,yi−1,Ci)
training
To train we run the input sentence through the encoder, and keep track of every output and the latest hidden state. Then the decoder is given the token as its first input, and the last hidden state of the encoder as its first hidden state.
结束
训练其实看看代码就能理解,
主要是attention机制,模型的输入怎么使用。
下一篇再讲解怎么训练和展示结果。















 2965
2965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









