







 本文介绍了深度残差网络(ResNet)为解决深度学习中网络退化问题提出的创新思想。ResNet通过学习从X到Y-X的差值,有效地解决了模型训练困难和梯度消失问题。残差网络的优势在于随着深度增加能提升精度,优化简单且通用。文中还展示了在Pytorch中实现残差块的基本步骤,并强调了保持输入与残差张量尺寸一致的重要性。
本文介绍了深度残差网络(ResNet)为解决深度学习中网络退化问题提出的创新思想。ResNet通过学习从X到Y-X的差值,有效地解决了模型训练困难和梯度消失问题。残差网络的优势在于随着深度增加能提升精度,优化简单且通用。文中还展示了在Pytorch中实现残差块的基本步骤,并强调了保持输入与残差张量尺寸一致的重要性。
在深度学习中,为了增强模型的学习能力,网络层会变得越来越深,但是随着深度的增加,也带来了比较一些问题,主要包括:
-
模型复杂度上升,网络训练困难; -
梯度消失/梯度爆炸 -
网络退化,也就是说模型的学习能力达到了饱和,增加网络层数并不能提升精度了。
为了解决网络退化问题,何凯明大佬提出了深度残差网络,可以说是深度学习中一个非常大的创造性工作。
残差网络
残差网络的思想就是将网络学习的映射从X到Y转为学习从X到Y-X的差,然后把学习到的残差信息加到原来的输出上即可。即便在某些极端情况下,这个残差为0,那么网络就是一个X到Y的恒等映射。其示意图如下:
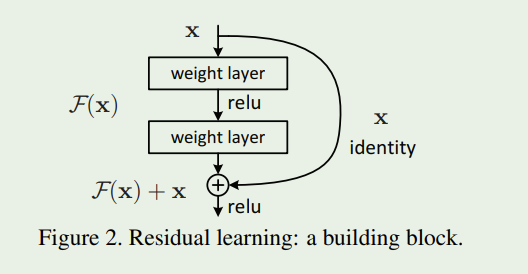
上图的结构中其实主线与正常的网络结构没什么区别,差异在于右边的连接线,作者称之为Shortcut Connection,意思就是跳过了一些网络层直接与后面的某一个层的输出结果进行连接。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7149
7149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









