





上篇文章中讲到回溯算法的本质就是暴力搜索,但是可以通过剪枝来进行优化。
那么,剪枝到底剪了什么?如何剪?
我们仍然以上篇文章的组合问题来进行讨论。
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按 任何顺序 返回答案。
剪枝到底剪了什么
Carl师兄的网站上给出的剪枝优化的图如下:
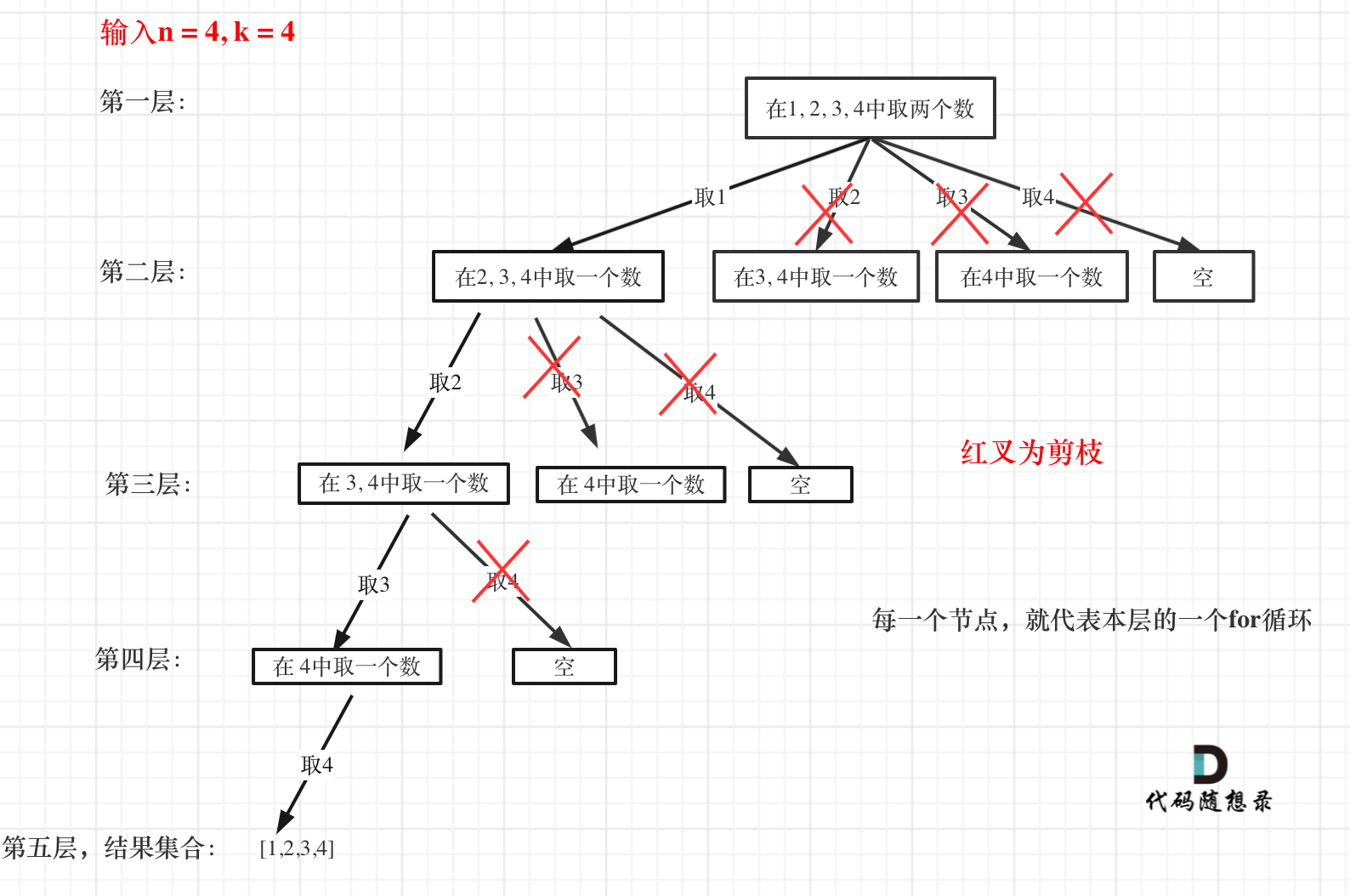
-
所谓的剪枝就是优化每一层的for循环。
不剪枝
为了对比,我们先查看原始的回溯算法输出:
class Solution:
def combine(self, n: int, k: int) -> List[List[int]]:
res = []
path = []
def backtrack(n, k, StartIndex):
if len(path) == k:
res.append(path[:])
return
for i  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









