







数据集处理
数据集
数据的形式:结构化、非结构化、图片、序列数据(语音、视频)、时序数据(流媒体文件数据、传感器数据、股价、日志数据等)
时序数据一般使用循环神经网络来处理
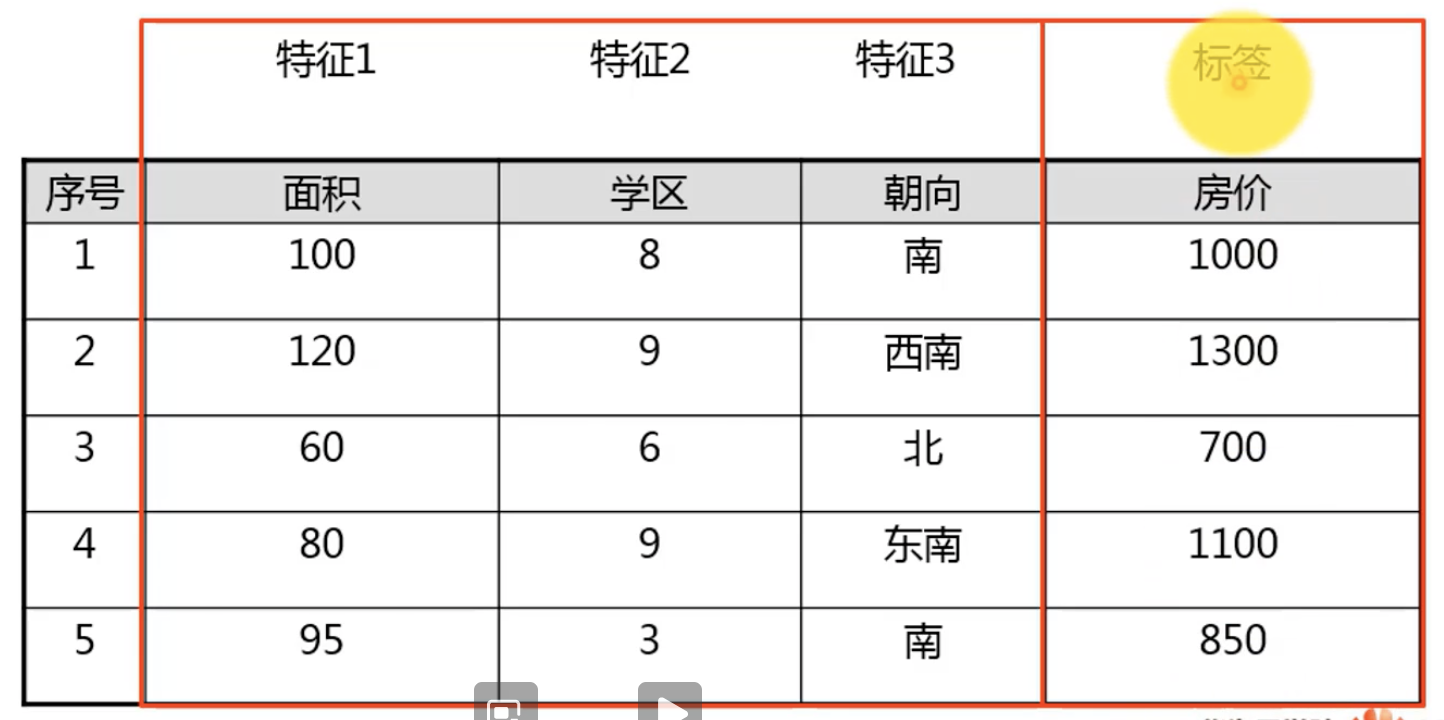
数据集:机器学习中的一组数据
样本:一组数据中的每一个数据
特征:反应样本的某些性质或者属性
标签:要被预测的数据
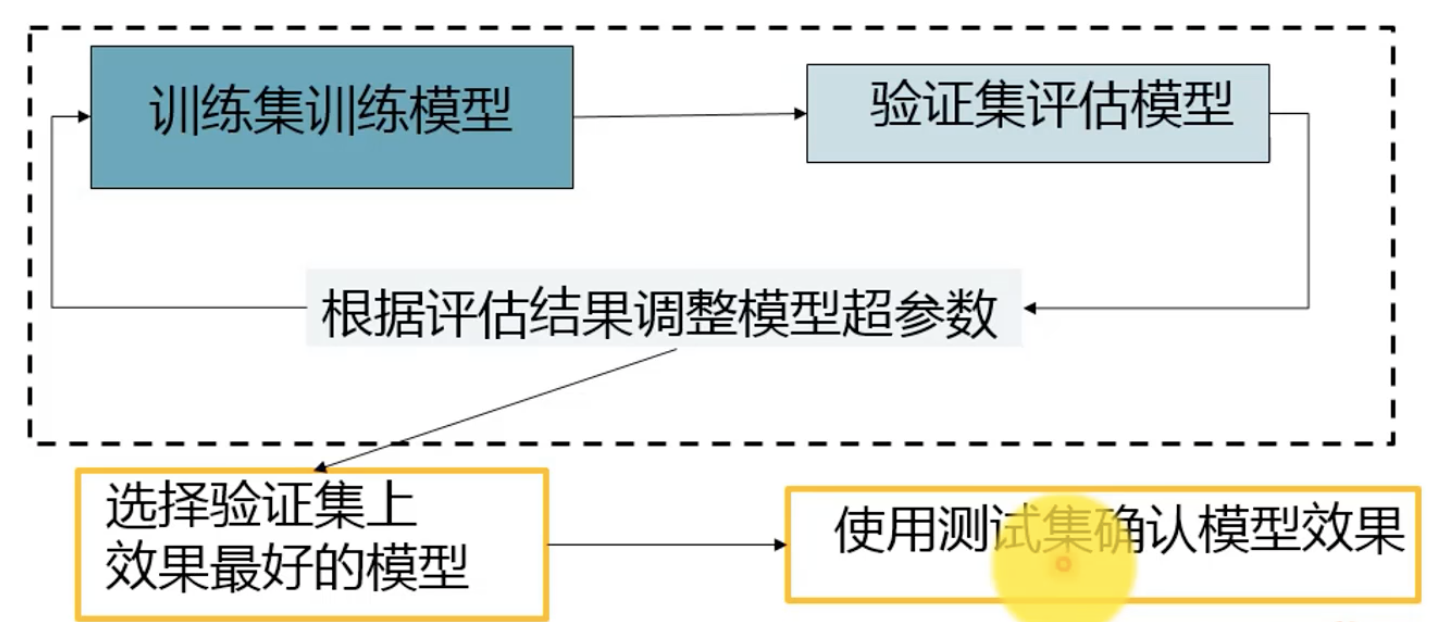
训练集(train dataset):构建机器学习模型,从数据中确定模型参数的过程称为学习、训练。(根据经验)
验证集(validation dataset):辅助构建模型,用于构建过程中评估模型,调整模型参数
测试集(test dataset):评估训练好的最终模型的性能
数据集分割
如何确定训练集和测试集是同分布的?
留出法
直接将数据集拆分为互斥的训练集、验证集和测试集
训练集 : 验证集 : 测试集 = 10%: 15% : 15%
1、单次使用留出法会导致模型不稳定。(可以多次随机划分,重复进行实验评估后取平均值作为留出法的评估结果。)
2、保证三种数据集中样本比例的相似性。(例 : 1000个样本 (正 :600 ;负: 400) 。则训练集和测试集中,正例和负例的比也要求为3:2。实现方式 : 随机分层抽样。)
3、适合大数据集
K折交叉验证法

实际上通常训练集和测试集不是同分布的,我们要尽可能使训练集和测试集的数据分布的属性一致,找到更多与测试集样本相更匹配的训练集数据
偏差与方差
-
偏差
-
训练集误差
-
训练集预测值 - 真实值
-
原因:算法的拟合程度:真实模型没有包含在训练模型中,比如用线性模型预测非线性模型
-
结果距靶心🎯的距离
-
高偏差如何避免?
- 尝试用更大的模型
- 演唱训练时间
- 常使用心得模型架构
- 减少正则化
-
-
方差
-
验证集误差 -训练集误差
-
同样大小的训练集的变动所导致的学习性能的变化
-
原因:模型的不稳定
-
结果的离散程度
-
如何避免高方差?
- 获取更多数据 ( 包括数据合成和数据增强 )
- 添加正则化
- 尝试提早停止训练 ( early stopping )
- 尝试用新的模型架构
-

过拟合问题:数据集太少。方差很大
-
训练集、测试集失配
- 训练和验证集误差都较小,但是测试集的误差大
- 需要获取更多和测试集相似的数据的
-
权衡偏差和方差
- 训练不足:拟合较弱,偏差主导错误率
- 训练过多:过拟合,方差主导错误率















 1218
1218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









