






Website:https://ningding97.github.io/fewnerd/
Github:https://github.com/thunlp/Few-NERD
文章目录
Abstract
-
目前问题:做 few-shot NER 的实体大部分都是粗粒度的
-
FEW-NERD,大规模人工标注的 few-shot NER 数据集,包括
- 8个粗粒度、66个细粒度实体类型
- 188238句话,4601160个词,每个词都有两个标签(粗粒度标签、细粒度标签)
-
FEW-NERD是第一个 few-shot NER 数据集,也是目前最大的人工构建的 NER 数据集
Introduction
- 之前常用的 NER 数据集如 OntoNotes、CoNLL’03、WNUT’17 等,只有4-18个粗粒度的实体类型,使得构建足够多的 “N-way”元任务和相关特征学习变得困难。
- 对于基准设置,作者设计了三个任务的数据集,具体区别在第六节介绍
- 标准的监督学习任务:FEW-NERD (SUP)
- 小样本任务:
N-way K-shot Sampling strategies

伪代码解释:
- 输入:
- 数据集 X X X
- 标签集 y y y
- N-way 的 N,所有标签的类型
- K-shot 的K,每个类别要采集多少个样本
- 输出:采样结果
- 初始化 support set S S S 为空,采样到的每个类别的计数 C o u n t [ i ] = 0 Count[i] = 0 Count[i]=0
- 循环
- 随机取一个样本 ( x , y ) ∈ X (x, y) ∈ X (x,y)∈X,尝试计算,加了这个样本之后有多少个类别 |Count|,和当前样本类别已经采集到的数量 Count[i]。
- 如果:当前已经采集到的样本类别 |Count| 超过了 N个,或者当前样本类别已经采集的数量 Count[i] 超过 2K 个,则舍弃当前采集到的样本,重新采样。
- 否则:将采集到的样本加入到 support set S S S 中,同时更新 Count[i]。
- 循环结束:直到 N 个类别采集到的样本数量都大于等于 K 个
Collection of FEW-NERD
-
实体类型是精心设计的:包括8大粗粒度类别一共66个细粒度类别
-
标注方法采用 IO,是这个类型或者不是这个类型,例如
-
标注的段落,每个类别选1000段,共66000段,平均每段长61.3个词
-
70个人标注,平均每人花费32小时
-
对每个批次的数据,选择10%的句子进行二次验证,句子精度高于95%

Data Analysis
FEW-NERD 和其他主流数据集比较
计算每个类别的相似度:
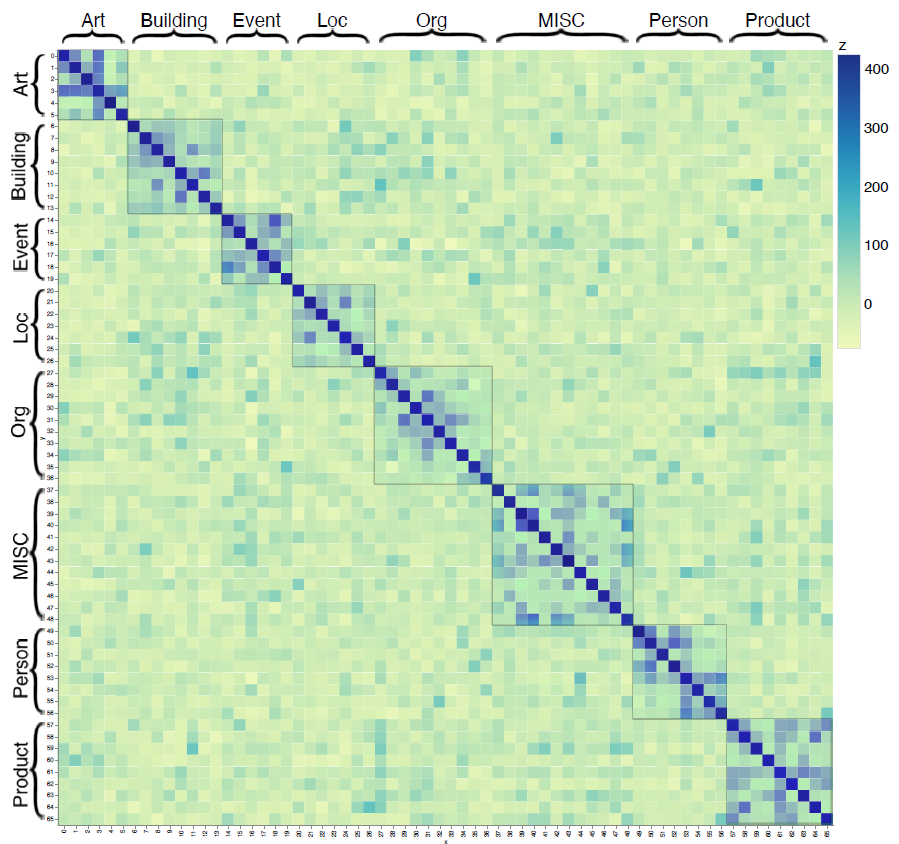
发现粗粒度类别的相似度差异大,粗粒度内的细粒度类别相似度高,这和直觉上是一致的。
Benchmark Settings
作者基于 FEW-NERD 做了三个任务的数据集。
Standard Supervised NER
- 数据集采用 FEW-NERD (SUP)
- train/dec/test = 7/1/2
Few-shot NER
Few-shot NER的核心思路是在少量样本中学习新的类别。
作者首先基于类别将数据集划分成 E t r a i n ; E d e v ; E t e s t E_{train}; E_{dev}; E_{test} Etrain;Edev;Etest,要求三个集合的类别不能重叠。通常一个句子中包含多个实体和多个类别,假设实体类别有A,B两种,那么这个句子随机分到包含 A 类别的集合或包含 B 类别的集合,同时将不属于这个集合的类别的实体类别标为 O。这样三个集合的类别互斥,从而让学习器学得新的类型。
划分的策略,有如下两种:
- 依据粗粒度的类别划分,train/dev/test 比例大致为:0.6/0.13/0.27,由此得到:FEW-NERD (INTRA)
- 依据细粒度的类别划分,train/dev/test 比例大致为:0.6/0.2/0.2,由此得到:FEW-NERD (INTER)
Experiments
使用了四个BERT变体模型,做上述三个任务
- BERT-Tagger —— supervised task
- Proto-BERT —— few-shot
- NNShot —— few-shot
- StructShot —— few-shot
四个模型的参考论文,最后两个模型出自同一论文
BERT-Tagger —— Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. ACL 2019.
Proto-BERT —— Snell J, Swersky K, Zemel R S. Prototypical networks for few-shot learning[J]. ACL 2017.
NNShot and StructShot —— Yang Y, Katiyar A. Simple and effective few-shot named entity recognition with structured nearest neighbor learning[J]. EMNLP 2020.
Supervised NER
在监督学习任务中,BERT-Tagger的结果为:
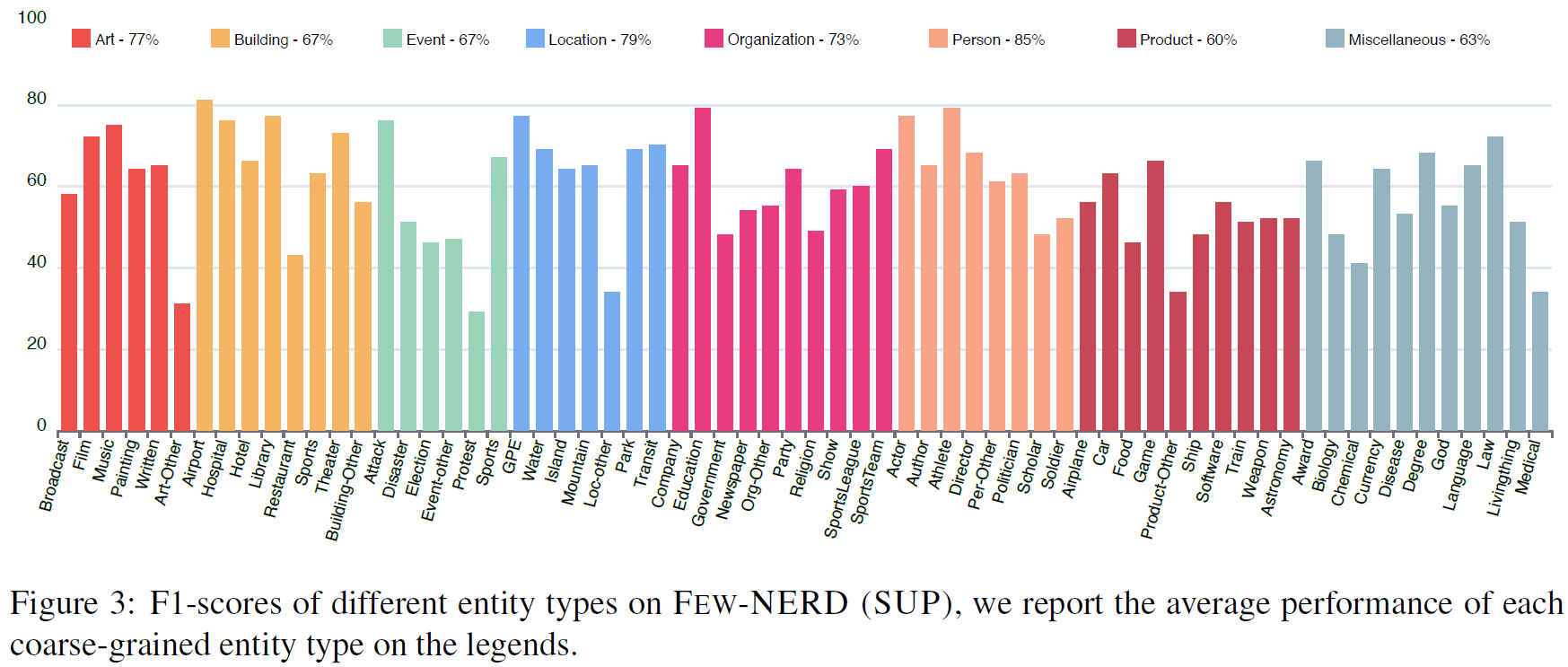
- 相比于其他的数据集,动不动0.9几的F1值,在Few-NERD的效果下降很多,因为实体类型多了
- Person 的平均F1值最高,Product 的平均F1值最低,所有粗粒度类别的 Other 类型的F1值都是最低。
- 因为这些类别的语义相对稀疏,并且难以识别分类
Few-shot NER
Few-shot 的基线,策略采用上文描述的策略,不过设置了四种采样设定:
- 5 way 1~2 shot
- 5 way 5~10 shot
- 10 way 1~2 shot
- 10 way 5~10 shot
各模型效果如下:
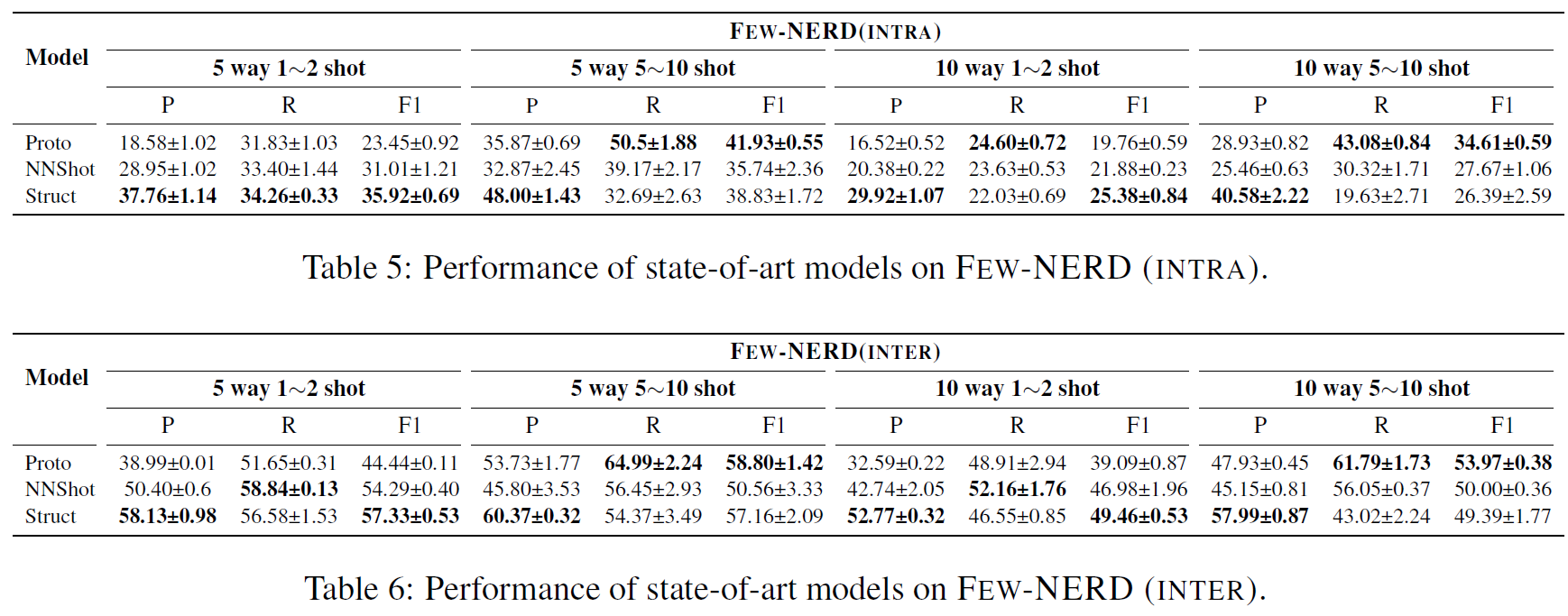
- 之前的SOTA模型效果都一般,任务很有挑战性
- 10 way 1~2 shot 的采样形式跑出来效果都相对较差,5 way 5~10 效果都相对较好
- 在 5~10 shot采样方式上 ProtoBERT 相比于其他两个的效果要好
- StructShot在两个任务上的提升最大,表明:维特比算法在推理阶段可以消除一些 false positive 的预测
- NNShot 和 StructShot 的最近邻机制不太稳定。prototypical models会更稳一些,因为原型的的本质实际上是正则化















 3199
3199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









