







 本文介绍了机器学习中的最大似然估计原理,通过中心极限定理来理解数据分布,并详细阐述了概率密度函数、损失函数的概念。接着,文章通过解析解的方式解释了线性回归的优化过程,最终给出了使用代码实现解析解的示例,包括直接实现和使用sklearn库的简化方式。
本文介绍了机器学习中的最大似然估计原理,通过中心极限定理来理解数据分布,并详细阐述了概率密度函数、损失函数的概念。接着,文章通过解析解的方式解释了线性回归的优化过程,最终给出了使用代码实现解析解的示例,包括直接实现和使用sklearn库的简化方式。
最大似然估计

通俗来讲:假设你有一组身高的数据,有两个正态分布(踢足球的和打篮球的),打篮球的正态分布肯定是那种又细又高的,而踢足球的是宽低的,
最大似然估计就是,把数据带进去看它属于哪个正态分布,假设有个一米九的,我们就可以猜出他是打篮球的
中心极限定理

在这里,我们的随机变量是误差的值
概率密度函数

概率密度函数:当f(x)越大说明某个x出现在这个正态分布上的概率越大
f(x)并不是概率,而是概率密度,因为概率不好求,所以我们求概率密度,如下图
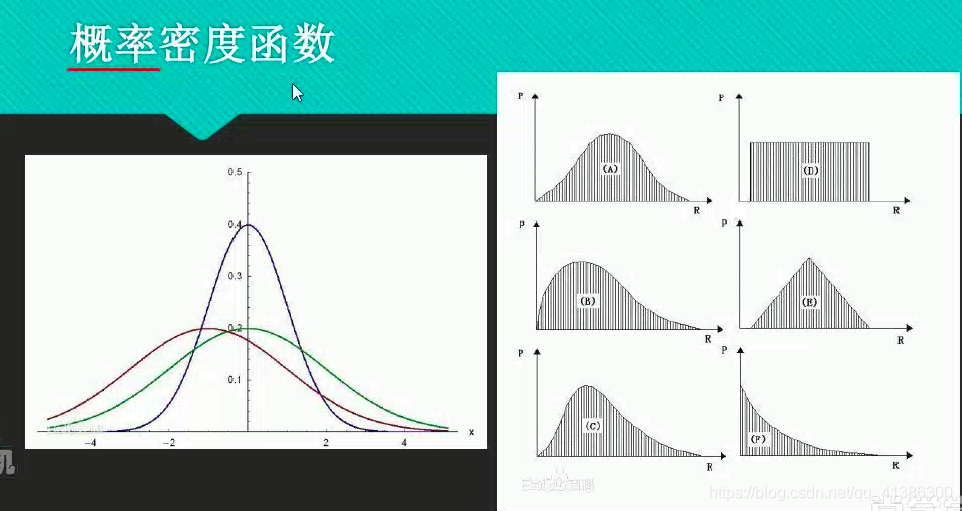
上图中的阴影部分的面积就是概率,它不好求,需要积分,所以我们用概率密度代替,效果一样,当概率密度最大的时候就是最优解
损失函数
下图是化解步骤:

L:最大总似然估计:m个样本里的每个样本的似然相乘
因为相乘不好算,所以我们取对数
取对数可以把连乘变成连加,如下

上图中第四行:减号前面的值是固定的,所以减号后面的值越小整个值就越大
所以上图中最后的式子就是我们的线性回归的损失函数,我们要求得就是损失函数最小的时候

解析解
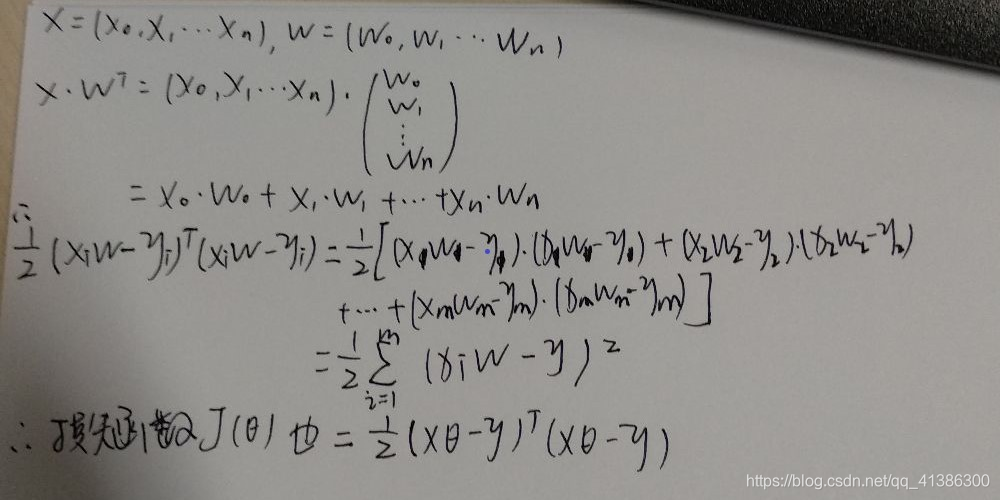
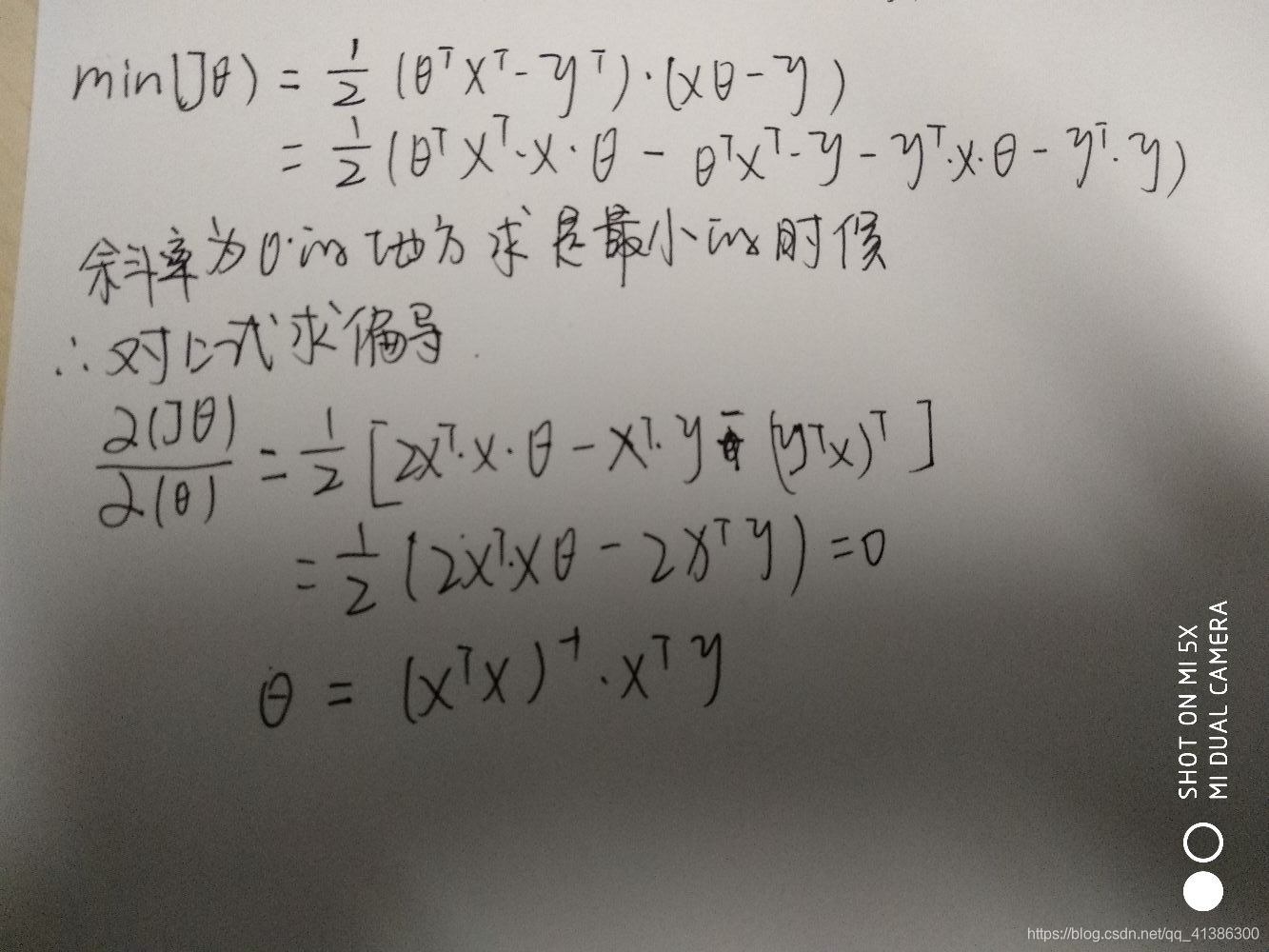

代码实现
用代码实现——用解析解的方式求解模型
import numpy as np
import matplotlib.pyplot as pl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4852
4852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









