







摘要
过去的难点:
过去的都是粗粒度的;
Few-NERD:
一个大规模的人类注释的小样本NERD数据集,它具有8种粗粒度和66种细粒度实体类型的层次结构。Few-NERD由来自维基百科的188238个句子组成,包含4601160个单词,每个单词都被标注为上下文或两级实体类型的一部分。
Introduction
Few-NERD粗细粒度在下图中展示,其中内圈表示的是粗粒度,外圈是细粒度:
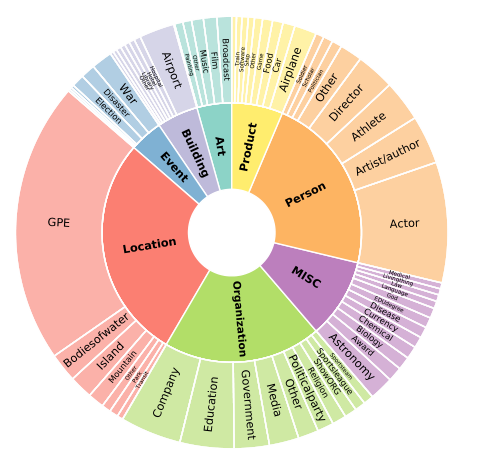
就与NERD数据集的划分类型是需要专业的人士的。而命名实体的少镜头学习研究工作主要面临两个挑战:第一,用于少样本学习的大多数数据集只有418种粗粒度实体类型,使得构建足够多的“N-way”元任务和学习相关特征变得困难。事实上,我们观察到大多数看不见的实体都是细粒度的。其次,由于缺乏基准数据集,不同作品的设置不一致,导致不清楚的比较。
该数据由188.2k个从维基百科文章中提取的句子组成,491.7k个实体;对于基准设置,我们设计了三个基于少量NERD的任务,包括一个标准监督任务(少量NERD(SUP))和两个少量快照任务(少量NERD-INTRA)和FEWNRTD(INTER));
问题定义
NER
输入: 一个句子
x
=
x
1
,
x
2
,
.
.
.
,
x
t
x = {x_1, x_2,...,x_t}
x=x1,x2,...,xt
输出:对于每个
x
i
x_i
xi分配
y
i
∈
Y
y_i\in{Y}
yi∈Y来指明标记是命名实体的一部分或者不属于任何实体(用O来表示)
Y
Y
Y是预定义的实体类别
Few-shot NER
Few-shot learning
在少样本的场景下,样本被按照批次(episode)组织成N-way-K-shot形式的数据。每个批次的数据又被组织成两个集合,support set 支持集
S
t
r
a
i
n
=
{
x
(
i
)
,
y
(
i
)
}
i
=
1
N
∗
K
S_{train} = \{x^{(i)}, y^{(i)}\}_{i=1}^{N*K}
Strain={x(i),y(i)}i=1N∗K 和 query set 查询集
Q
t
r
a
i
n
=
{
x
(
j
)
,
y
(
j
)
}
j
=
1
N
∗
K
Q_{train} = \{x^{(j)}, y^{(j)}\}_{j=1}^{N*K}
Qtrain={x(j),y(j)}j=1N∗K,并且
S
∩
Q
=
∅
S\cap{Q} = \emptyset
S∩Q=∅。其中support set用于学习,query set用于预测。其含义是,在每一批(episode)的support set中含有N种类型的实体,每种类型有K个实体,query set含有与support set同类型的实体。在测试过程中,所有类在训练阶段都是不可见的,并且通过使用支持集
S
t
e
s
t
S_{test}
Stest的少数标记示例,few-shot学习系统需要预测未标记的查询集
Q
t
e
s
t
(
S
∩
Q
=
∅
)
Q_{test}(S\cap{Q}=∅)
Qtest(S∩Q=∅)。模型通过对support set的学习,来预测query set的标签。
采样策略
由于NER是一个跟语境强相关的任务,采样通常在句子层面进行。又由于一句话中可能含有多个类型的多个实体,一般很难通过句子级别的采样严格满足N-way-K-shot的场景设定。因此,我们设计了基于贪心策略的更为宽松的采样方法。该采样方法能够将每个实体类型的数量限制在K~2K之间,即每次随机抽样一句话加入集合,计算当前集合中的实体类型数量和每个实体类型的实例数量,若它们超过N或2K,则舍弃这句话;否则,将这句话加入集合中,直到满足N个实体类型,每个类型至少K个实体为止。

数据分析
数据集大小和分布
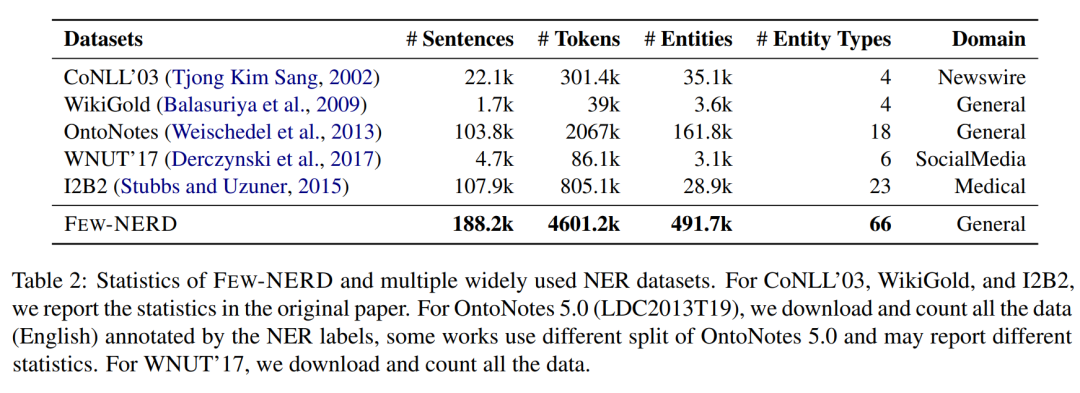
Few-NERD是第一个为Few-shot场景设计的数据集,同时也是最大的人工标注的NER数据集之一,相关的统计如表2所示。可以看出,Few-NERD包含了18万余条句子,49万余个标注的实体,460余万个字符,并且有66个类别,显著超越了之前的基准数据集。因此,Few-NERD不光可以做Few-shot NER任务,在标准的监督学习NER任务上同样具有挑战性(见实验章节)。















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









