







文章目录
【关于作者】
关于作者,目前在蚂蚁金服搬砖任职,在支付宝营销投放领域工作了多年,目前在专注于内存数据库相关的应用学习,如果你有任何技术交流或大厂内推及面试咨询,都可以从我的个人博客(https://0522-isniceday.top/)联系我
1.存储引擎:从LSM到TSM
转载于:http://hbasefly.com/2017/12/08/influxdb-1/
InfluxDB 采用自研的TSM (Time-Structured Merge Tree) 作为存储引擎, 其核心思想是通过牺牲掉一些功能来对性能达到极致优化,其官方文档上有项目存储引擎经历了从LevelDB到BlotDB,再到选择自研TSM的过程,整个选择转变的思考
时序数据库的需求
- 数据量大
- 高写入吞吐量
- 高读取吞吐量
- 大型删除(数据过期)
- 主要是插入/追加工作负载,很少更新,插入场景远大于修改场景
InfluxDB为什么不采取基于**LSM (日志结构合并树)**存储引擎的levelDB,这里我们先简单讲解下什么是LSM:
LSM (日志结构合并树)为 LevelDB的引擎原理,
- levelDB 不支持热备份。 对数据库进行安全备份必须关闭后才能复制。LevelDB的RocksDB和HyperLevelDB变体可以解决此问题。
- 时序数据库需要提供一种自动管理数据保存的方式。 即删除过期数据, 而在levelDB 中,删除的代价过高。(通过添加墓碑的方式, 段结构合并的时候才会真正物理性的删除)。
2.InfluxDB 的解决方案 - TSM
分区:按照不同的时间范围划分为不同的分区(shard),因为时序数据写入都是按照时间线性产生的,所以分区的产生也是按照时间线性增长的,写入通常是在最新的分区,而不会散列到多个分区。
分区的优点主要是数据回收的物理删除非常简单,直接将整个分区删除即可
LSM (日志结构合并树)到TSM (Time-Structured Merge Tree) 的原因:
- LevelDB的删除代价过高
- 文件句柄打满:如果influxdb每个shard都是一个独立的数据库实例,底层都是一套LevelDB存储引擎,这是可能会产生LevelDB底层采用level compaction策略,每个存储引擎会打开比较多的文件,随着shard的增多,最终进程打开的文件句柄会很快触及到上限
- BoltDB替换LevelDB:为了解决文件句柄打开过多的问题,BoltDB底层数据结构是mmap B+树。 但由于B+ 树会产生大量的随机写。 所以写入性能较差
之后Influxdb 最终决定仿照LSM 的思想自研TSM ,主要改进点是基于时序数据库的特性作出一些优化,包含Cache、WAL以及Data File等各个组件,也会有flush、compaction等这类数据操作。
3.InfluxDB的系统架构
3.1.InfluxDB的数据模型
一些重要概念:
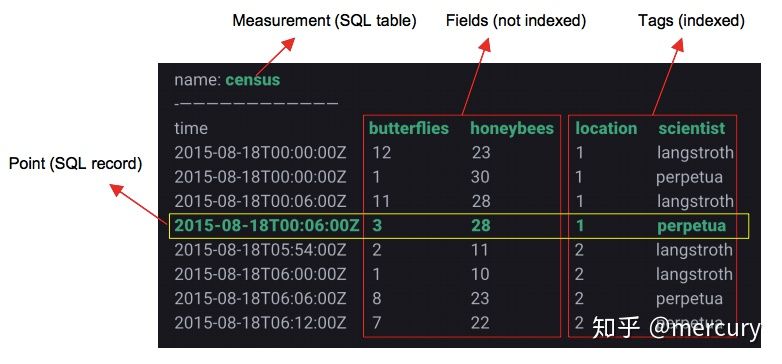
-
Measurement : 类似于mysql 的表名。 这和其他很多时序数据库有些不同,其他时序数据库中Measurement可能与Metric等同,类似于下文讲到的Field,这点需要注意
-
tag key(维度列): 类似于mysql 加了索引的列名
-
上图中location和scientist分别是表中的两个Tag Key,其中location对应的维度值Tag Values为{1, 2},scientist对应的维度值Tag Values为{langstroth, perpetual},两者的组合TagSet有四种
location = 1 , scientist = langstroth location = 1 , scientist = perpetual location = 2 , scientist = langstroth location = 2 , scientist = perpetual -
InfluxDB中,表中Tags组合会被作为记录的主键,因此主键并不唯一。比如上表中第一行和第三行记录的主键都为’location=1,scientist=langstroth’。所有时序查询最终都会基于主键查询之后再经过时间戳过滤完成,可以理解为先定位到时间轴
-
-
Field key : 类似于mysql 没加索引的列名
-
Point:类似SQL中一行记录,而并不是一个点。
3.2.InfluxDB 核心概念 – Series
时序数据的时间线就是一个数据源采集的一个指标随着时间的流逝而源源不断地吐出数据,这样形成的一条数据线称之为时间线
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dGiGBQXp-1680796345573)(C:/Users/98347/Desktop/%E5%AD%A6%E4%B9%A0%E5%8A%A0%E6%B2%B9%E5%95%8A/redis/%E5%9B%BE%E7%89%87%E8%B5%84%E6%BA%90/image-20210526200029983.png)]
上图中有两个数据源(series),每个数据源会采集两种指标(field,别的时序数据库相似的叫metric)butterflier和honeybees,Series由Measurement和Tags组合而成
3.3.InfluxDB的系统架构
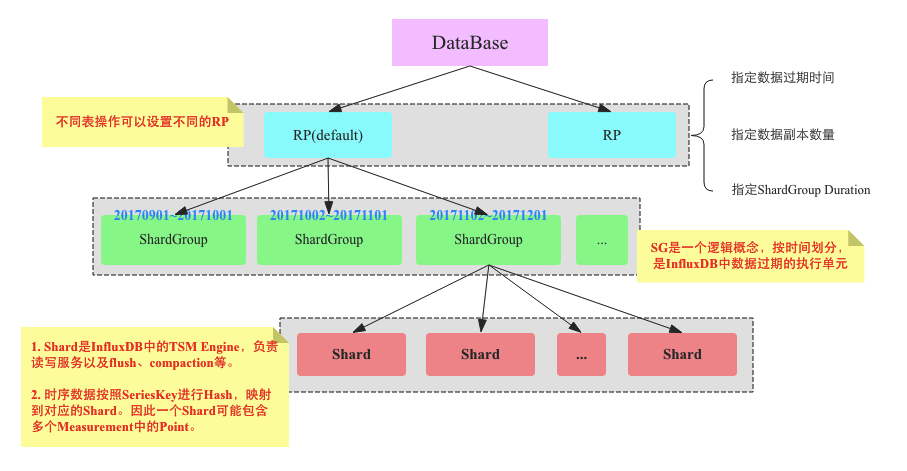
-
DataBase: 用户可以通过 create database xxx 来创建一个database。
-
Retention Policy(RP):
数据保留策略,作用主要包括:指定数据的过期时间、指定数据的副本数量、指定ShardGroup Duration。
CREATE RETENTION POLICY ON <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [SHARD DURATION <duration> ] [DEFAULT] CREATE RETENTION POLICY "a_year" ON "food_data" DURATION 52w REPLICATION 1 SHARD DURATION 1h 上述语句可以创建一个保存周期为52周的RP。REPLICATION 1 表示副本数量为1。 ”SHARD DURATION”指定每个Shard Group对应多长时间。 一个数据库可以用多个RP , 不同的表可以设置不同的RP。InfluxDB中Retention Policy有这么几个性质和用法:
- RP是库级别而不是表级别的熟悉
- 数据库有多个RP,但是只能有一个RP
- 不同表写入数据时可以执行RP,不指定就使用默认RP
-
Shard Group:是InfluxDB中的一个重要的逻辑概念,Shard Group中会包含多个Shard,每个Shard Group只存储指定时间段的数据,不同Shard Group对应的时间段不会重合(比如2017年9月份的数据落在Shard Group0上,2017年10月份的数据落在Shard Group1上,数据落在哪个Shard Group是按照数据的timastamp),Shard Group对应的时间段长度通过Retention Policy中字段”SHARD DURATION”指定的,不指定则InfluxDB会有对应的策略,策略如下:

为什么要将数据按照过期时间划分为一个一个Shard Group,主要有两个原因:
- 过期数据的删除很简单:删除时间的粒度变为了Shard Group,例如Shard Group Duration为1h,那么查询就可以将1小时之前的Shard Group全部删除
- 加快数据按时间维度查找的效率:实现了将数据按照时间分区的特性,加快了将时间作为筛选条件的查询速度,比如查询最近一小时或者最近一天
- 一定程度上缓解数据写入热点问题:TSM减少了数据的随机写入磁盘
-
Shard:Shard Group实现了数据分区,但是Shard Group只是一个逻辑概念,在它里面包含了大量Shard(单机版本只有1个),Shard才是InfluxDB真正存储数据以及提供读写服务的概念,类似于HBase中Region,Kudu中Tablet的概念
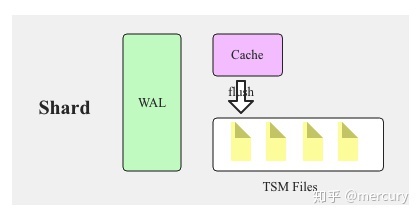
Shard 就是上面章节所介绍的TSM 引擎, 负责把数据写入文件,写入的过程类似LSM,数据线写入Cache,等cache达到一定大小,就异步flush到TSM文件(MySQL的插入缓冲也采取了类似测了,主要是通过顺序IO比随机IO更快)。WAL(Write Ahead Log)用来防止数据丢失
-
Shard是InfluxDB的存储引擎实现,具体称之为TSM(Time Sort Merge Tree) Engine,负责数据的编码存储、读写服务等。TSM类似于LSM,因此Shard和HBase Region一样包含Cache、WAL以及Data File等各个组件,也会有flush、compaction等这类数据操作
-
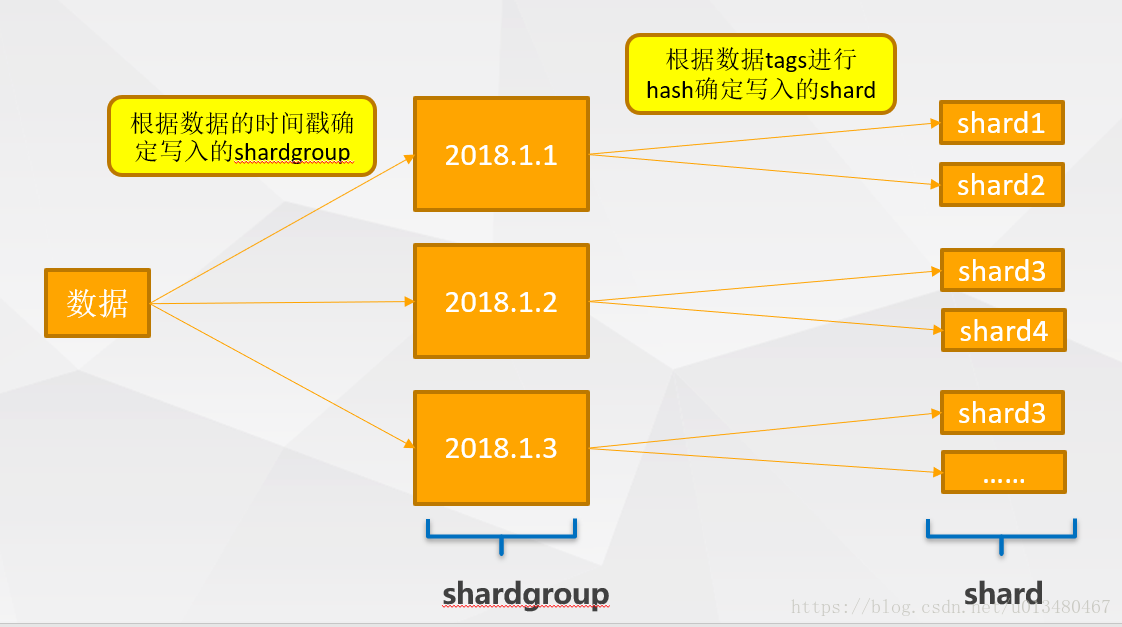
InfluxDB采用了Hash分区的方法将落到同一个Shard Group中的数据再次进行分区,注意这里采取的是Hash(Series)的方式将时序数据映射到不同的Shard,因此同一Series的数据会落到同一个Shard,但是一个Shard会包含不同Measurment的数据,不像HBase中一个Region的数据肯定都属于同一张表。
3.4.InfluxDB Sharding策略
通常分布式数据库包含两种Sharding策略:Range Sharding(基于主键范围分片,HBase和TiDB都采取了这种)和 Hash Sharding(Hash分片,es和redis都采取了这种),前者基于主键的范围扫描比较高效,后者离散大规模写入以及随机读取比较友好
InfluxDB采取的Sharding策略:两层Sharding,上层使用Range Sharding(Shard Group),下层使用Hash Sharding(Shard),对于时序数据库而言,基于时间的Range Sharding肯定是最高效的(因为根据时间所筛选的数据都在一个Sharding),但是这样会导致写入热点的问题,最新写入的数据都落在一个Sharding上,其余Sharding不会接受写请求(不符合负载均衡),因此下层采取了Hash Sharding,基于Key的Hash分区可以通过散列很好的解决热点写入的问题,但还是会有如下的问题:
- Key Range Scan性能差(根据Key的范围查询性能差,可能需要查询多个不同的Sharding):时序数据库基本上所有查询都是基于Series(数据源)来完成的,因此只要Hash分区是按照Series进行Hash就可以将相同Series的时序数据放在一起,这样Range Scan性能就可以得到保证
- Hash分区的个数必须固定,个数改变就代表需要再散列来将数据重分布
-
















 3470
3470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











