






摘要
针对关系抽取任务,本文提出一种混合的 attention 原型网络。本文提出的方法能够在更快的时间内收敛,效果更好、
介绍
本文混合的 attention 原型网络包括两部分:
- Instance-level Attention:可以选择更富含信息的实例,并在训练过程中去噪
- Feature-level Attention:强调特征维度的重要性,为不同关系制定距离函数,并缓解特征稀疏问题
混合的 attention 原型网络优点:更有效和鲁棒,训练限制少,运行快
方法
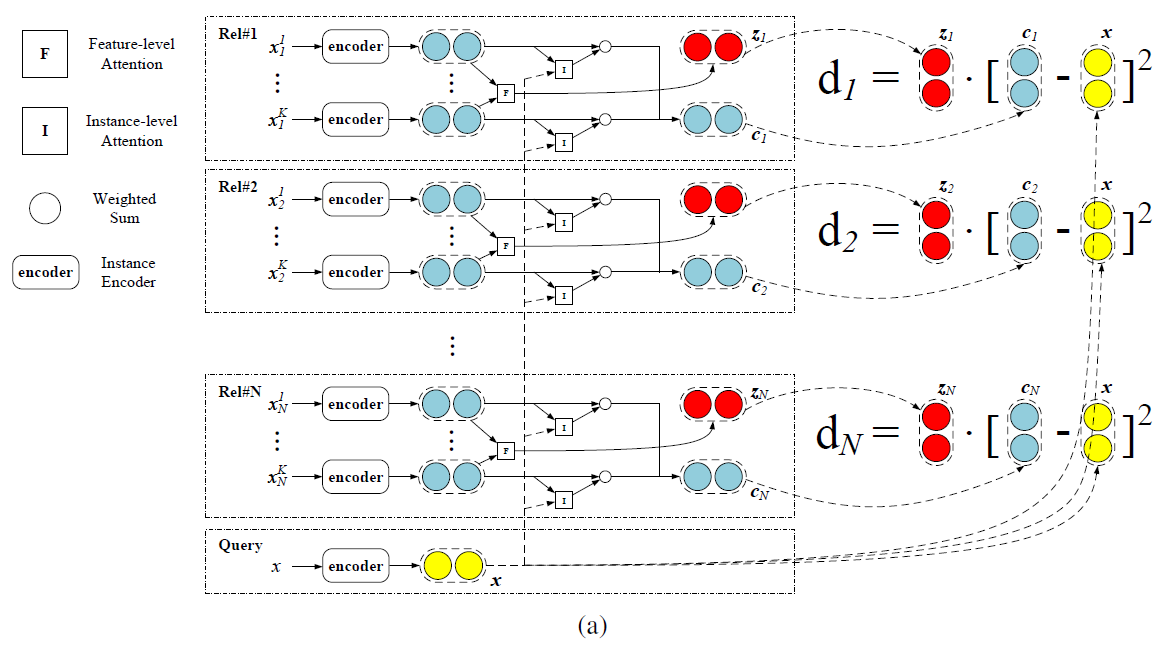
混合的 attention 原型网络框架包含三个部分
- Instance Encoder
- Prototypical Networks
- Hybrid Attention
Instance Encoder
- 使用 GloVe 词向量,参考 PCNN,每个词的 embedding 是词向量 + 位置编码
- 使用 CNN 做编码器。以为卷积,最大池化,得到句向量
- Query 的句子也是同样编码方法
- 作者用 CNN 是综合了变现与计算效率的考量
Prototypical Networks
- 计算 support set 中每个关系的原型
- 对每个关系,输入是 K 个编码的句向量,输出一个 prototype 向量
- 原本的方式是简单平均: c i = 1 n i ∑ j = 1 n i x i j \mathbf{c}_{i}=\frac{1}{n_{i}} \sum_{j=1}^{n_{i}} \mathbf{x}_{i}^{j} ci=ni1∑j=1nixij【关系 i 的 原型向量】
- 然后就是计算 query 编码与每个原型的距离,做一个 softmax,得到预测类别。
p ϕ ( y = r i ∣ x ) = exp ( − d ( f ϕ ( x ) , c i ) ) ∑ j = 1 ∣ R ∣ exp ( − d ( f ϕ ( x ) , c j ) ) p_{\phi}\left(y=r_{i} \mid x\right)=\frac{\exp \left(-d\left(f_{\phi}(x), \mathbf{c}_{i}\right)\right)}{\sum_{j=1}^{|\mathcal{R}|} \exp \left(-d\left(f_{\phi}(x), \mathbf{c}_{j}\right)\right)} pϕ(y=ri∣x)=∑j=1∣R∣exp(−d(fϕ(x),cj))exp(−d(fϕ(x),ci))
Hybrid Attention
本文混合的 attention 原型网络包括两部分:
- Instance-level Attention:可以选择更富含信息的实例,并在训练过程中去噪
- Feature-level Attention:强调特征维度的重要性,为不同关系制定距离函数,并缓解特征稀疏问题
Instance-level Attention
- 这一 attention 用于计算原型
- 将原来计算原型取平均的方式改成 attention: c i = ∑ j = 1 n i α j x i j \mathbf{c}_{i}=\sum_{j=1}^{n_{i}} \alpha_{j} {x}_{i}^{j} ci=∑j=1niαjxij
- 其中
α
j
α_j
αj 是权重,定义如下:
- g():线性层
- ⊙ \odot ⊙:向量点击
- σ():sigmoid 激活函数
α j = exp ( e j ) ∑ k = 1 n i exp ( e k ) e j = sum { σ ( g ( x i j ) ⊙ g ( x ) ) } \begin{aligned} \alpha_{j} &=\frac{\exp \left(e_{j}\right)}{\sum_{k=1}^{n_{i}} \exp \left(e_{k}\right)} \\ e_{j} &=\operatorname{sum}\left\{\sigma\left(g\left(\mathbf{x}_{i}^{j}\right) \odot g(\mathbf{x})\right)\right\} \end{aligned} αjej=∑k=1niexp(ek)exp(ej)=sum{σ(g(xij)⊙g(x))}
- 目的:缓解数据集噪声的情况。就是说,在这个关系的实例中,与查询向量更类似的,会有更高的注意力权重。所以那些被错误标注的,往往会有更低的权重。总之就是比平均好。
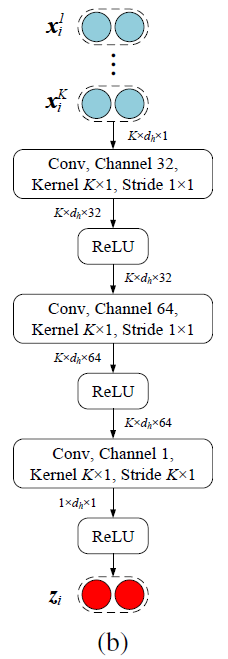
Feature-level Attention
- 这一 attention 用于 query 归类
- 出发点:先前研究论证了距离函数的选择会影响这个网络的能力。小样本数据集意味着特征是稀疏的,简单的欧式距离能力不足。虽然特征空间是稀疏的,但总会有些维度有更强的区分能力,所以需要特征层面的注意力机制。
- 修改距离计算: d ( s 1 , s 2 ) = z i ⋅ ( s 1 − s 2 ) 2 d\left({s}_{1}, {s}_{2}\right)={z}_{i} \cdot\left({s}_{1}-{s}_{2}\right)^{2} d(s1,s2)=zi⋅(s1−s2)2
- 这里的关系 i 的注意力得分就不是一个标量了,而是一个得分向量 z i z_i zi
- 就是将该关系下的K个实例的编码向量
(
x
1
,
x
2
,
.
.
.
,
x
K
)
(x_1, x_2, ..., x_K)
(x1,x2,...,xK) 进行多次卷积得到的,具体操作如图
实验
实验操作
- 考虑到训练集有64类关系,更多的关系会使模型在训练集得到更好地结果,因此,对每个Batch随机采样20个关系做N-K。
- 其他所有超参数在验证集上调参。用grid search。特别提到了初始学习率和权重衰减值。优化策略主要体现在学习率方面。按步数衰减学习率,做了非常多的尝试。【到时复现再说】
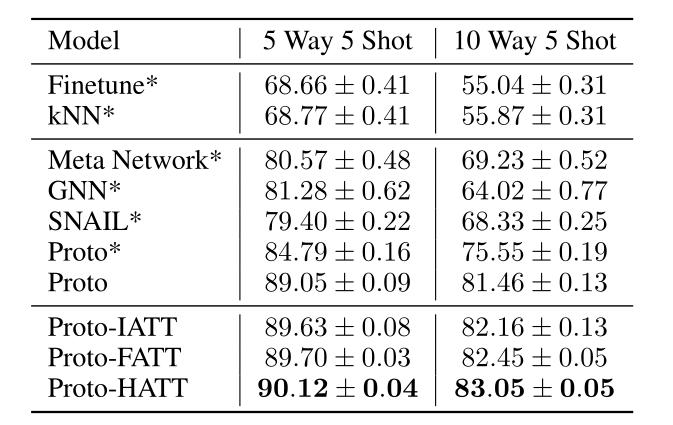
实验结果
- 【笔记中不全,感兴趣可阅读原文】
- 全文没有做N-way 1-Shot 因为这样没法算注意力
- 在数据集中按照一定比例替换标签(制造错误标注),进行对比

- 没有噪声时与其他baseline的对比
- 特征级别的attention得分对比:对隐藏层embedding的230特征进行排序,最高的20个与最低的20个做PCA

个人想法
- 对于N-way 1 Shot 问题,是否有类似的办法?
- 作者也提到,今后尝试混合注意力机制与其他模型的适用性。
- 在FewRel 2.0数据集的两个任务上,基于这个模型应该也有一定的发挥空间。















 3594
3594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









