







论文:Heterogeneous Memory Enhanced Multimodal Attention Model for VQA
来源:CVPR2019
作者:京东研究院
源码: Github
文章目录
1. 摘要
这篇文章主要有三个点:
- 提出一个 (包含注意力读写机制的)异构的存储器 从 外观特征 和 运动特征 两个方面来学习 全局的上下文信息;
- 重新设计 问题存储器 来理解问题的复杂语义信息并突出查询主体;
- 提出一种新的 多模态融合层 ,通过软注意力 关注 相关的视觉和文本特征并进行多步推理
且指出了几个挑战:
- 现有的主要方法不能正确识别注意力。因为它们将 特征集成 和 注意力学习 步骤分开。所以,本文提出了一种新的 异构记忆方法,将外观和运动特征结合起来, 同时 学习时空注意力。
- 当问题有很复杂的语义并且需要多步推理的时候将会很困难。
所以本文设计了新的网络结构将 问题编码器 和 问题存储器 整合起来:问题编码器学习丰富的文本表达,问题存储器通过 存储和更新全局上下文 理解复杂的语义信息并突出被询问的主体
2. 方法
整个模型的Pipline如下图:
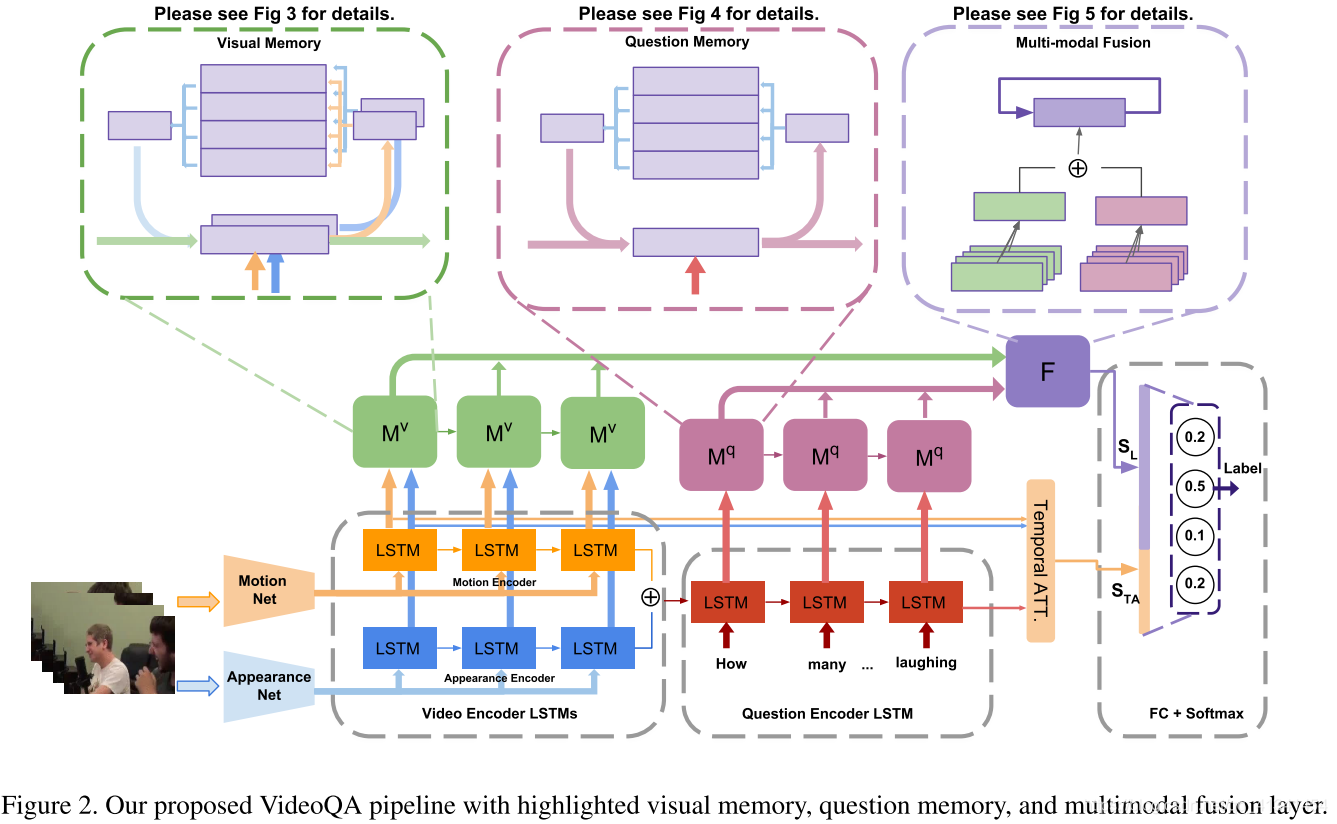
2.1 视频文本的特征表达
1 视频表示
从视频剪影中提出固定帧数的视频帧,然后使用预训练的 ResNet 或 VGGNet 等传统CNN 提取每一帧的 外表特征(appearance features),使用3D卷积网络 C3D 提取 运动特征。 记作
f
a
=
[
f
1
a
,
f
2
a
,
.
.
.
,
f
N
v
a
]
f^a = [f_1^a,f_2^a,...,f_{N_v}^a]
fa=[f1a,f2a,...,fNva]
和
f
m
=
[
f
1
m
,
f
2
m
,
.
.
.
,
f
N
v
m
]
f^m = [f_1^m,f_2^m,...,f_{N_v}^m]
fm=[f1m,f2m,...,fNvm]
然后用两个LSTM提取进行时序建模,输出两个时序编码:
o
a
=
[
o
1
a
,
o
2
a
,
.
.
.
,
o
N
v
a
]
o^a = [o_1^a,o_2^a,...,o_{N_v}^a]
oa=[o1a,o2a,...,oNva]
和
o
m
=
[
o
1
m
,
o
2
m
,
.
.
.
,
o
N
v
m
]
o^m = [o_1^m,o_2^m,...,o_{N_v}^m]
om=[o1m,o2m,...,oNvm]
2 问题表示
每个VideoQA都有一个已定义好的 词典, 包含在训练集上出现词频TopK的单词。各个数据集的词典长度K如下:
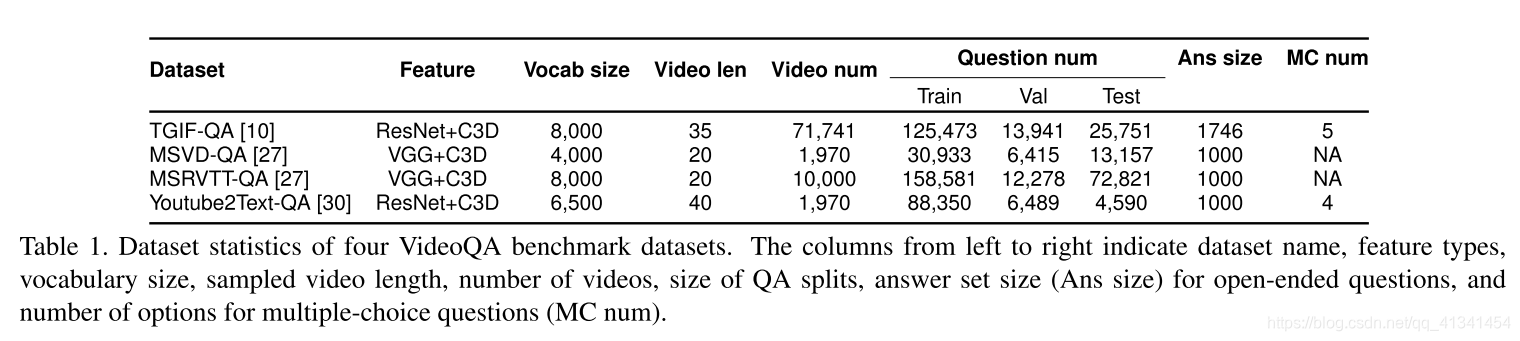
然后使用固定长度的可学习的 词嵌入(word ebedding) 表示每个单词,嵌入层权重使用预训练的 GloVe 300-D特征 来初始化。一个句子整个嵌入表示定义为:
f
q
=
[
f
1
q
,
f
2
q
,
.
.
.
,
f
N
q
q
]
f^q = [f_1^q,f_2^q,...,f_{N_q}^q]
fq=[f1q,f2q,...,fNqq]
其中
N
q
N_q
Nq 表示每个问题的单词数。
最后,使用一个LSTM用于时序建模,得到最终的文本特征:
o
q
=
[
o
1
q
,
o
2
q
,
.
.
.
,
o
N
q
q
]
o^q = [o_1^q,o_2^q,...,o_{N_q}^q]
oq=[o1q,o2q,...,oNqq]
2.2 异构视频存储器
上面的外表特征和运动特征对与问题有关的物体和事件的识别都起到了关键性的作用。但是,由于这两种特征的异构性,所以直接的联合不能很好的学习到视频的内容表示。
因此,本文提出一个 异构的存储器 将运动和外观视觉特征结合起来,学习共同注意力,增强时空推理。
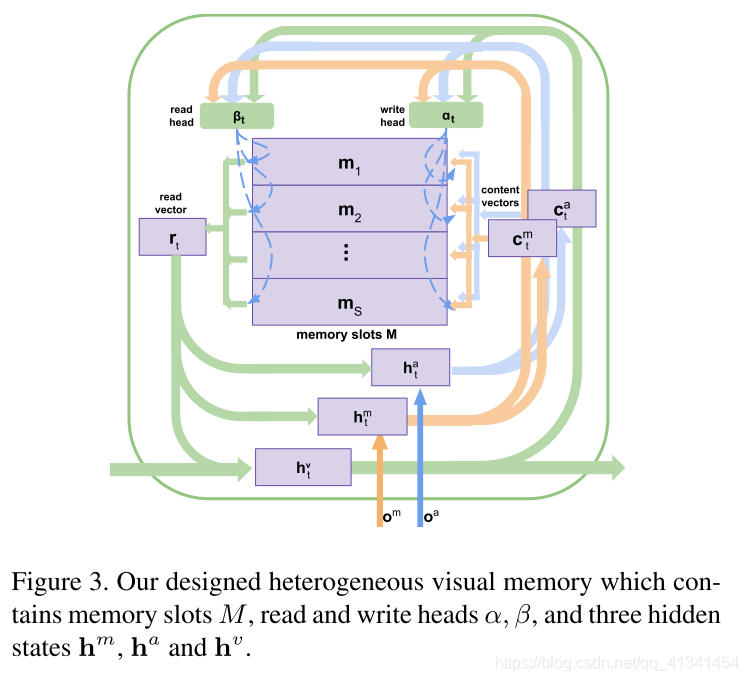
这个异构存储器可接收多种输入:运动特征
O
m
O^m
Om,外观特征
O
a
O^a
Oa。包括一个存储插槽
M
=
[
m
1
,
.
.
.
,
m
S
]
M = [m_1,...,m_S]
M=[m1,...,mS],以及三个隐藏状态
h
m
,
h
a
,
h
v
h^m,h^a,h^v
hm,ha,hv:
- h m h^m hm 决定需要写入的运动特征的内容
- h a h^a ha 决定需要写入的外观特征的内容
- h v h^v hv 存储和输出全局的上下文感知特征(通过存储器同时整合了运动和外观特征)
我们假定插槽的数目为 S S S,激活函数sigmod为 σ \sigma σ,则各个操作定义如下:
写入操作
- 首先我们由当前的输入
o
t
m
/
a
o_t^{m/a}
otm/a和之前的隐藏层输入
h
t
−
1
m
/
a
h_{t-1}^{m/a}
ht−1m/a决定此时此刻
t
t
t的写入内容
c
t
m
/
a
c_t^{m/a}
ctm/a
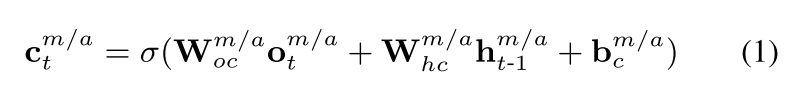
- 然后我们计算出分配给每个存储槽的写入权重
α
t
m
/
a
=
α
t
,
1
m
/
a
,
.
.
.
,
α
t
,
S
m
/
a
\alpha_t^{m/a} = {\alpha_{t,1}^{m/a},...,\alpha_{t,S}^{m/a}}
αtm/a=αt,1m/a,...,αt,Sm/a
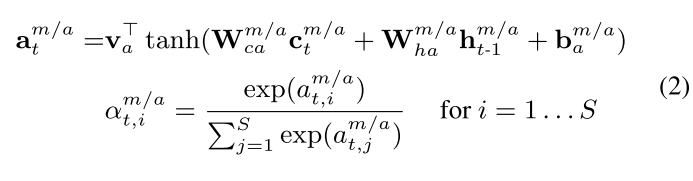
问题:
- 为什么使用tanh激活函数?
- 为什么还需要用一个 v a T v_a^T vaT映射?
- 对于这样一个异构存储器,我们需要计算不同模态的写入权重
E
t
∈
R
3
\mathcal{E}_t ∈ R^3
Et∈R3来分配运动特征
α
t
m
\alpha_t^m
αtm,外观特征
α
t
a
\alpha_t^a
αta 和当前存储内容
M
t
−
1
M_{t-1}
Mt−1的比例:
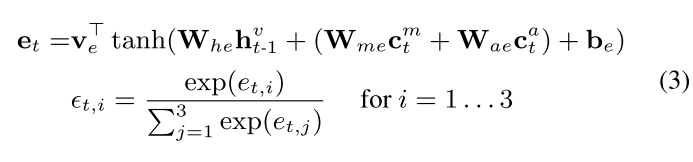
- 最后,当前时刻的写入值由3个内容决定:
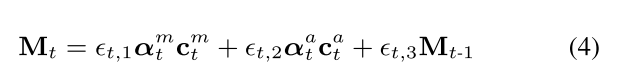
读操作 - 我们定义从存储槽
M
M
M中读取的分配比例为
β
t
=
{
β
t
,
1
,
.
.
.
,
β
t
,
S
}
\beta_{t} = \ \{\beta_{t,1},...,\beta_{t,S} \}
βt= {βt,1,...,βt,S}:
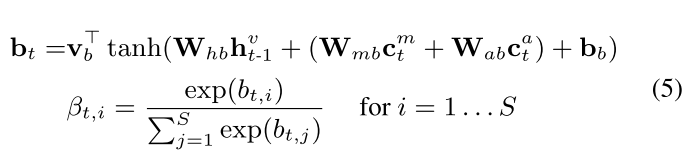
- 然后读出的内容 r t = ∑ i = 1 S β t , i ∗ m i r_t = \sum_{i=1}^{S}{\beta_{t,i} * m_i} rt=∑i=1Sβt,i∗mi
状态更新
我们在计算出读出内容
r
t
r_t
rt 后才计算三个隐藏状态的更新值:
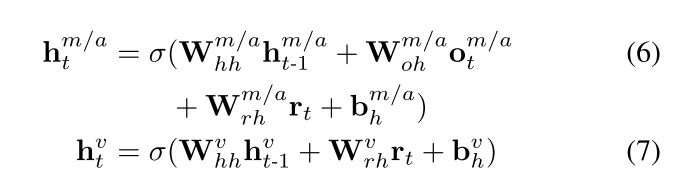
其中,我们在所有时刻的全局内容隐藏状态
{
h
1
v
,
.
.
.
,
h
N
v
v
}
\{h_1^v,...,h_{N_v}^v\}
{h1v,...,hNvv}将作为我们最后的 视频特征。
2.3 格外的问题存储器
我们重新设计了内存网络,以持久地存储以前的输入,并支持当前输入和内存内容之间的交互。
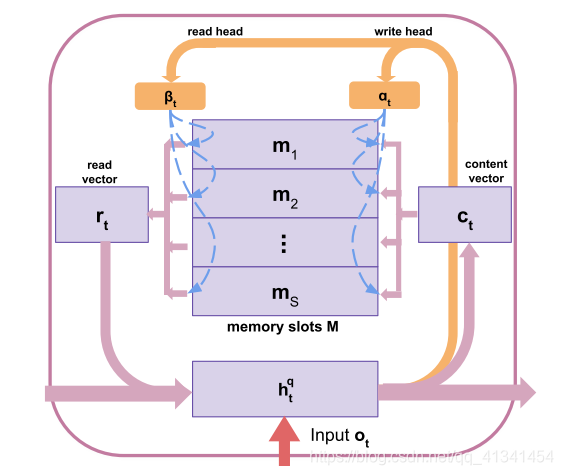
这里的存储器与之前的异构存储器差不多,只不过只有一个隐藏状态。
写操作
- 定义写入内容(content)
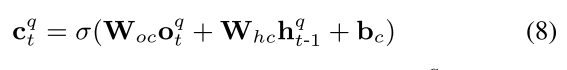
- 定义分配权重
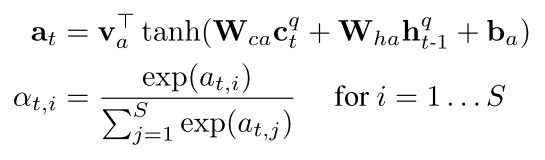
- 然后每个内存槽
m
i
m_i
mi写入的内容为:
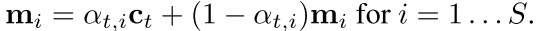
读操作
- 计算读取权重
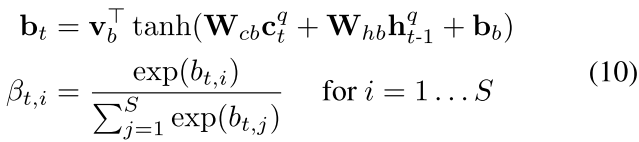
- 从每一个存储槽读取内容进行汇总
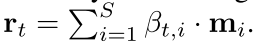
隐藏状态更新

最后,我们用所有时刻的隐藏状态
{
h
1
q
,
.
.
.
,
h
N
q
q
}
\{h_1^q,...,h_{N_q}^q\}
{h1q,...,hNqq}将作为我们最后的 视频特征。
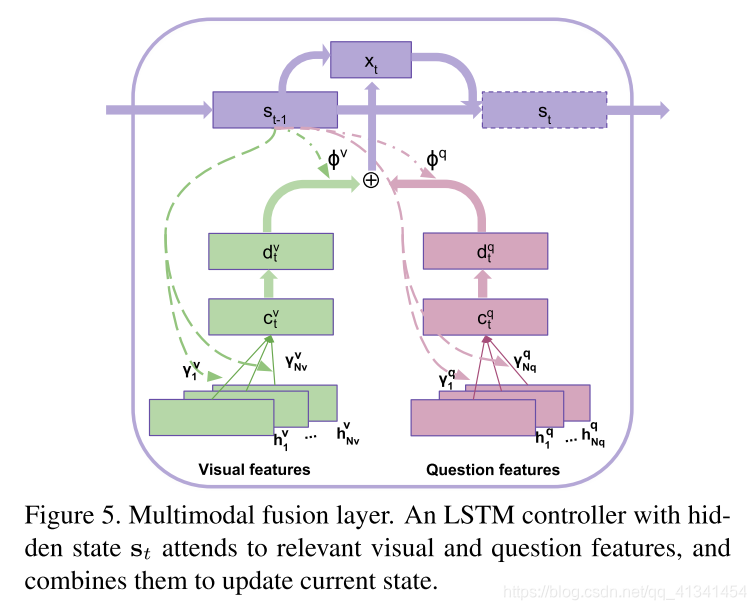
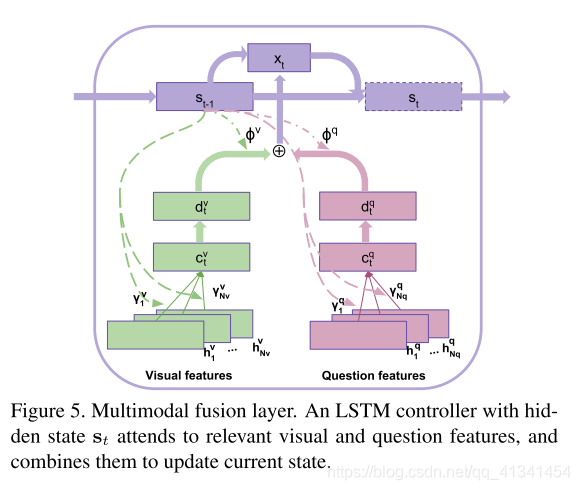
2.4 多模态融合以及推理
这个模型的核心是一个带一个隐藏状态
s
s
s的的LSTM控制器:
在每一次迭代的时候,控制器都使用 时间注意力机制 来处理输入的 视频特征 和 问题特征 的不同部分,然后使用 学习到的模态权重 结合处理过的特征,最后更新当前的状态
s
t
s_t
st。
时间注意力
在 t t t 步推理时,我们首先计算两个内容向量 c t v 和 c t q c_t^v和c_t^q ctv和ctq:
- 通过不同分段的视觉特征
h
t
v
h_t^v
htv 和
h
t
q
h_t^q
htq 计算 时序权重:
γ
1
:
N
v
v
和
γ
1
:
N
q
q
\gamma_{1:N_v}^v 和 \gamma_{1:N_q}^q
γ1:Nvv和γ1:Nqq:
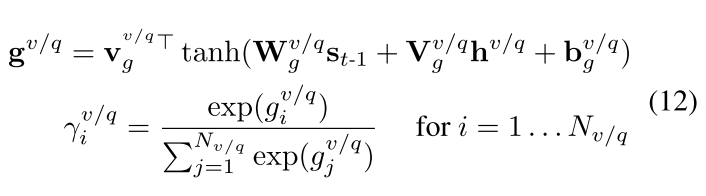
- 然后进行汇总再转换
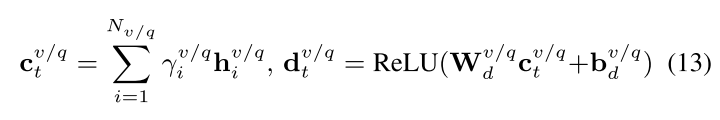
多模态融合
多模态分配权重通过之前的隐藏层状态和转换的向量计算:
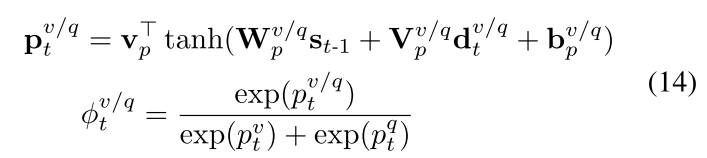
最后的融合知识通过求和获得:
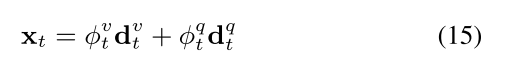
多步推理
当进行第
t
t
t 步推理的时候,LSTM控制器的隐藏状态
s
t
s_t
st 更新如下:
s
t
=
L
S
T
M
(
x
t
,
s
t
−
1
)
s_t = LSTM(x_t,s_{t-1})
st=LSTM(xt,st−1)
然后,这个推理步骤进行
L
L
L 次(本文设置
L
=
3
L=3
L=3)。在最后一次推理后的隐藏状态
s
L
s_L
sL 为最终被蒸馏的知识(distilled knowledge)。然后联合(concatenate)所有的隐藏状态为最终答案的表达
s
A
s_A
sA。
同时也使用标准的时间注意力机制来编码视频特征 o m o^m om 和 o a o^a oa(保持和ST-VQA一样)
2.5 答案的产生
多项选择
为了从
K
K
K 项候选答案中选择一个正确答案。我们将问题与每个候选答案分别进行联合,然后前向输入每个QA对,获得最终的答案特征序列
{
s
A
}
i
=
1
K
\{s_A\}_{i=1}^K
{sA}i=1K,最后使用一个线形层为每一个答案特征提供一个分数
s
=
{
s
p
,
s
1
n
,
.
.
.
,
s
K
−
1
n
}
s = \{s^p,s_1^n,...,s_{K-1}^n\}
s={sp,s1n,...,sK−1n}。其中,
s
p
s^p
sp为正确答案的分数。
在训练的时候,使用SVM损失进行训练:
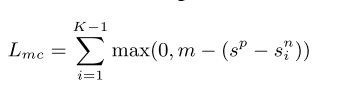
在测试的时候,选择分数最高的答案最为最终的正确答案。
开放式(Open-ended)任务
该任务是从一个预定义的答案集合(大小为C)中选择正确的单词。
所以,我们在最终的答案特征
s
A
s_A
sA 后添加一个线形层和SoftMax函数来计算每一个候选答案的概率
p
=
s
o
f
t
m
a
x
(
W
p
T
s
L
+
b
p
)
p = softmax(W^T_p s_L + b _p)
p=softmax(WpTsL+bp),其中
p
∈
R
C
p ∈ R^C
p∈RC。
最终使用交叉熵损失来进行训练:
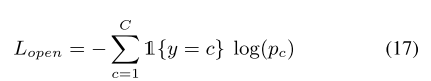
其中
y
y
y 是正确的标签。预测的时候,选择概率最大的候选答案即可
c
∗
=
a
r
g
m
a
x
(
p
)
c^* = argmax(p)
c∗=argmax(p)。
2.6 实现细节
- 网络优化器为 Adam, Batchsize = 32, learning rate = 0.001
- video and question encoders是两层LSTM,隐藏层大小为512
- memory slot的维度和隐藏状态的维度均是 256
- video 和 question memory 的大小分别是 30 和20.(和videos,questions的长度相当)
3. 实验以及讨论
3.1 标准数据集
在4个标准VideoQA数据集上进行评估。
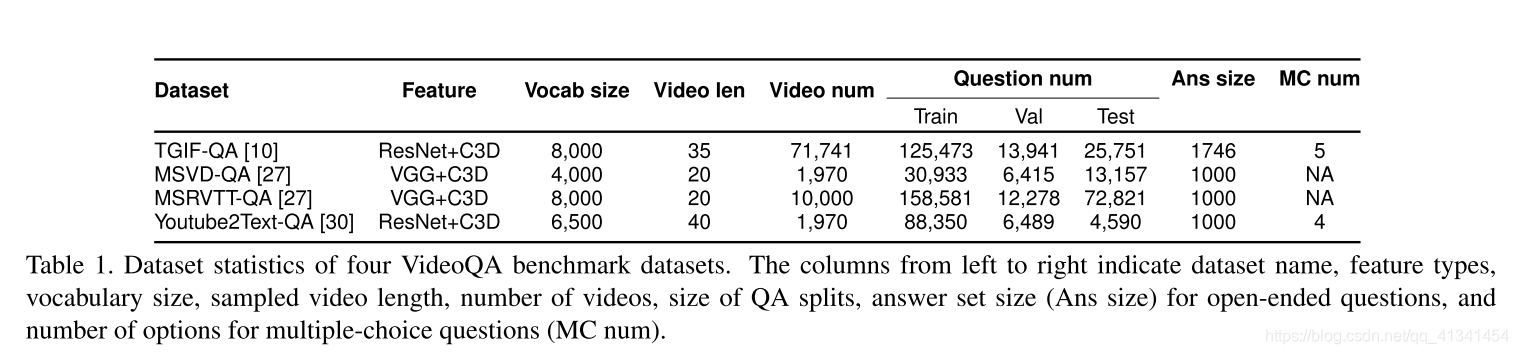
TGIF-QA 包含基于 TGIF数据集 上的72K张GIF动图 的 165K 个QA对。其包含以下问题类型:
- 计算给定动作的出现次数
- 给定频率,识别一个重复出现的动作
- 判别一个动作出现在一个给定动作之前还是之后
- 回答基于图像的问题
MSVD-QA 和 MSRVTT-QA 分别是基于 MSVD 数据集和 MSRVTT-QA 数据集提出的。包括五种不同的问题: What, Who, How, When, Where,开放问题的预选答案集大小为 1000。
YouTube2Text-QA 包括三种问题:What, Who, Other。
3.2 结果分析
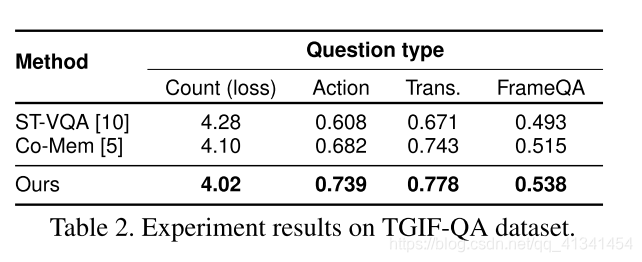
- TGIF-QA 结果
- MSVD-QA 数据集
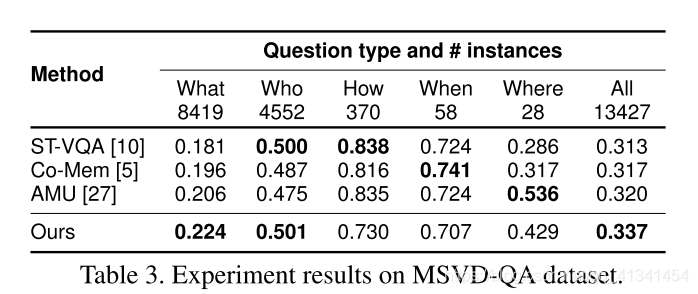
作者推荐使用 ST-VQA的源码,并自己从头实现 Co-Mem来得到原论文的数据
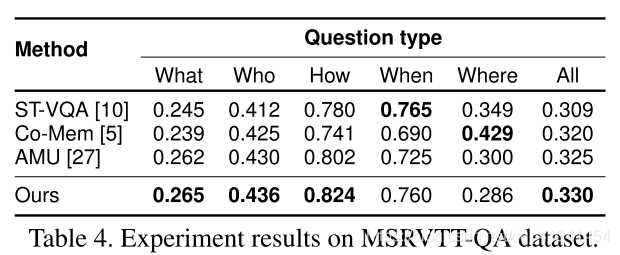
- MSRVTT-QA 数据集
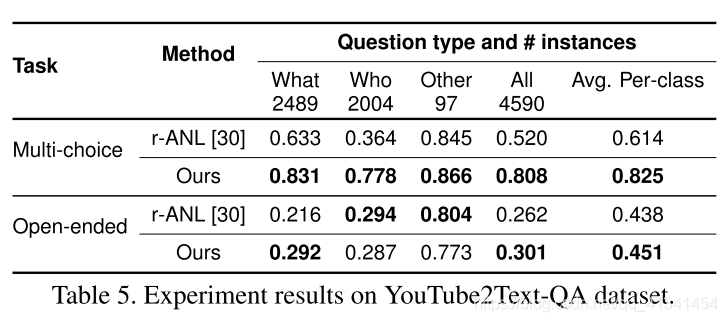
- YouTube2Text-QA 数据集
3.3 注意力可视化以及分析
3.3.1 时间注意力
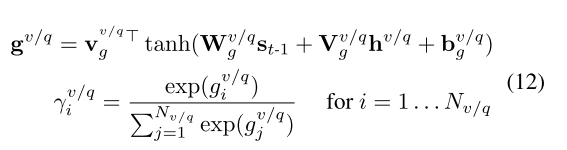
提取 表达式(12) 中个视觉和文本的注意力权重,然后将其画在条状图上。(深颜色表示大的权重,即对应的帧或者文本相对来说比较重要)。

上图表明模型能够有效的理解较复杂的问题(通过提出的问题存储器),即及时问题花了一部分来描述这个抽烟的男的,模型也依然重点注意开车的女性。
3.4 消融实验
包含两个消融实验:
- 研究在多模态融合的时候推理的迭代次数
- 研究模型每个组成部分的贡献
推理次数
在 MSVD-QA 数据集上,验证集精度从0.298->0.306(L=1->3),然后到0.307(L=5),但是却下降到0.304(L=7),所以为了平衡性能和速度,作者选择 L=3。
不同的结构
本文的最终结构:
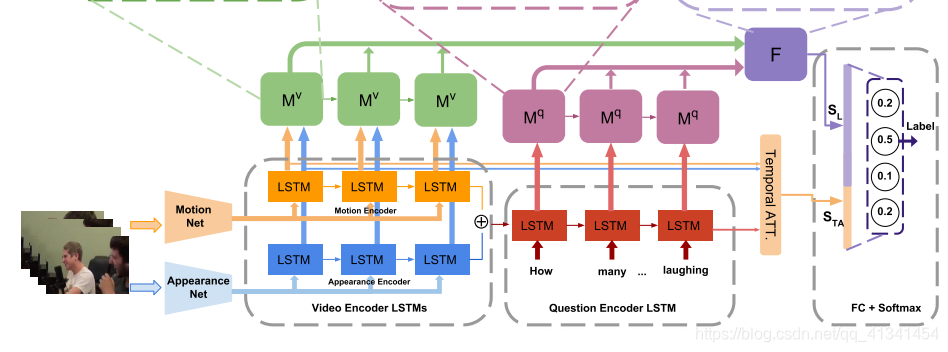
比较结果如下:
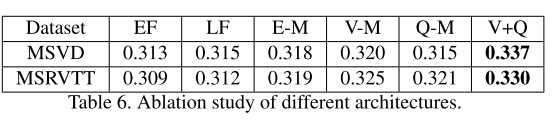
其中:
- Early Fusion(EF) 表示在早期阶段直接联合 视频特征(Video Feature)和运动特征(Motion Feature),然后再使用一个LSTM编码器
- Late Fusion(LF) 表示使用两个LSTM来分别编码,然后再联合
- Episodic Memory(E-M) 表示使用一个简单版的存储网络
- Visual Memory(V-M) 表示使用设计过的 异构存储器 M v M^v Mv
- Quetion Memory(Q-M) 表示使用设计过的 问题存储器 M q M^q Mq
- Visual and Question Memory(V + Q M) 是我们最终的模型。
4. 总结
本文提出一个 额外的存储器模型来捕获视频帧的全局上下文,和问题的复杂语义。同时设计一个新的多模态融合层来融合视觉和文本模态来提升多步推理精度。
暂存的问题
- 2.4 多步推理时改变了什么?有什么意义?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









