







iceberg:
https://iceberg.apache.org/
iceberg表,是一种面向大型分析数据集的开放表格式,旨在提供可扩展、高效、安全的数据存储和查询解决方案。它支持多种存储后端上的数据操作,并提供 ACID 事务、多版本控制和模式演化等特性,使数据管理和查询更加灵活便捷。Iceberg 可以屏蔽底层数据存储格式上的差异,向上提供统一的操作 API,使得不同的引擎可以通过其提供的 API 接入。
表格式(Table Format)可以理解为元数据以及数据文件的一种组织方式,处于计算框架(Flink,Spark…)之下,数据文件(orc, parquet)之上。这一点与Hive有点类似,hive也是基于HDFS存储、MR/SPARK计算引擎,将数据组织成一种表格式,提供Hive Sql对数据进行处理。如果我们的文件格式选择的是parquet,那么文件是以“.parquet”结尾,例如:
00000-0-root_20211212192602_8036d31b-9598-4e30-8e67-ce6c39f034da-job_1639237002345_0025-00001.parquet 就是一个数据文件。
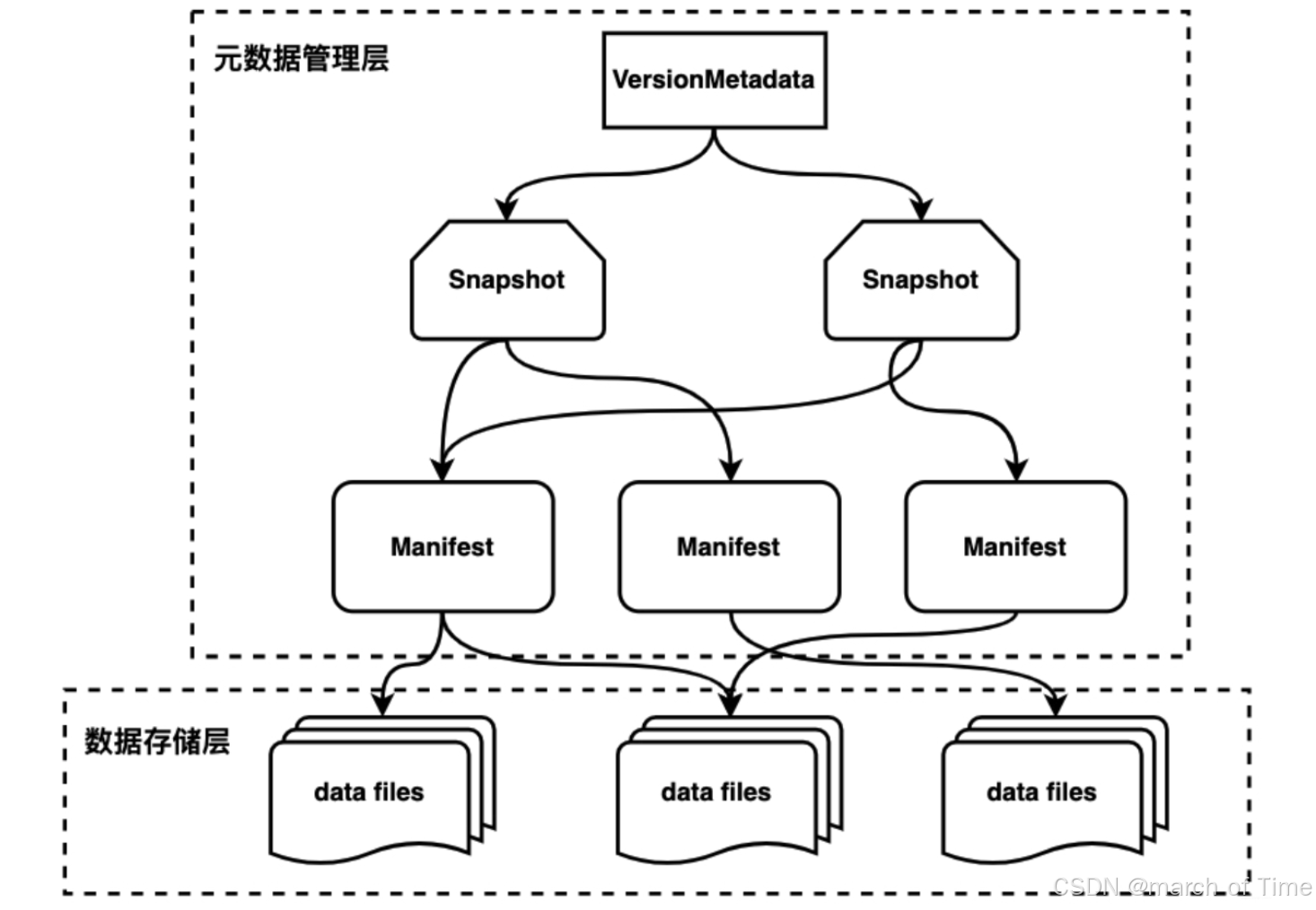
Iceberg 设计为以快照(Snapshot)的形式来管理表的各个历史版本数据。每个快照中会列出表在某个时刻的所有数据文件列表。Data 文件存储在不同的 Manifest 文件中,Manifest 文件存储在一个 Manifest List 文件中,Manifest 文件可以在不同的 Manifest List 文件间共享,一个 Manifest List 文件代表一个快照。
Manifest list 文件是元数据文件,其中存储的是 Manifest 文件的列表,每个 Manifest 文件占据一行。
Manifest 文件是元数据文件,其中列出了组成某个快照的数据文件列表。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(例如每列的最大最小值、空值数等)、文件的大小以及文件中数据的行数等信息。
Data 文件是 Iceberg 表真实存储数据的文件,一般是在表的数据存储目录的 data 目录下。
Apache Iceberg表的特点主要包括:
开放的数据湖表格式:Iceberg是一种开放的数据湖表格式,可以在HDFS或对象存储上构建数据湖存储服务,与多种计算引擎如Spark、Flink、Hive和Presto等兼容 。
1.核心能力:Iceberg设计初衷是解决Hive数仓上云的问题,提供基于HDFS或对象存储的轻量级数据湖存储服务,支持ACID语义、行级数据变更、历史版本回溯、高效数据过滤、Schema变更、分区布局变更以及隐式分区 。
2.文件级别的元数据管理:Iceberg通过快照进行多版本控制,每个快照对应一组清单,清单再对应具体数据文件 。
3.数据文件不可变性:Iceberg数据文件一旦创建就不能被修改,而是通过追加新数据文件来增加新数据 。
4.表快照:Iceberg表快照是表在特定时间点的版本,每次修改都会生成新的快照,帮助实现版本控制和数据管理 。
5.清单列表:清单列表是数据文件的元数据信息列表,对数据查询、管理和优化等操作至关重要 。
6.Catalog管理:Catalog是管理表和数据的入口,负责存储表的元数据信息,并允许通过编程方式或CLI进行操作 。
7.ACID和MVCC:Iceberg提供了ACID语义和多版本并发控制,确保数据的一致性和可靠性 。
8.Schema和Partition Evolution:Iceberg支持灵活的表schema变更和分区方式变更,允许对表进行增加列、删除列、更新列等操作 。
hive
Hive就是一种数据仓库,可以将结构化的数据文件映射为数据库表,并提供简单的sql查询功能,可以将sql语句转化为mapreduce任务执行,底层由HDFS来提供数据的存储,说白了hive可以理解为一个将SQL转换为MapReduce的任务的工具,甚至更进一步可以说hive就是一个MapReduce的客户端。Hive本身并不提供数据的存储功能,它可以使已经存储的数据结构化。hive将数据映射成数据库和一张张表,库和表的元数据信息可以存在metastore上(hive metastore一般是关系型数据库)。 通过 SQL 轻松访问数据的工具,从而支持提取/转换/加载 (ETL)、报告和数据分析等数据仓库任务。一种将结构强加于各种数据格式的机制访问直接存储在 Apache HDFS或其他数据存储系统(例如 Apache HBase)中的文件。
hive常用的存储格式有五种,textfile、sequencefile、rcfile、orc、parquet。
Hive表的一些关键特点:
结构化数据存储:
Hive表用于存储结构化数据,数据以行和列的形式组织,类似于传统关系型数据库的表。
元数据存储:
Hive表的元数据(如表名、列名、数据类型、分区信息等)存储在Hive Metastore中,这是一个中心化的元数据存储库。
数据存储位置:
Hive表的数据实际存储在HDFS上,Hive表与底层文件系统的位置相关联。
分区和分桶:
Hive表支持分区(Partition)和分桶(Bucket),这有助于优化查询性能和数据管理。
数据类型:
Hive表支持多种数据类型,包括数值型、字符串型、日期型、复杂类型(如数组、结构、映射等)。
表属性:
Hive表可以设置各种属性,如存储格式(如TextFile、SequenceFile、ORC、Parquet等)、压缩选项等。
外部表和内部表:
Hive支持外部表(External Table)和内部表(Managed Table),外部表的存储不受Hive管理,而内部表的存储由Hive管理。
索引:
Hive表可以创建索引,以提高查询效率。
存储结构:
Hive表可以有不同的存储结构,如行存储或列存储。
查询语言:
Hive提供了自己的查询语言HiveQL,它是SQL的一种方言,用于查询和管理Hive表中的数据。
数据操作:
用户可以使用HiveQL执行常见的数据操作,如SELECT、INSERT、UPDATE、DELETE等。
对比
Iceberg提供了事务处理能力,支持ACID语义,确保数据的一致性和完整性。Hive在早期版本中对事务性的支持不够完善,尽管在Hive 3中引入了对ACID的支持,但Iceberg在设计上更倾向于事务性操作 。
大框架上,Iceberg的文件组织形式与Hive类似,都是HDFS的目录,在warehouse下以/db/table的形式组建结构。Iceberg 是一种适用于 HDFS 或者对象存储的表格式,把底层的 Parquet、ORC 等数据文件组织成一张表,向上层的 Spark,Flink 计算引擎提供表层面的语义,作用类似于 Hive Meta Store,但是和 Hive Meta Store 相比:
Iceberg 能避免 File Listing 的开销;
也能够提供更丰富的语义,包括 Schema 演进、快照、行级更新、 ACID 增量读等。
Iceberg是纯文件的,元数据也存储在HDFS上,并做到了文件级别的元数据组织。
在/db/table的目录结构下,有两个目录:metadata和data,用于存储元数据和数据。
data下存储数据,比较单一,只有一类文件,默认以Parquet形式存储。
metadata下存储元数据,分三层:metadata file、manifest list、manifest file。元数据目前有两个版本:V1Metadata、V2Metadata,创建table时带参数设置:
CREATE TABLE tl(id BIGINT) WITH ('format-version'='2')















 3079
3079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









