







【关于作者】
关于作者,目前在蚂蚁金服搬砖任职,在支付宝营销投放领域工作了多年,目前在专注于内存数据库相关的应用学习,如果你有任何技术交流或大厂内推及面试咨询,都可以从我的个人博客(https://0522-isniceday.top/)联系我
时序数据库的基本目标:
- 高吞吐的写入
- 数据分级存储
- TTL
- 数据高压缩率
- 多维度的查询能力
- 高效聚合能力
InfluxDB针对上述的实现如下:
- 高吞吐的写入:TSM存储引擎保证了高效率的写入(数据(二级)组织+Key有序,追加写的顺序写入)
- 数据分级存储:TSM数据组织,Range+Hash(保证了范围查找时候的性能以及也避免了写入热点的问题)
- TTL:基于RP(Retention Policy)下的Shard Group组织数据,使得删除及判断过期变得简单
- 数据高压缩率:TSM文件基于列式存储实现的高压缩率(Key)
- 多维度的查询能力:基于InfluxDB系统的倒排索引实现多维度查询
- 高效聚合能力:
InfluxDB中TSM存储引擎最核心的模块:
- TSM针对时序数据,在内存以及TSM文件结构上做了针对性的优化,优雅的实现了时序数据的高效写入以及高效率压缩,同时文件级别的B+树可以有效提高SeriesKey查询时序数据的性能
- InfluxDB还实现了内存以及文件级别的倒排索引,有效实现了根据fieldKey查询对应SeriesKey的功能,查到SeriesKey后再根据SeriesKey+fieldKey+时间范围查找数据
1.TimeSeries Index
如何根据measurment以及部分维度组合查找所有满足条件的SeriesKey:InfluxDB给出了倒排索引的实现。称之为TimeSeries Index,意为TimeSeries的索引,简称TSI。。InfluxDB TSI在1.3版本之前仅支持Memory-Based Index实现,1.3之后又实现了Disk-Based Index实现。
其实主要目的是为了帮助更快的匹配到所需要SeriesKey,定位之后的查询逻辑还是和指定SeriesKey去查询一样
查询场景:
上文笔者提到SeriesKey等于measurement+tags(datasources),其中measurement表示一张时序数据表,tags(多组维度值)唯一确定了数据源。用户的查询通常有以下两种查询场景,以广告时序数据平台来说:
-
查看最近一小时某一个广告(数据源)总的点击量,典型的根据SereisKey、fieldKey(点击量)和时间范围查找时序数据,再做聚合(sum)。
-
统计最近一天网易考拉(指定广告商)发布在网易云音乐(指定广告平台)的所有广告总的点击量。这种统计查询并没有给出具体的广告(SeriesKey),仅指定了两个广告维度(广告商和广告平台)以及查询指标 – 点击量。这种查询就首先需要使用倒排索引根据measurement以及部分维度组合(广告商=网易考拉,广告平台=网易云音乐)找到所有对应的广告源,假如网易考拉在网易云音乐上发布了100个广告,就需要查找到这100个广告点击量对应的SeriesKey,再分别针对所有SeriesKey在最近一天这个时间范围查找点击量数据,最后做sum聚合。
2.Memory-Based Index
该方案将所有TimeSeries索引加载到内存提供服务,主要数据结构如下:

转化为Java代码如下:
Map<SeriesId,SeriesKey> seriesByID;
Map<tagkey, map<tagvalue, List<SeriesId>>> seriesByTagKeyValue
//其中seriesByTagKeyValue是一个双重Map:其中tagKey为tag字段,tag字段会有很多值,所以内层map<tagvalue,List<SeriesID>>代表每个值所对应的具体series(或者说seriesID)
//采取Id而不直接用字符串key标识的主要目的是为了节省存储空间,不要造成不必要的冗余
针对上述场景2就能够根据广告商、渠道商的值去找到对应的List,然后再做并集拿到所以的SeriesKey进行查询
Memory-Based Index实现方案好处是可以根据tag查找SeriesKey会非常高效,但是缺点也非常明显:
- 受限于内存大小,无法支持大量的TimeSeries,尤其对于某些基数非常大的维度,会产生大量的SeriesKey,使用Memory-Based Index并不合适(所以Series过多不仅会导致查询变慢,也会占用大量内存,当然插入的数据也会占用很多的内存)
- 一旦InfluxDB进程宕掉,需要扫描解析所有TSM文件并在内存中全量构建TSI结构,恢复时间会很长
3.Disk-Based Index
Disk-Based Index方案会将索引持久化到磁盘,在使用时再加载到内存

InfluxDB中倒排索引和时序数据使用了相同的存储机制,LSM引擎。因此倒排索引也是先写入内存及WAL,内存中达到一定阈值再落盘,将内存中的索引写入文件。磁盘上的文件数超过一定阈值也会执行Compaction操作进行合并。实际实现中,point的写入会抽出measurment、Tags拼成SeriesKey,在系统中查看该SeriesKey是否存在,存在则忽略,不存在会写入内存的相应结构。
3.1.TSI文件
文件格式如下:
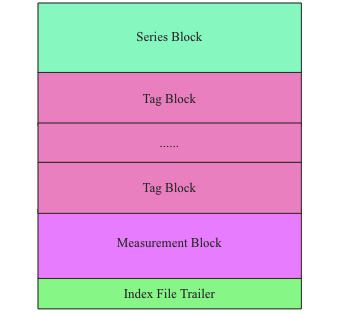
- Index File Trailer:主要记录Measurement Block、Tag Block以及Series Block在TSI中的偏移量以及数据大小
- Measurement Block:存储数据库中的表信息
- Tag Block:实际上是seriesByTagKeyValue这个双重map – map<tagkey, map<tagvalue, List>>在文件中的实际存储
- Series Block:存储了库中所有的SeriesKey
Measurement Block:
















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











