






引言
猫狗识别作为AI入门经典案例,以其适中的难度、丰富的数据资源、广泛的应用潜力,成 为学习图像分类和深度学习的优选课题。
本博客展示如何使用PyTorch搭建一个简单的猫狗识别系统。
1.准备工作
1.1安装python库
这个项目需要安装下面四个库
torch>=1.12.0
torchvision>=0.13.0
swanlab>=0.3.2
gradio安装命令:
pip install torch>=1.12.0 torchvision>=0.13.0 swanlab>=0.3.2 gradio1.2创建文件目录
在项目文件下创建下面文件
目录部分:checkpoint、datasets、flagged、swanlog
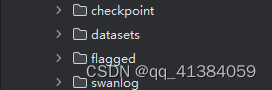
py文件部分:app.py、load_datasets.py、train.py

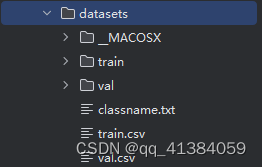
1.3获取数据集
百度网盘:链接: https://pan.baidu.com/s/1qYa13SxFM0AirzDyFMy0mQ 提取码: 1ybm
将数据集放入datasets目录中
2、训练部分
接下来开始写训练部分的内容
2.1 load_datasets.py(完整代码在2.2.7)
开始编辑load_datasets.py中的内容
2.1.1 导入必要的库
import csv
import os
from torchvision import transforms
from PIL import Image
from torch.utils.data import Dataset
这部分导入了实现数据加载器所需的库和模块。csv用于读取CSV文件;os用于操作文件路径;transforms和Image分别来自torchvision和PIL库,用于图像预处理;Dataset是PyTorch中定义数据集的基本类。
2.2.2 DatasetLoader类定义
class DatasetLoader(Dataset):定义了一个名为DatasetLoader的类,继承自PyTorch的Dataset类,这是创建自定义数据集的标准方式。
2.2.3 初始化方法 __init__
def __init__(self, csv_path):
self.csv_file = csv_path
with open(self.csv_file, 'r') as file:
self.data = list(csv.reader(file))
self.current_dir = os.path.dirname(os.path.abspath(__file__)) 作用:在类实例化时执行,读取指定的CSV文件路径,加载所有数据行到self.data列表中,并记录当前脚本的目录路径。
参数:csv_path是包含图像路径和标签的CSV文件路径。
2.2.4 图像预处理方法 preprocess_image
def preprocess_image(self, image_path):
full_path = os.path.join(self.current_dir, 'datasets', image_path)
image = Image.open(full_path)
image_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
return image_transform(image) 作用:接收单个图像路径,读取图像,对其进行一系列预处理操作,包括调整尺寸至256x256像素,转换为Tensor格式,并进行归一化处理。
重要性:确保所有输入图像具有统一的尺寸和格式,符合大多数深度学习模型的输入要求。
2.2.5索引访问方法 __getitem__
def __getitem__(self, index):
image_path, label = self.data[index]
image = self.preprocess_image(image_path)
return image, int(label)
作用:根据索引返回数据集中的一对(预处理后的图像,标签)。这是PyTorch在训练模型时自动调用的方法。
细节:通过索引从self.data中取出图像路径和标签,调用preprocess_image预处理图像,并将标签转换为整型。
2.2.6数据集长度方法 __len__
def __len__(self):
return len(self.data)
作用:返回数据集中的样本数量,这对于循环遍历数据集和分批次训练至关重要。
综上所述,load_datasets.py中的DatasetLoader类为猫狗识别项目提供了一个高效且灵活的数据加载解决方案,简化了从原始数据到模型输入的整个流程,是项目成功实施的基础之一。
2.2.7完整代码
import csv
import os
from torchvision import transforms
from PIL import Image
from torch.utils.data import Dataset
class DatasetLoader(Dataset):
def __init__(self, csv_path):
self.csv_file = csv_path
with open(self.csv_file, 'r') as file:
self.data = list(csv.reader(file))
self.current_dir = os.path.dirname(os.path.abspath(__file__))
def preprocess_image(self, image_path):
"""
Preprocess the image: Read the image, apply transformations, and return the transformed image.
"""
full_path = os.path.join(self.current_dir, 'datasets', image_path)
image = Image.open(full_path)
image_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
return image_transform(image)
def __getitem__(self, index):
"""
Return the preprocessed image and its label at the specified index from the dataset.
"""
image_path, label = self.data[index]
image = self.preprocess_image(image_path)
return image, int(label)
def __len__(self):
"""
Return the number of items in the dataset.
"""
return len(self.data)
2.3、train的编写
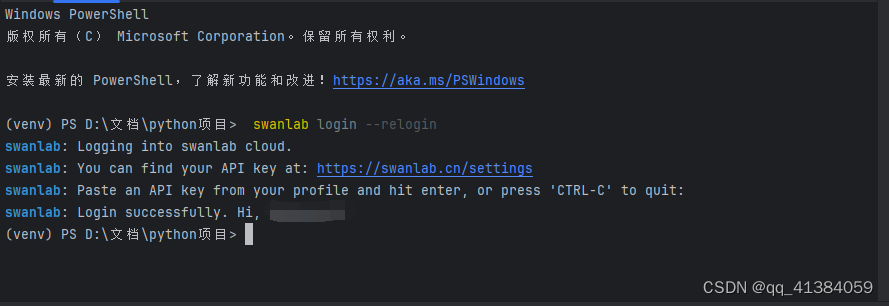
2.3.1注册并登录SwanLab
重要:需要先在主页 - SwanLab上注册账号获取API否则程序无法运行
注册账号
输入手机号和验证码
登录后点击右上角设置
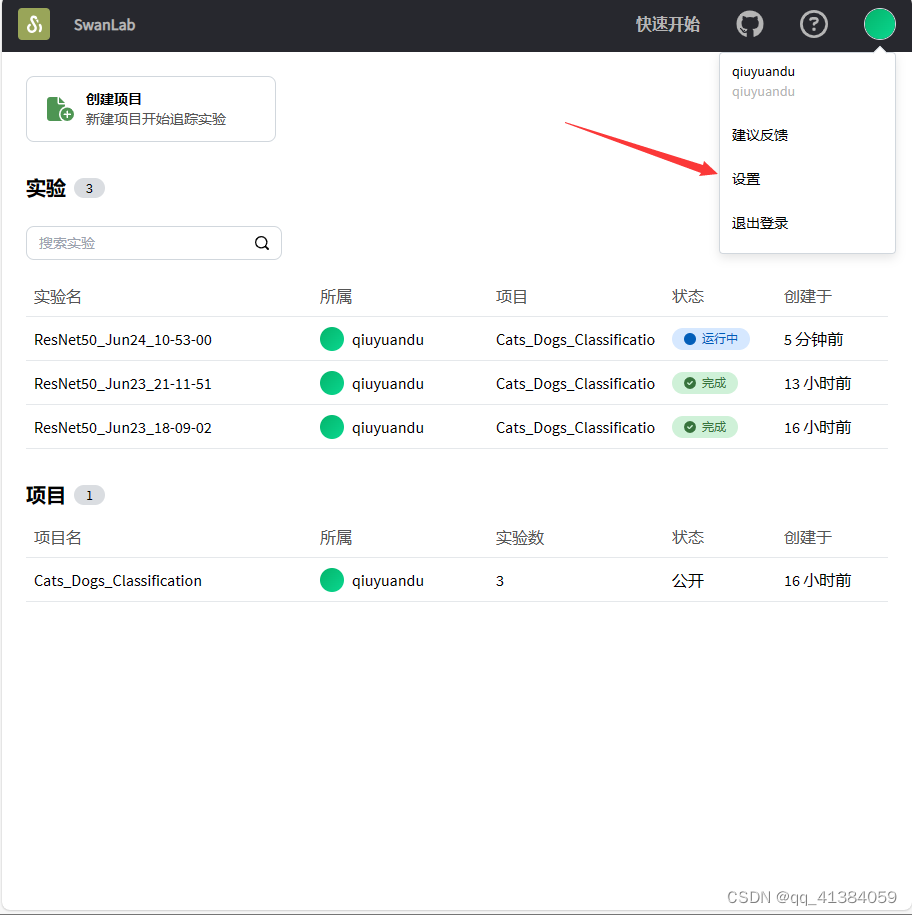
复制API key
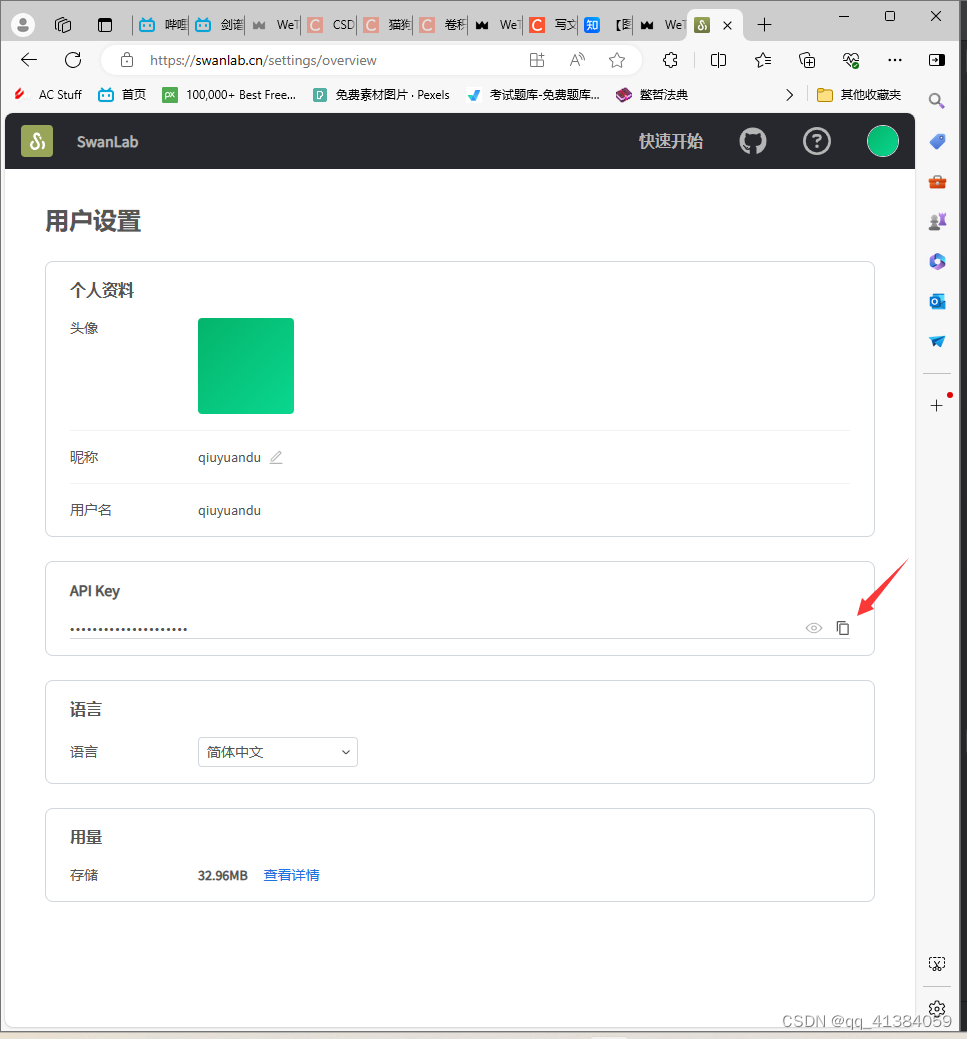
在终端中输入:swanlab login
输入刚才复制的API key
登录成功
开始编写train.py(完整代码在2.3.6)
2.3.2导入库与初始化
import torch
import torchvision
from torchvision.models import ResNet50_Weights
import swanlab
from torch.utils.data import DataLoader
from load_datasets import DatasetLoader
import os
from swanlab import login
login()导入依赖:导入了进行深度学习模型训练所需的库,包括torch、torchvision用于构建和训练模型,swanlab用于实验管理和日志记录,以及自定义的DatasetLoader用于加载数据集。
SwanLab登录:使用swanlab.login()进行登录,以启用实验追踪功能。
2.3.3定义训练函数
def train(model, device, train_dataloader, optimizer, criterion, epoch):
model.train()
for iter, (inputs, labels) in enumerate(train_dataloader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print('Epoch [{}/{}], Iteration [{}/{}], Loss: {:.4f}'.format(epoch, num_epochs, iter + 1, len(TrainDataLoader),
loss.item()))
swanlab.log({"train_loss": loss.item()})功能:定义模型训练逻辑,包括模型切换到训练模式、逐批数据的前向传播、损失计算、梯度清零、反向传播和优化器更新。
关键操作:
model.train():设置模型为训练模式。
optimizer.zero_grad():清空梯度,避免累加。
loss.backward():计算梯度。
optimizer.step():更新模型参数。
2.3.4定义测试函数
def test(model, device, test_dataloader, epoch):
class_name = ["cat", "dog"]
model.eval()
correct = 0
total = 0
with torch.no_grad():
images_list = []
for iter, (inputs, labels) in enumerate(test_dataloader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
if iter < 30:
images_list.append(swanlab.Image(inputs, caption=class_name[predicted.item()]))
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total * 100
print('Accuracy: {:.2f}%'.format(accuracy))
swanlab.log({"test_acc": accuracy})
swanlab.log({"Image": images_list})功能:评估模型在验证集上的性能,包括准确率计算和可视化部分预测结果。
特性:
model.eval():设置模型为评估模式,关闭dropout等训练时特有的行为。
使用torch.no_grad()上下文管理器,避免在测试时计算梯度,节省内存。
计算准确率并展示前30张预测图像。
2.3.5主程序
if __name__ == "__main__":
num_epochs = 20
lr = 1e-4
batch_size = 8
num_classes = 2
# 设置device
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化swanlab
swanlab.init(
# 设置项目、实验名和实验介绍
project="Cats_Dogs_Classification",
experiment_name="ResNet50",
description="用ResNet50训练猫狗分类任务",
# 记录超参数
config={
"model": "resnet50",
"optim": "Adam",
"lr": lr,
"batch_size": batch_size,
"num_epochs": num_epochs,
"num_class": num_classes,
"device": device,
},
)
TrainDataset = DatasetLoader("datasets/train.csv")
ValDataset = DatasetLoader("datasets/val.csv")
TrainDataLoader = DataLoader(TrainDataset, batch_size=batch_size, shuffle=True)
ValDataLoader = DataLoader(ValDataset, batch_size=1, shuffle=False)
# 载入ResNet50模型
model = torchvision.models.resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
# 将全连接层替换为2分类
in_features = model.fc.in_features
model.fc = torch.nn.Linear(in_features, num_classes)
model.to(torch.device(device))
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 开始训练
for epoch in range(1, num_epochs + 1):
train(model, device, TrainDataLoader, optimizer, criterion, epoch) # Train for one epoch
if epoch % 4 == 0: # Test every 4 epochs
accuracy = test(model, device, ValDataLoader, epoch)
# 保存权重文件
if not os.path.exists("checkpoint"):
os.makedirs("checkpoint")
torch.save(model.state_dict(), 'checkpoint/latest_checkpoint.pth')
print("Training complete")超参数设置:定义了训练轮数、学习率、批次大小、类别数等。
设备选择:根据硬件情况自动选择最佳的计算设备。
SwanLab初始化:配置实验信息,包括项目名称、实验名、描述以及记录超参数。
数据加载:使用DatasetLoader加载训练集和验证集数据。
模型准备:加载预训练的ResNet50模型,并调整最后的全连接层适应二分类任务。
训练与验证循环:按轮次进行训练,每4轮进行一次验证并记录结果。
模型保存:训练结束后保存模型权重,便于后续使用。
2.3.6完整代码:
import torch
import torchvision
from torchvision.models import ResNet50_Weights
import swanlab
from torch.utils.data import DataLoader
from load_datasets import DatasetLoader
import os
from swanlab import login
login()
# 定义训练函数
def train(model, device, train_dataloader, optimizer, criterion, epoch):
model.train()
for iter, (inputs, labels) in enumerate(train_dataloader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print('Epoch [{}/{}], Iteration [{}/{}], Loss: {:.4f}'.format(epoch, num_epochs, iter + 1, len(TrainDataLoader),
loss.item()))
swanlab.log({"train_loss": loss.item()})
# 定义测试函数
def test(model, device, test_dataloader, epoch):
class_name = ["cat", "dog"]
model.eval()
correct = 0
total = 0
with torch.no_grad():
images_list = []
for iter, (inputs, labels) in enumerate(test_dataloader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
if iter < 30:
images_list.append(swanlab.Image(inputs, caption=class_name[predicted.item()]))
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total * 100
print('Accuracy: {:.2f}%'.format(accuracy))
swanlab.log({"test_acc": accuracy})
swanlab.log({"Image": images_list})
if __name__ == "__main__":
num_epochs = 20
lr = 1e-4
batch_size = 8
num_classes = 2
# 设置device
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化swanlab
swanlab.init(
# 设置项目、实验名和实验介绍
project="Cats_Dogs_Classification",
experiment_name="ResNet50",
description="用ResNet50训练猫狗分类任务",
# 记录超参数
config={
"model": "resnet50",
"optim": "Adam",
"lr": lr,
"batch_size": batch_size,
"num_epochs": num_epochs,
"num_class": num_classes,
"device": device,
},
)
TrainDataset = DatasetLoader("datasets/train.csv")
ValDataset = DatasetLoader("datasets/val.csv")
TrainDataLoader = DataLoader(TrainDataset, batch_size=batch_size, shuffle=True)
ValDataLoader = DataLoader(ValDataset, batch_size=1, shuffle=False)
# 载入ResNet50模型
model = torchvision.models.resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
# 将全连接层替换为2分类
in_features = model.fc.in_features
model.fc = torch.nn.Linear(in_features, num_classes)
model.to(torch.device(device))
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 开始训练
for epoch in range(1, num_epochs + 1):
train(model, device, TrainDataLoader, optimizer, criterion, epoch) # Train for one epoch
if epoch % 4 == 0: # Test every 4 epochs
accuracy = test(model, device, ValDataLoader, epoch)
# 保存权重文件
if not os.path.exists("checkpoint"):
os.makedirs("checkpoint")
torch.save(model.state_dict(), 'checkpoint/latest_checkpoint.pth')
print("Training complete")2.3.7训练过程
完成以上步骤后就可以点击运行开始训练了
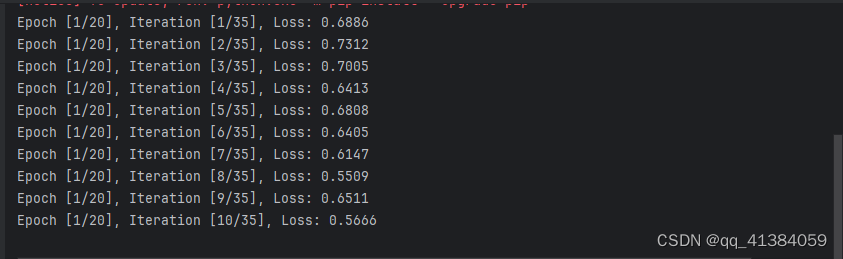
等待训练完成
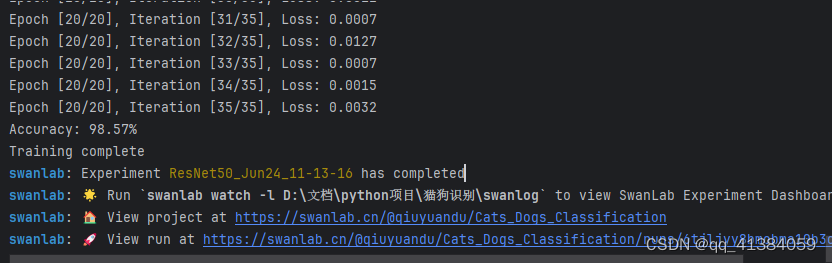
训练完成
3、搭建交互式应用(编写app.py,完整代码见3.7)
3.1导入库和初始化设置
import gradio as gr
import torch
import torchvision.transforms as transforms
import torch.nn.functional as F
import torchvision
这部分代码导入了必要的库:gradio 用于创建交互式界面,torch 及其相关模块用于深度学习模型的加载和操作,torchvision 提供了预训练模型和图像处理工具
3.2加载模型函数
图像预处理函数
# 加载与训练中使用的相同结构的模型
def load_model(checkpoint_path, num_classes):
# 加载预训练的ResNet50模型
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
model = torchvision.models.resnet50(weights=None)
in_features = model.fc.in_features
model.fc = torch.nn.Linear(in_features, num_classes)
model.load_state_dict(torch.load(checkpoint_path, map_location=device))
model.eval() # Set model to evaluation mode
return model定义了一个函数 load_model,它根据给定的检查点路径 (checkpoint_path) 和类别数 (num_classes) 加载预训练的 ResNet50 模型。此函数还根据当前硬件环境(CUDA、MPS 或 CPU)选择合适的设备来加载模型,并将模型设置为评估模式。
3.3图像预处理函数
# 加载图像并执行必要的转换的函数
def process_image(image, image_size):
# Define the same transforms as used during training
preprocessing = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = preprocessing(image).unsqueeze(0)
return image定义了 process_image 函数,用于对输入的图像进行预处理,包括调整图像大小至 image_size x image_size,将其转换为张量格式,并进行归一化处理,以匹配模型训练时的数据预处理步骤。
3.4预测函数
# 预测图像类别并返回概率的函数
def predict(image):
classes = {'0': 'cat', '1': 'dog'} # Update or extend this dictionary based on your actual classes
image = process_image(image, 256) # Using the image size from training
with torch.no_grad():
outputs = model(image)
probabilities = F.softmax(outputs, dim=1).squeeze() # Apply softmax to get probabilities
# Mapping class labels to probabilities
class_probabilities = {classes[str(i)]: float(prob) for i, prob in enumerate(probabilities)}
return class_probabilities
定义了 predict 函数,该函数接收一个图像,首先调用 process_image 进行预处理,然后使用模型进行预测。预测结果通过 Softmax 函数转换为概率分布,并将概率与类别标签(猫或狗)关联,最后以字典形式返回。
3.5模型和Gradio界面配置
# 定义到您的模型权重的路径
checkpoint_path = 'checkpoint/latest_checkpoint.pth'
num_classes = 2
model = load_model(checkpoint_path, num_classes)
# 定义Gradio Interface
iface = gr.Interface(
fn=predict,
inputs=gr.Image(type="pil"),
outputs=gr.Label(num_top_classes=num_classes),
title="Cat vs Dog Classifier",
)
这部分代码首先设置了模型权重文件的路径和分类任务的类别数,然后加载模型。之后,使用 gradio 库创建了一个用户界面,其中输入是一个 PIL 格式的图像,输出是预测的标签,界面上方显示为 "Cat vs Dog Classifier"。
3.6主程序入口
if __name__ == "__main__":
iface.launch()这部分代码确保当脚本直接运行时(而非作为模块被导入时),将启动 Gradio 界面,允许用户通过 Web 界面上传图片并获取猫狗分类的结果。
运行程序后出现一个IP地址,点击进入

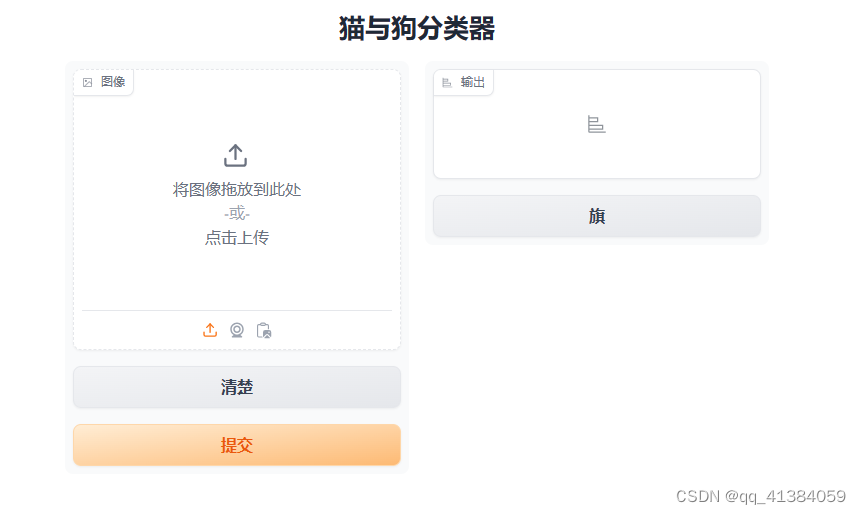
接下来上次猫猫狗狗的照片就可以开始识别了
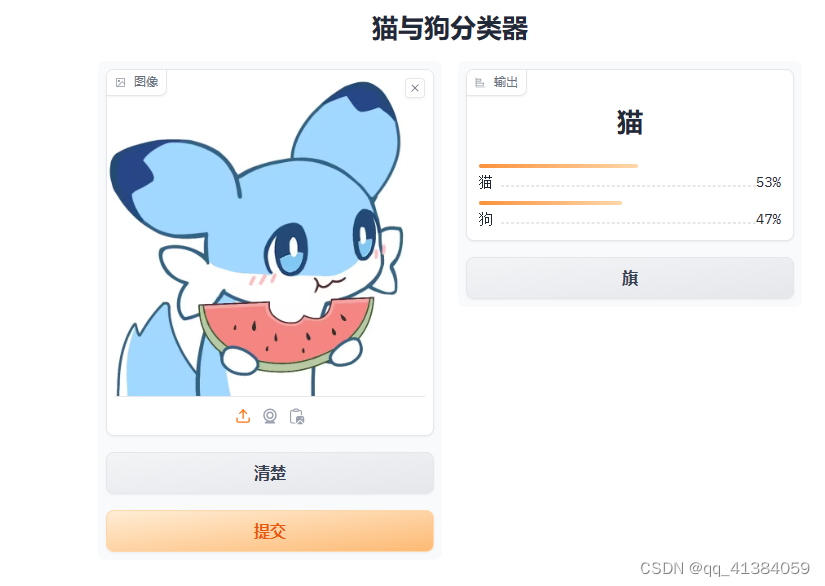
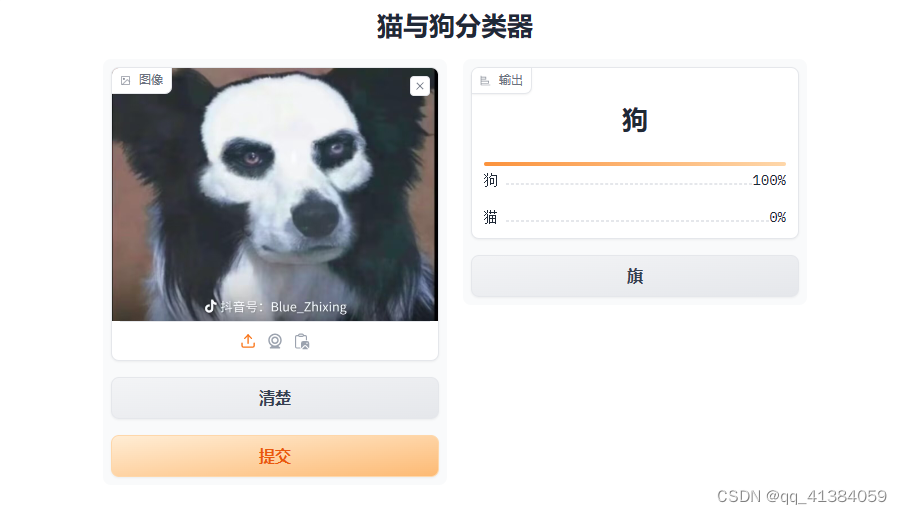

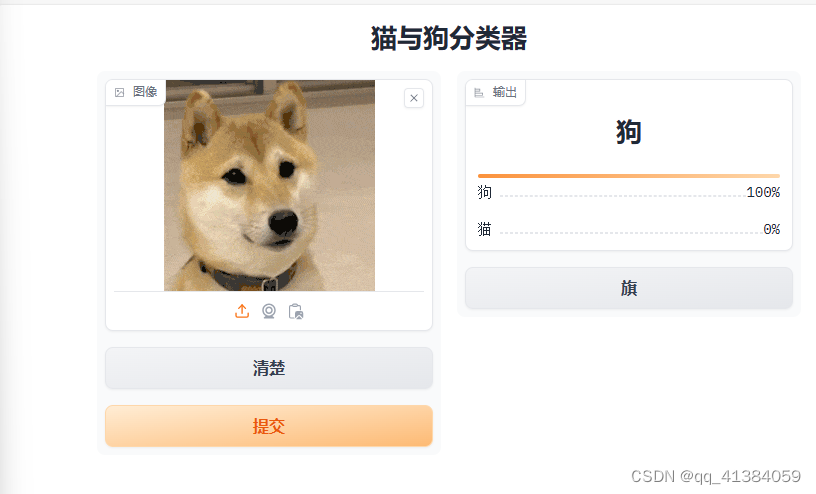
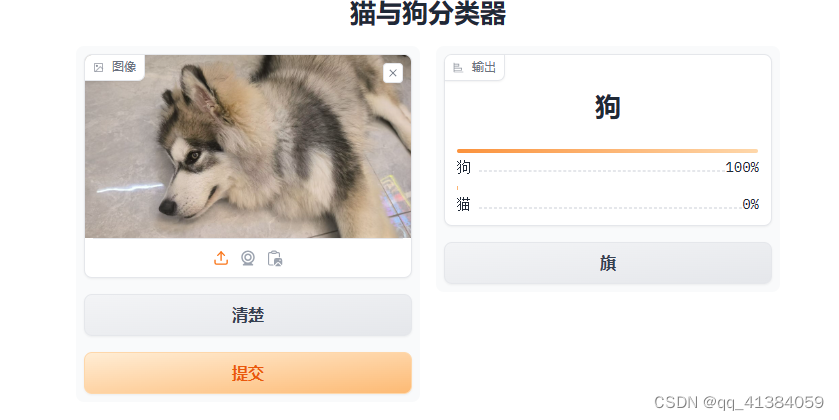
3.7完整代码
import gradio as gr
import torch
import torchvision.transforms as transforms
import torch.nn.functional as F
import torchvision
# 加载与训练中使用的相同结构的模型
def load_model(checkpoint_path, num_classes):
# 加载预训练的ResNet50模型
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
model = torchvision.models.resnet50(weights=None)
in_features = model.fc.in_features
model.fc = torch.nn.Linear(in_features, num_classes)
model.load_state_dict(torch.load(checkpoint_path, map_location=device))
model.eval() # Set model to evaluation mode
return model
# 加载图像并执行必要的转换的函数
def process_image(image, image_size):
# Define the same transforms as used during training
preprocessing = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = preprocessing(image).unsqueeze(0)
return image
# 预测图像类别并返回概率的函数
def predict(image):
classes = {'0': 'cat', '1': 'dog'} # Update or extend this dictionary based on your actual classes
image = process_image(image, 256) # Using the image size from training
with torch.no_grad():
outputs = model(image)
probabilities = F.softmax(outputs, dim=1).squeeze() # Apply softmax to get probabilities
# Mapping class labels to probabilities
class_probabilities = {classes[str(i)]: float(prob) for i, prob in enumerate(probabilities)}
return class_probabilities
# 定义到您的模型权重的路径
checkpoint_path = 'checkpoint/latest_checkpoint.pth'
num_classes = 2
model = load_model(checkpoint_path, num_classes)
# 定义Gradio Interface
iface = gr.Interface(
fn=predict,
inputs=gr.Image(type="pil"),
outputs=gr.Label(num_top_classes=num_classes),
title="Cat vs Dog Classifier",
)
if __name__ == "__main__":
iface.launch()5、结言
到这里这个项目就基本结束了,这个项目实现了前端后端的开发和SwanLab、resnet50等工具的应用,成功实现了猫和狗的分类。
至此,我们不仅完成了一个综合性的机器学习项目,而且跨越了从前端展示到后端逻辑处理的全过程,成功地将深度学习技术与Web应用开发相结合,创造了一个实用且直观的图像分类工具。
6、参考文献
【图像分类】PyTorch猫狗分类(完整源码+SwanLab可视化+Gradio Demo) - 知乎 (zhihu.com)

















 1713
1713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









