







文章目录
- Python 常见异常
- Python 多线程
- python中list、tuple、dict、set等类型有什么区别?
- 函数传参有哪些形式?分别有什么特点?
- 默认参数陷阱问题
- 浅拷贝和深拷贝的区别
- zip 的用法。迭代器的长度不一致时,是如何处理的,有什么替代方案吗?
- 高阶函数map/reduce/filter/sorted的用法分别是怎样的?举例说明
- 闭包的概念是什么?举例说明
- 匿名函数有什么好处?请举一个例子说明其用法
- 装饰器的概念是什么?如何使用?
- 偏函数partial的概念是什么?
- 类专有方法:
- is和==的区别。
- 内存管理
- 垃圾回收机制
- set、dict、list、tuple原理
- python str中 find() 和 index() 的区别。
- 实例方法、静态方法、类方法的区别
- \_\_new__和\_\_init__的区别
- GIL线程全局锁
- Python 为什么存在GIL
- Python有GIL为什么还需要线程同步?
- 协程
- read, readline和readlines
- 生成器与迭代器的概念分别是什么?
- 正则的 match 和 search 的区别
- 举例说明什么情况下会出现KeyError、TypeError、ValueError。
- 如何读取大文件,例如内存只有4G,如何读取一个大小为8G的文件?
- 单下划线和双下划线的区别
- 什么是Python自省?
- 变量的查找顺序
Python 常见异常
- AssertionError:assert断句失败
- AttributeError:对象没有相应的属性
- IOError:输入/输出异常,基本上是无法打开文件
- ImportError:无法导入相应的包
- IndentationError:语法错误,代码没有正确对齐
- IndexError:下标超出边界
- KeyError:字典没有相应的key
Python 多线程
通过 threading 包导入 Thread 对象,继承Thread对象,并重写run方法,run方法里面写上需要并行的内容,最后要通过实例.start()方法来运行多线程。
python中list、tuple、dict、set等类型有什么区别?
list:列表(链表的数据结构)有序的项目,通过索引进行查找,使用方括号"[]“;
tuple:元组,元组将多样的对象集合道一起,不能修改,通过索引进行查找,使用括号”()“;
dict:字典,字典是一组键(key)和值(value)的组合,通过键(key)进行查找,没有顺序,使用大括号”{}“;
set:集合,无序,元素只出现一次,自动去重,使用"set([])”。
应用场景:
list,简单的数据集合,可以使用索引;
tuple,把一些数据当作一个整体去使用,不能修改;
dict,使用键和值进行关联的数据;
set,数据只出现一次,只关心数据是否出现,不关心其位置。
函数传参有哪些形式?分别有什么特点?
1. 位置参数
调用函数时传的实参与函数的形参位置上一一对应的参数,如下:
def info(name,age,major):
print("姓名:%s"%(name))
print("年龄:%s"%(age))
print("职业:%s"%(major))
info("zhulang",27,"IT") #实参与形参一一对应
打印结果为:
姓名:zhulang
年龄:27
职业:IT
2. 默认参数
注意: 默认参数之后不可以存在非默认参数!
在定义函数的时候,给形参一个默认的值,如下:
def info(name,major,age=25): #默认参数必须放在位置参数后面,否则出错
print("姓名:%s"%(name))
print("年龄:%s"%(age))
print("职业:%s"%(major))
info("zhulang","IT")
打印结果为:
姓名:zhulang
年龄:27
职业:IT
3. 可变参数 *
可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个,*args将所有的实参的位置参数聚合到一个元组,并将这个元组赋值给args,如下:
def calc(*nums):
sum = 0
for n in nums:
sum += n
return sum
>>> calc(*[1,2,3], *[4])
10
>>> calc()
0
4. 关键字参数 **
关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict,在传递参数时用等号(=)连接键和值
def person_info(name, age, **kw):
print("name", name, "age", age, "other", kw)
>>> person_info("zhulang", 12)
name zhulang age 12 other{}
>>> person_info("zhulang", 27, city = "Beijing")
name zhulang age 27 other {'city':'Beijing'}
5. 命名关键字参数
和普通关键字参数不同,命名关键字参数需要一个用来区分的分隔符*,它后面的参数被认为是命名关键字参数
#这里星号分割符后面的city、job是命名关键字参数
person_info(name, age, *, city, job):
print(name, age, city, job)
>>> person_info("zhulang", 17, city = "Beijing", job = "Engineer")
zhulang 17 Beijing Engineer #看来这里不再被自动组装为字典
默认参数陷阱问题
看一个经典的陷阱:
def f(a=[]):
a.append("xyz")
return a
print(f())
print(f())
print(f([]))
print(f([]))
运行结果如下:
['xyz']
['xyz', 'xyz']
['xyz']
['xyz']
陷阱在于,默认的列表被重用了。用 python 中的哲学解释就是:一切皆是对象!
由此可见,Python中函数默认参数值是在代码编译阶段就已经被定义,即指向一个已经定义好的对象,假设内存地址为0x0010。也就是说之后函数调用时:
- 如果是传入了一个 [] ,这是一个新对象,那么这个对象的地址不是0x0010;
- 如果是无参调用,那么,默认参数就是那个在编译阶段就已经存在的对象的指针0x0010,没有新建一个数组对象,不管调用几次都在处理这个数组对象,该数组就相当于一个全局数组了。
前面举例的都是 list,实际上,所有函数用可变类型对象作为默认参数都可能引起陷阱。
- 可变类型的对象,如:dict、list
- 不可变类型的对象,如:tuple、int、str、set
避免陷阱的方法:默认值使用None代替
def f(a=None):
if a==None:
a=[]
a.append("xyz")
return a
print(f())
print(f())
print(f([]))
print(f([]))
运行结果:
['xyz']
['xyz']
['xyz']
['xyz']
浅拷贝和深拷贝的区别
- 浅拷贝,浅拷贝仅仅复制了对象中的浅层元素,即对象内部的可变对象还是引用。
- 深拷贝,完全拷贝了一个副本,对象内部所有元素地址都不一样。
# 浅拷贝例子
>>> import copy
>>> a = [[1,2,3]]
>>> b = copy.copy(a)
>>> a, b
([[1, 2, 3]], [[1, 2, 3]])
>>> a[0].append(1) # b 同时也发生了变化
>>> a, b
([[1, 2, 3, 1]], [[1, 2, 3, 1]])
# 深拷贝例子
>>> import copy
>>> a = [[1,2,3]]
>>> b = copy.deepcopy() # b 独立于 a
>>> a, b
([[1, 2, 3]], [[1, 2, 3]])
>>> a[0].append(1) # b 不变
>>> a, b
([[1, 2, 3, 1]], [[1, 2, 3]])
zip 的用法。迭代器的长度不一致时,是如何处理的,有什么替代方案吗?
向最短的看齐,或用zip_longest()向最长的看齐(缺的默认用None补全,也可以自定义不全内容)
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
a = [1, 2, 3, 4]
b = [4, 5, 6, 8, 9, 0]
zipped_data = list(zip(a, b))
print(zipped_data) # [(1, 4), (2, 5), (3, 6), (4, 8)]
list1, list2 = zip(*zip(a, b))
print(list1, list2) # (1, 2, 3, 4) (4, 5, 6, 8)
迭代器长度不一致时的替代方案:itertools.zip_longest(),以元素最多对象为基准,使用fillvalue的值来自定义填充,否则用None填充:
import itertools
list1 = ["A", "B", "C", "D", "E"] # len = 5
list2 = ["a", "b", "c", "d", "e"] # len = 5
list3 = [1, 2, 3, 4] # len = 4
temp = itertools.zip_longest(list1, list3)
print(list(temp)) # [('A', 1), ('B', 2), ('C', 3), ('D', 4), ('E', None)]
temp = itertools.zip_longest(list1, list3, fillvalue='默认值')
print(list(temp)) # [('A', 1), ('B', 2), ('C', 3), ('D', 4), ('E', '默认值')]
高阶函数map/reduce/filter/sorted的用法分别是怎样的?举例说明
1. map()
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。 pyhont2 返回列表,python3 返回迭代器。
def square(x):
return x ** 2
print(map(square, [1, 2, 3, 4, 5])) # <map object at 0x0000000002417130>
print(list(map(square, [1, 2, 3, 4, 5]))) # [1, 4, 9, 16, 25]
print(list(map(lambda x: x ** 2, [1, 3, 4, 5]))) # [1, 9, 16, 25], 使用 lambda 匿名函数
如果函数有多个参数, 但每个参数的序列元素数量不一样, 会根据最少元素的序列进行:
listx = [1, 2, 3, 4, 5, 6, 7] # 7 个元素
listy = [2, 3, 4, 5, 6, 7] # 6 个元素
listz = [100, 100, 100, 100] # 4 个元素
list_result = map(lambda x, y, z: x ** 2 + y + z, listx, listy, listz)
print(list(list_result))
# 结果为前四个元素的运算
# [103, 107, 113, 121]
2. reduce()
reduce() 函数会对参数序列中元素进行连续操作。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
from functools import reduce
def mul(x, y):
return x * y
res = reduce(mul, [1, 2, 3, 4, 5])
res # 120
3. filter()
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中
def is_odd(n):
return n % 2 == 1
tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8])
print(tmplist) # <filter object at 0x0000000001DE8A00>
print(list(tmplist)) # [1, 3, 5, 7]
4. sort()
sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
aList = ['Google', 'Runoob', 'Taobao', 'Facebook']
aList.sort()
print(aList) # ['Facebook', 'Google', 'Runoob', 'Taobao'] 默认升序
aList.sort(reverse=True) # 降序
print(aList) # ['Taobao', 'Runoob', 'Google', 'Facebook']
sort函数和sorted函数的区别在于,sort会直接改变原对象,sorted会返回一个新的对象,不改变原对象,用法上是L.sort,参数方面是完全一样的
闭包的概念是什么?举例说明
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
# 闭包函数的实例
# outer是外部函数 a和b都是外函数的临时变量
def outer(a):
b = 10
# inner是内函数
def inner():
#在内函数中,用到了外函数的临时变量
print(a + b)
# 外函数的返回值是内函数的引用
return inner
if __name__ == '__main__':
# 在这里我们调用外函数传入参数5
#此时外函数两个临时变量 a是5 b是10 ,并创建了内函数,然后把内函数的引用返回存给了demo
# 外函数结束的时候发现内部函数将会用到自己的临时变量,这两个临时变量就不会释放,会绑定给这个内部函数
demo = outer(5)
# 我们调用内部函数,看一看内部函数是不是能使用外部函数的临时变量
# demo存了外函数的返回值,也就是inner函数的引用,这里相当于执行inner函数
demo() # 15
demo2 = outer(7)
demo2() #17
在基本的python语法当中,一个函数可以随意读取全局数据,但是要修改全局数据的时候有两种方法:1 global 声明全局变量 2 全局变量是可变类型数据的时候可以修改。
在闭包内函数也是类似的情况。在内函数中想修改闭包变量(外函数绑定给内函数的局部变量)的时候:
-
在python3中,可以用nonlocal 关键字声明 一个变量, 表示这个变量不是局部变量空间的变量,需要向上一层变量空间找这个变量。
-
在python2中,没有nonlocal这个关键字,我们可以把闭包变量改成可变类型数据进行修改,比如列表。
#修改闭包变量的实例
# outer是外部函数 a和b都是外函数的临时变量
def outer( a ):
b = 10 # a和b都是闭包变量
c = [a] #这里对应修改闭包变量的方
闭包的特点:
1. 必须有一个内嵌函数
2. 内嵌函数必须引用外部函数中的变量
3. 外部函数的返回值必须是内嵌函数法2
# inner是内函数
def inner():
#内函数中想修改闭包变量
# 方法1 nonlocal关键字声明
nonlocal b
b+=1
# 方法二,把闭包变量修改成可变数据类型 比如列表
c[0] += 1
print(c[0])
print(b)
# 外函数的返回值是内函数的引用
return inner
if __name__ == '__main__':
demo = outer(5)
demo() # 6 11
闭包的特点:
- 必须有一个内嵌函数
- 内嵌函数必须引用外部函数中的变量
- 外部函数的返回值必须是内嵌函数
匿名函数有什么好处?请举一个例子说明其用法
>>> a = lambda x, y: x + y # 定义匿名函数并赋值给a
>>> a(2, 3) # a具有匿名函数的功能, 通过参数传值
5 # 输出结果
lambda的冒号前面表示的是参数,冒号后面的是表达式. 注意, lambda 可以接受任意多个参数, 但只能有一个表达式.
匿名函数的优点:
- 使用Python写一些脚本时,使用lambda可以省去定义函数的过程,让代码更加精简.
- 对于一些抽象的,不会被别的地方再重复使用的函数,有时候函数起个名字也是个难题,使用lambda不需要考虑命名的问题.
- 使用lambda在某些时候能使代码更容易理解.
匿名函数一般不单独使用,经常与一些内置函数一块使用.
能使用匿名函数的内置函数为:map,filter,max,min,sorted
闭包的特点:
- 必须有一个内嵌函数
- 内嵌函数必须引用外部函数中的变量
- 外部函数的返回值必须是内嵌函数
装饰器的概念是什么?如何使用?
装饰器本质上是一个Python函数或类,它可以让其他函数或类在不修改他内部代码的情况下,添加一些额外的功能。有助于让代码更加简短,更Pythonic。
常见的使用场景是用于计时或者日志功能,写法如下。
def use_logging(func):
def wrapper():
logger_function()
time_cost_function()
return func()
return wrapper
@use_logging
def foo():
print("i am foo")
偏函数partial的概念是什么?
通常函数在执行的时候需要输入所有的参数。但是有这样一种情况,在调用的时候,有些参数还是未知的,那么就需要使用偏函数。偏函数可以让函数用更少的关键字进行调用。
from functools import partial
def mod( n, m ):
return n % m
mod_by_100 = partial( mod, 100 )
print mod( 100, 7 ) # 2
print mod_by_100( 7 ) # 2
类专有方法:
__init__ : 构造函数,在生成对象时调用
__del__ : 析构函数,释放对象时使用
__repr__ : 打印,转换
__setitem__ : 按照索引|赋值
__getitem__ : 按照索弓|获取值
__len__ : 获得长度
__cmp__ : 比较运算
__call__ : 函数调用
__add__ : 加运算
__sub__ : 减运算
__mul__ : 乘运算
__truediv__ : 除运算
__mod__ : 求余运算
__pow__ : 乘方
is和==的区别。
- is:判断两个对象的地址是否相等
- ==:判断两个变量/对象值是否相等
内存管理
- 小整数[-5,257]共用对象,常驻内存
- 单个字符共用对象,常驻内存
其他如单词、字符串、可变对象等在创建时申请内存,销毁时采用垃圾回收机制。
垃圾回收机制
在Python中,主要通过”引用-计数“进行垃圾回收;通过 “标记-清除” 解决容器对象可能产生的循环引用问题;通过 “分代-回收” 以空间换时间的方法提高垃圾回收效率。
-
引用计数
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少。引用计数为0时,该对象生命就结束了。
优点:简单、实时性
缺点:维护引用计数消耗资源、循环引用 -
标记清除
基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把不可达的对象释放。 -
分代回收
将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长。
举例: 当某些内存块M经过了3次垃圾收集的清洗之后还存活时,我们就将内存块M划到一个集合A中去,而新分配的内存都划分到集合B中去。当垃圾收集开始工作时,大多数情况都只对集合B进行垃圾回收,而对集合A进行垃圾回收要隔相当长一段时间后才进行,这就使得垃圾收集机制需要处理的内存少了,效率自然就提高了。在这个过程中,集合B中的某些内存块由于存活时间长而会被转移到集合A中,当然,集合A中实际上也存在一些垃圾,这些垃圾的回收会因为这种分代的机制而被延迟。
set、dict、list、tuple原理
- set的底层原理(无序):哈希。通过两个函数__hash__和__eq__结合实现的。
- 当两个变量的哈希值不同时,就认为这两个变量是不同的。
- 当两个变量哈希值时一样时,调用__eq__方法,当返回值为True时认为这两个变量是同一个,应该去除一个。返回False时不去重
- dict的原理(插入顺序):哈希。
- dict的key和set的值都是必须可哈希的:(不可变对象,str,tuple等)
- dict用空间来换时间,查找快
- dict的存储顺序和元素的添加顺序有关
- 添加的数据有可能改变已有的数据顺序
Python中的dict和set都是通过散列表来实现的。下面来看与dict相关的几个比较重要的问题:
- set和dict中的数据是无序存放的
- 操作的时间复杂度,插入、查找和删除都可以在O(1)的时间复杂度
- 键的限制,只有可哈希的对象才能作为字典的键和set的值。可hash的对象即python中的不可变对象和自定义的对象。可变对象(列表、字典、集合)是不能作为字典的键和st的值的。
- 与list相比:list的查找和删除的时间复杂度是O(n),添加的时间复杂度是O(1)。但是dict使用hashtable内存的开销更大。为了保证较少的冲突,hashtable的装载因子,一般要小于0.75,在python中当装载因子达到2/3的时候就会自动进行扩容。
- list的原理:list是可变长度数组。python中的列表是由对其他对象的引用组成的连续数组。指向这个数组的指针及其长度被保存在一个列表头结构中。这意味着,每次添加或删除一个元素时,由引用组成的数组需要改变大小(重新分配)。幸运的是,python在创建这些数组时采用了 指数分配,所以并不是每次操作都需要改变数组的大小。但是也因为这个原因添加或取出元素的平均复杂度较低。
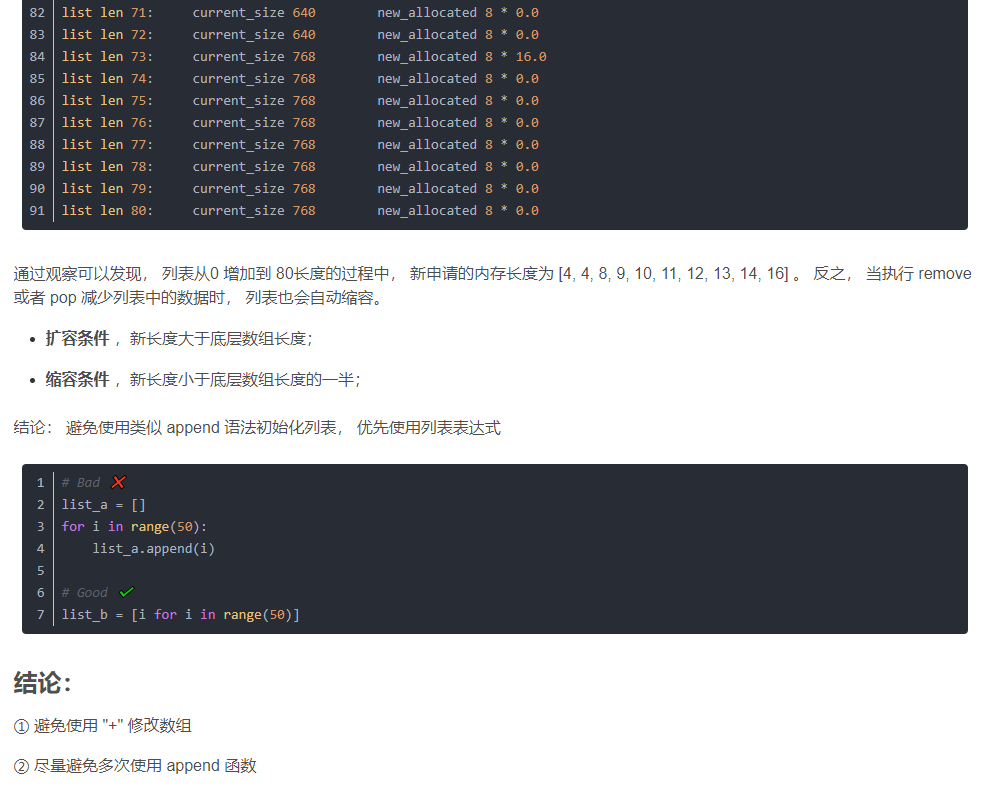
python str中 find() 和 index() 的区别。
- 如果要查找的子串在str中,二者一样,返回第一次出现的下标
- 如果不在,find()返回-1,而index()报错
实例方法、静态方法、类方法的区别
总结:
-
实例方法:可以获取类属性、构造函数定义的变量,属于 method 类型。只能通过实例化调用。
-
静态方法:不能获取类属性、构造函数定义的变量,属于 function 类型。两种调用方式:类.方法名 ,实例化调用。
-
类方法 :可以获取类属性,不能获取构造函数定义的变量,属于 method 类型。两种调用方式:类.方法名 ,实例化调用。
-
实例方法:
- 通常情况下,在类中定义的普通方法即为类的实例方法,实例方法第一个参数是 self(self 是一种约定习惯) 代表实例本身,当调用某个实例方法时,该实例的对象引用作为第一个参数 self 隐式的传递到方法中。
class test:
math = 100
# 类构造方法也是实例方法
def __init__(self):
self.Chinese = 90
self.English = 80
# 实例方法
def say(self):
print('我的语文成绩是:{}'.format(self.Chinese))
# 实例化
A = test()
# 调用实例方法
A.say()
- 静态方法:
- 类的静态方法和我们自定义的函数基本没什么区别,没有 self,且不能访问类属性,实际项目中很少用到,因为可以使用普通函数替代。
- 静态方法需要使用 @staticmethod 装饰器声明。
- 有两种调用方式:类.方法名 和 实例化调用 。
class test:
math = 100
# 类构造方法也是实例方法
def __init__(self):
self.Chinese = 90
self.English = 80
# 静态方法
@staticmethod
def say():
print('我的语文成绩是:90')
- 类方法
- 类的类方法也必须包含一个参数,通常约定为 cls ,cls 代表 类本身(注意不是实例本身,是有区别的),python 会自动将类本身传给 cls,所有这个参数也不需要我们传值。
- 类方法必须需要使用 @classmethod 装饰器申明。
- 两种方式调用:类.方法名 和 实例调用。
class test:
math = 100
# 类构造方法也是实例方法
def __init__(self):
self.Chinese = 90
self.English = 80
@classmethod
def say(cls):
print('我的数学成绩是:{}'.format(cls.math))
# 类.方法名test.say()
print(test.say)
__new__和__init__的区别
- __new__是一个静态方法,而__init__是一个实例方法.
- __new__方法会返回一个创建的实例,而__init__什么都不返回.
- 只有在__new__返回一个cls的实例时后面的__init__才能被调用.
- 当创建一个新实例时调用__new__,初始化一个实例时用__init__
GIL线程全局锁
线程全局锁(Global Interpreter Lock),Python为了保证线程安全而采取的独立线程运行的限制,可以防止多个线程同时执行。这意味着程序编写有十个并发线程,那么其中只有一个可以被执行,而其他九个则需要等待时间片轮转。
对于io密集型任务,python的多线程起到作用,但对于cpu密集型任务,python的多线程几乎占不到任何优势,还有可能因为争夺资源而变慢。
解决办法:
-
在以IO操作为主的IO密集型应用中,多线程和多进程的性能区别并不大,原因在于即使在Python中有GIL锁的存在,由于线程中的IO操作会使得线程立即释放GIL,切换到其他非IO线程继续操作,提高程序执行效率。相比进程操作,线程操作更加轻量级,线程之间的通讯复杂度更低,建议使用多线程。
-
如果cpu应用,尽量使用多进程或者协程来代替多线程。
Python 为什么存在GIL
Python 使用GIL 而非管理锁出于以下原因:
- 在单线程任务中更快;
- 在多线程任务中,对于 I/O 密集型程序运行更快
- 在多线程任务中,对于用 C 语言包来实现 CPU 密集型任务的程序运行更快;
- 在写 C 拓展的时候更加容易,因为除非你在扩展中允许,否则Python解释器不会切换线程;
- 在打包C库时更加容易。我们不用担心线程安全性。因为如果该库不是线程安全的,则只需在调用GIL时将其锁定即可。
Python有GIL为什么还需要线程同步?
GIL同时只允许一个线程执行,并且不断切换,即保存上下文之后,进入另一个线程的上下文执行。
对于数据而言,它本身还是被多个处理器读取,写入,所以要保证共享数据的正确性和可靠性,需要线程同步机制去实现。
协程
简单点说协程是进程和线程的升级版,进程和线程都面临着内核态和用户态的切换问题而耗费许多切换时间,而协程就是用户自己控制切换的时机,,再需要陷入系统的内核态。
read, readline和readlines
read 读取整个文件,返回字符串
readline 读取下一行,使用生成器方法,返回字符串
readlines 读取整个文件到一个迭代器以供我们遍历,返回列表
生成器与迭代器的概念分别是什么?
迭代器
迭代是Python最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器.
生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
正则的 match 和 search 的区别
re.match() 只从待匹配的字符串或文本的开头开始匹配,如果开头不正确,则无法匹配。
而re.search() 会扫描整个字符串,返回第一个成功的匹配的位置。
举例说明什么情况下会出现KeyError、TypeError、ValueError。
举一个简单的例子,变量a是一个字典,执行int(a[‘x’])这个操作就有可能引发上述三种类型的异常。
- 如果字典中没有键x,会引发KeyError;
- 如果键x对应的值不是str、float、int、bool以及bytes-like类型,在调用int函数构造int类型的对象时,会引发TypeError;
- 如果a[x]是一个字符串或者字节串,而对应的内容又无法处理成int时,将引发ValueError。
如何读取大文件,例如内存只有4G,如何读取一个大小为8G的文件?
很显然4G内存要一次性的加载大小为8G的文件是不现实的,遇到这种情况必须要考虑多次读取和分批次处理。
- 在Python中读取文件可以先通过open函数获取文件对象,在读取文件时,可以通过read方法的size参数指定读取的大小。
- 也可以通过seek方法的offset参数指定读取的位置,这样就可以控制单次读取数据的字节数和总字节数。
- 除此之外,可以使用内置函数iter将文件对象处理成迭代器对象,每次只读取少量的数据进行处理。
单下划线和双下划线的区别
单下划线:用来指定变量私有,只有类对象和子类对象能够访问,外部访问需要接口, 不能用import 导入。
双下划线:私有成员,只有类对象自己能够访问,子类对象也无法访问。
什么是Python自省?
Python 自省是一种自我检查的行为,自省是在运行时确定对象的类型或属性的能力。
Python 中的所有内容都是一个对象。Python 中的每个对象都可以具有属性和方法,通过自省,可以动态的检查 Python 对象。
变量的查找顺序
python解释器在解引用一个变量时遵循所谓‘legb’的顺序。即
- local,本地
- enclosing,闭包
- global,全局
- built-in,内建函数















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









