






文章目录
Abstract
- 基于最近邻和结构化推理,构建了一个简单的 few-shot NER 系统
- 最近邻分类器在特征空间上比其他元学习方法有效
- 本文提出的方法在标准 few-shot NER 任务中取得的 SOTA
Introduction
-
将现有的 few-shot 分类方法应用到 few-shot NER中 有两个挑战:
- NER 本质上是一个结构化的学习问题:标签和上下文有关,对标签相关性进行建模至关重要,而现有 few-shot 分类方法直接独立的对每个标记进行分类。
- NER有一个问题,就是 O 这个标签其实是无法用 prototype 表示的,因为不同数据集的O含义不一样, 用原来的原型网络学习的O会包含噪音
-
本文针对 few-shot NER 提出一个简单有效的 StructShot方法
- 不像原来那样,为每个类型学习一个原型,本文为一句话中每个词都学习一个上下文表示(用标准监督NER模型学得)
- 元学习方法通过训练来对 few-shot 进行评估,本文不需要,在评估的时候用最近邻分类方法和维特比算法进行预测
Problem Statement and Setup
- few-shot NER系统只能用少量的标注数据,需要学习新的、没见过的实体类型。因此 query set 里的实体类型不能和 support set 有交集
- 之前的 episode evaluation 采样方式默认所有实体类型是均匀分布,没有考虑到实际情况。本文建议使用标准NER数据集的原始test数据集来做评估,不再进行采样
- support set 采样方法采用贪心采样策略

Model
模型有点类似 pretrain + fine-tuning
Nearest neighbor classification for few-shot NER
-
StructShot 的主干是 NNShot
- NNShot 原理是获取句子中每个词的上下文向量表示,在向量空间中,采用最近邻原理计算词的相似度,在向量空间中选最近词的类别进行标注
-
本文用了考虑了两种方法进行 embedding,参数用原论文默认的,最后都统一加了一层线性分类层
- BiLSTM NER model
- BERT-based NER model
Structured nearest neighbor learning
-
在小样本中,由于 Episodic Training 方式,训练集和测试集的数据分布完全不一样,所以在LSTM后面接CRF来进行解码是行不通的,因为CRF本质上是一个统计模型,不适用于训练和测试分布不一致的情况。
-
StructShot 在训练阶段,不采用CRF,在推理的时候只用维特比算法。在预测的时候,由于预测用的是原来完整的test,所以预测用的也是完整的CRF模型。
其中的 transition score 类似[2],只是[2]是复制,这里是平分;emission score 是对 d c d_c dc 做softmax,得到这一token属于各标签的概率。这里其实也没有把 O 单独处理,不过由于没有计算 prototype,所以理论上还是合理的。
最后就是用维特比算法解码:
y
∗
=
arg
max
y
∏
t
=
1
T
p
(
y
t
∣
x
)
×
p
(
y
t
∣
y
t
−
1
)
y^{*}=\arg \max _{y} \prod_{t=1}^{T} p\left(y_{t} \mid x\right) \times p\left(y_{t} \mid y_{t-1}\right)
y∗=argymaxt=1∏Tp(yt∣x)×p(yt∣yt−1)
前半部分就是 emission score,后半部分就是 transition score。
其实,模型的整体框架如下:
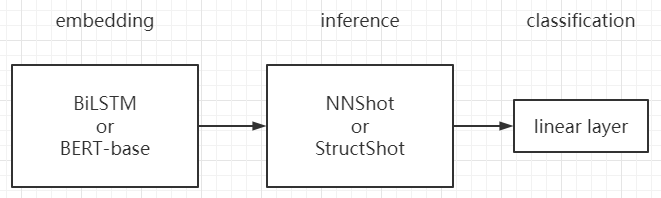
Experiments
Tag set extension
将 OntoNotes 数据集所有的 18 种标签类型分为ABC 3组,每组6个标签。
在每次实验的时候,将一组6个标签作为验证,剩下两组12个标签用于训练。为了不在训练的时候看到新类型,将训练集种属于验证的6个类型的标签改成O,同时将验证集中属于训练的12个标签也改成O。
Domain Transfer
在通用数据集OntoNotes上训练,在领域数据集上进行测试,例如新闻CoNLL,医药I2B2和社会WNUT领域。
Competitive systems
以 LSTM 为 encoder 做了三组实验,以 BERT-base 为 encoder做了五组实验。采样又分了 one-shot 和 5-shot两组
对比实验用了五种方法:
- Prototypical Network:原型网络
- SimBERT:简单BERT + 线性层
- PrototypicalNet+P&D:用pair-wise embedding 和 dependency transfer mechanism改进的原型网络[2]
- NNShot
- StructShot
Results
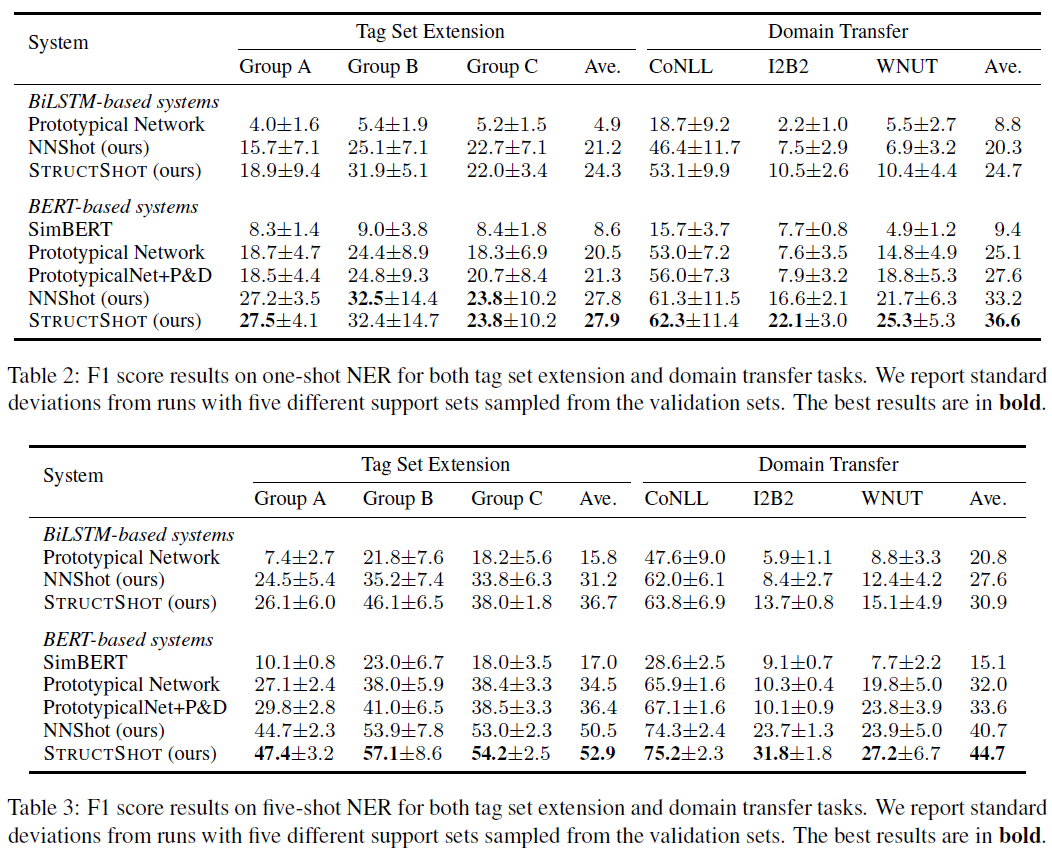
- IO 标注要比 BIO 标注更好,因为 BIO 标注就更减少了每个标签样本的数量
- 引入标签之间的依赖要比单纯的最近邻提升 2.4% 和 4%,表明在使用 CRF 的时候,分别算两个 score 还是有用的
- 预训练在低资源 NLP 任务中能带来非常多的先验知识,但是特定的 task-specific 知识又往往更重要。作者通过对比直接用 simBERt 和自己的 StructShot,发现 task-specific 知识让模型提升了 20% – 35%。
- 在 1-shot 时,domain transfer 做的比较好,因为毕竟会有重叠的 tag;到了 5-shot,tag set extension 就做的更好了,因为毕竟同一个 domain,更简单一些
- 5-shot 实验结果要比 1-shot 更稳定,方差更小
- 如果改成 episode 的学习方式,性能还会提升 5% 左右,但是作者觉得这样不贴近实际
- 现在这样做 NER 还不太可用,但是 ① 如果 domain 差不多,70 多的性能也还凑合 ② 遇到新 domain,可以先用本文的方法应急(无需重新训练),然后再同时慢慢训练一个更精确的
- finetune BERT 的时候(就是本文的训练过程),使用这种传统的 NER loss 要好于 proto loss,说明 meta learning 做 NER 还不行
[1] Yang Y, Katiyar A. Simple and effective few-shot named entity recognition with structured nearest neighbor learning[J]. EMNLP, 2020.
[2] Yutai Hou, Wanxiang Che, Yongkui Lai, Zhihan Zhou, Yijia Liu, Han Liu, and Ting Liu. Few-shot slot tagging with collapsed dependency transfer and label-enhanced task-adaptive projection network. ACL2020.
论文笔记 – Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning















 1503
1503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









