







【关于作者】
关于作者,目前在蚂蚁金服搬砖任职,在支付宝营销投放领域工作了多年,目前在专注于内存数据库相关的应用学习,如果你有任何技术交流或大厂内推及面试咨询,都可以从我的个人博客(https://0522-isniceday.top/)联系我
时序数据有如下几个要点:
1.插入比较频繁,更新比较少
2.具有按照时间顺序排序的要求
3.需要支持聚合,或查询某个时间段
1.基于Hash和Sorted Set(zset)保存时间序列数据
1.1.解决方案
利用hash的二级key作为时间,二级value存储数据可以解决插入频繁,查找快速的问题,但是没有按照时间排序,以及支持聚合,这个时候就可以引入zset解决该问题,但是此时会出现同时插入hash和zset的原子性问题
1.2.难点
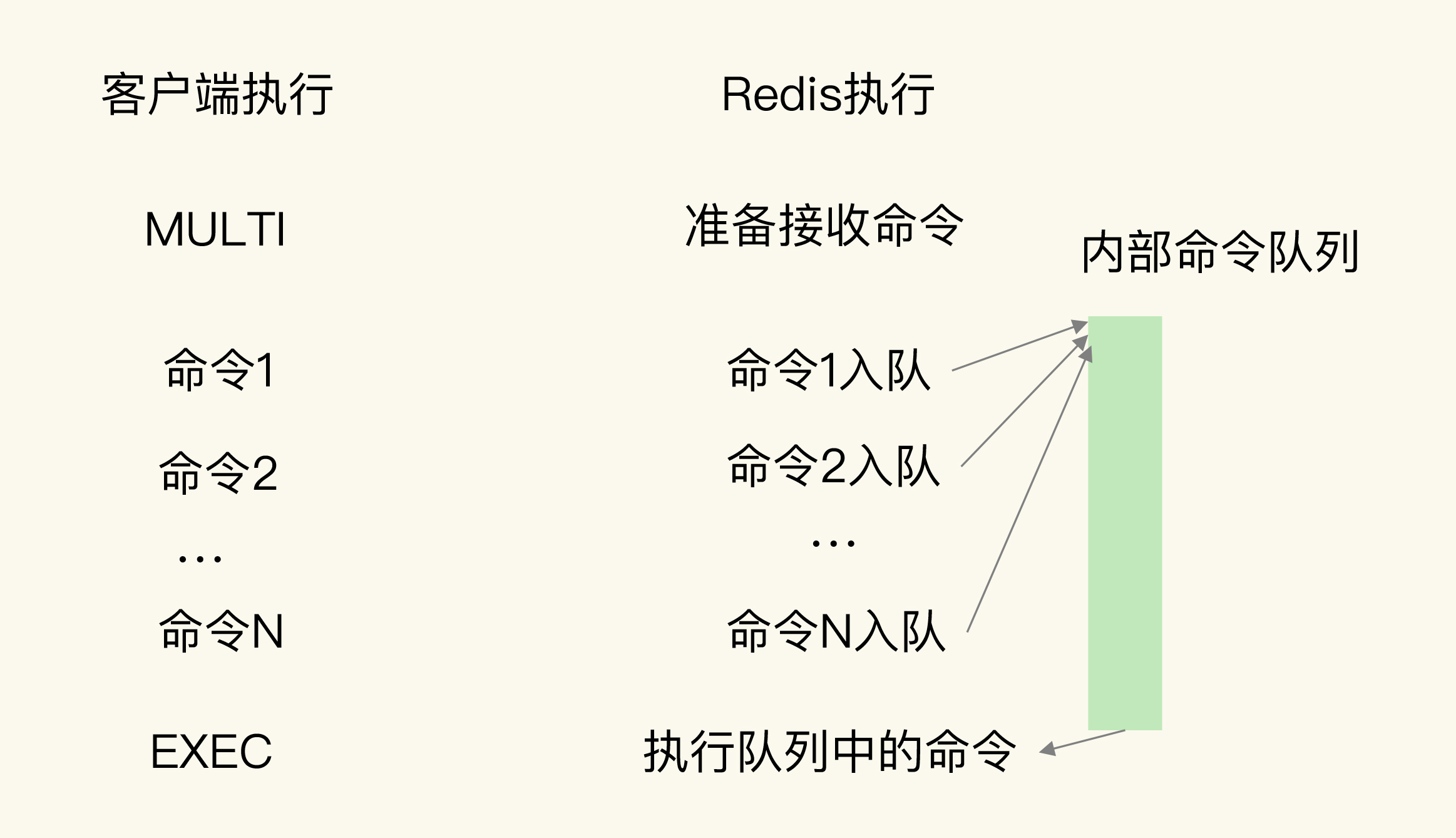
(1)原子性问题解决:
MULTI和EXEC命令的使用:
MULTI:表示一系列原子性操作的开始。接收到该命令代表接下来的指令都会放到内部队列中,后续一起执行保证原子性
EXEC:代表原子性操作的结束
(2)如何解决大数据量下的聚合问题
虽然zset结构可以解决范围查询,但是数据量过大则会导致数据传输过程中导致操作系统竞争资源,会变得很缓慢。
此时可以引入RedisTimeSeries来保存时序数据
2.基于RedisTimeSeries模块保存时间序列数据
edisTimeSeries是Redis的一个扩展模块。它专门面向时间序列数据提供了数据类型和访问接口,并且支持在Redis实例上直接对数据进行按时间范围的聚合计算。
因为RedisTimeSeries不属于Redis的内建功能模块,在使用时,我们需要先把它的源码单独编译成动态链接库redistimeseries.so,再使用loadmodule命令进行加载,如下所示:
loadmodule redistimeseries.so
当用于时间序列数据存取时,RedisTimeSeries的操作主要有5个:
- 用TS.CREATE命令创建时间序列数据集合;
- 用TS.ADD命令插入数据;
- 用TS.GET命令读取最新数据;
- 用TS.MGET命令按标签过滤查询数据集合;
- 用TS.RANGE支持聚合计算的范围查询。
我认为真正的时序数据库的场景可能不会真正的使用redis,而是会使用influxdb、普罗米修斯等替代
















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











