







必要性
NMS(非极大值抑制)是目标检测中用来确定最佳检测框的手段,根据目标检测流程,若果没有NMS步骤,其每个检测框都会有大量重叠度很高的预测框表示同一个目标。如下图:
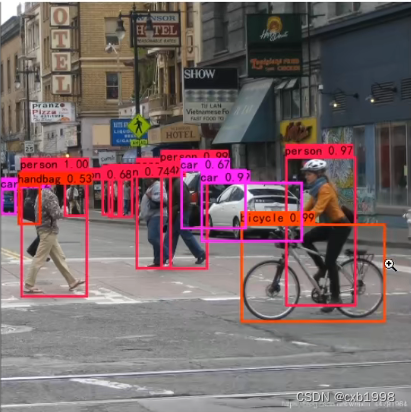
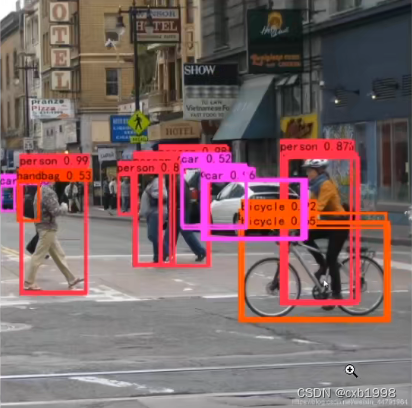
左图为经过NMS的预测结果,右图为未经过NMS的结果,很明显,左图才是我们需要的结果。
过程
以yolo为例,其预测结果tensor为(bs,boxes,location(4)+confidence+num_classes)的形式。
NMS的python代码实现:
def non_max_supperression(boxes, num_classes, conf_thres=0.5, nms_thres=0.4):
bs = np.shape(boxes)[0]
#boxes中的location是(中心x,中心y, 宽w, 高h)形式的,需要调整为(左上x,左上y,右下x,右下y)的形式,方便IOU的计算。
shape_boxes = np.zeros_like(boxes[:,:,:4])
shape_boxes[:,:,0] = boxes[:,:,0] - boxes[:,:,2] / 2
shape_boxes[:,:,1] = boxes[:,:,0] - boxes[:,:,3] / 2
shape_boxes[:,:,2] = boxes[:,:,0] + boxes[:,:,2] / 2
shape_boxes[:,:,3] = boxes[:,:,0] + boxes[:,:,3] / 2
#替换
boxes[:,:,:4] = shape_boxes;
output=[]
#对每张图进行处理
for i in range(bs):
#prediction与boxes相比,bs维度没有了:(num_box,4+1+num_class)
prediction = boxes[i];
#取出置信度
score = prediction[:,4]
#如果置信度低于阈值,则直接忽略,高于阈值的才进行下一步的抑制
mask = score > conf_thres
detction = prediction[mask]
#取预测框的类别和对应的预测概率
class_conf = np.expand_dims(np.max(detction[:,5:],axis=-1),axis=-1)
class_pred = np.expand_dims(np.argmax(detection[:,5:],axis=-1),axis=-1)
#predction进行重组,此时的prediction为[num_box,4(转换后的框位置信息)+1(有目标的置信
# 度)+2(目标的类别置信度和类别归属)
prediction = np.concatenate([prediction[:,:5],class_conf,class_pred],-1)
#图中都有哪些类别
unique_class = np.unique(detection[:,-1])
if len(unique_class) == 0:
continue;
#列表对抑制后的box进行存储
best_box = []
for c in unique_class:
cls_mask = detection[:,-1] == c
#选出了该类别的detection
detection_chosen = detection[cls_mask]
#根据是否有目标的置信度进行排序
scores = detction_chosen[:,4]
arg_sort = np.argsort(scores)[::-1]//np.argsort升序排,取反进行降序排
detction_chosen = detction_chosen[arg_sort]
while len(detction_chosen) != 0:
#将具有最大置信度的框加入结果框列表中
best_box.append(detction_chosen[0])
#框只有一个,则不用筛选了
if len(detction_chosen)==1:
break
#计算该框与其他同类框的交并比iou
ious = iou(best_box[-1],detction_chosen[1:])
#筛选剩下交并比小于设定阈值的检测框,因为交并比小的框可能来自其他同类目标,而交
并比过大的应当是对同一个目标的重复预测
detction_chosen = detction_chosen[1:][ious<nms_thres]
#将每张图各个类别的最佳预测框返回
output.append(best_box)
return np.array(output)
def iou(b1,b2)
#参考框b1的左上角x,y以及右下角x,y
b1_x1,b1_y1,b1_x2,b1_y2 = b1[0],b1[1],b1[2],b1[3]
#待比较的框的左上角x,y以及右下角x,y
b2_x1,b2_y1,b2_x2,b2_y2 = b2[:,0],b2[:,1],b2[:,2],b2[:,3]
#求 相交部分 矩形的左上角x,y以及右下角x,y
inter_rect_x1 = maximum(b1_x1,b2_x1)
inter_rect_y1 = maximum(b1_y1,b2_y1)
inter_rect_x2 = minimum(b1_x2,b2_x2)
inter_rect_y2 = minimum(b1_y2,b2_y2)
#求 相交部分 矩形的面积,与0相比取最大值是因为存在框不相交的情况
inter_area = maximum(inter_rect_x2-inter_rect_x1,0) * \
maximum(inter_rect_y2-inter_rect_y1,0)
#分别求两个检测框的面积,用来计算 并 的面积
area_b1 = (b1_x2-b1_x1) * (b1_y2-b1_y1)
area_b2 = (b2_x2-b2_x1) * (b2_y2-b2_y1)
#交并比
iou = inter_area / maximum(area_b1-area_b2),1e-6)
return iou部署时需后处理NMS通过c在CPU或GPU上完成,首先是CPU:
//Box为自定义类,其成员变量有left,top,right,bottom,confidence和label
vector<Box> cpu_decode(float* predict, int rows, int cols, float con_thres=0.25f, float
nms_thres = 0.45f){
//predict为python训练端保存过来的预测结果向量,boxes用来存储坐标转换后的中间向量
vector<Box> boxes;
//向量前五列为4(框信息)+1(是否有目标的置信度),不包含类别信息
int num_classes = cols - 5;
//对每个框进行处理
for(int i=0; i<rows; i++){
//获取每一行的地址
float* pitem = predict+i*cols;
//获取是否有目标的置信度
float objnesee = pitem[4]
//如果置信度低于设定阈值,不需要任何处理直接忽略就可以了,节省运行时间
if(objness < con_thres){
continue;
}
//获取每一行表示类别信息的地址
float* pclass = pitem+5;
//获取分类类别置信度最大的类别标签
int label = std::max_element(pclass,pclass + num_classes) - pclass;
//获取确定类别的分类置信度
float prob = pclass[label];
//我们将后面的置信度表示为有无目标的置信度*目标所属确定类别的置信度,并根据该置信度进行抑制
float confidence = prob*objness;
if(objness < con_thres){
continue;
}
//同样需要对原向量中的框信息做处理,改成左上角和右下角坐标,以便iou计算
float cx = pitem[0];
float cy = pitem[1];
float width = pitem[2];
float height = pitem[3];
float left = cx - 0.5*width;
float top = cy - 0.5*height;
float right= cx + 0.5*width;
float bottom = cy + 0.5*height;
//存入boxes中,emplace_back相比push_back可以直接在容器内执行对象构造,无需额外的拷贝构
造,例如用push_back则需要为boxes.push_back(Box(left,top,right,bottom,confidence,
(float)label)
boxes.emplace_back(left,top,right,bottom,confidence,(float)label);
}
//将转换好的向量存入boxes中后就是NMS操作了
//NMS
//首先对boxes中的向量根据置信度进行从大到小的排序,这里用匿名函数来定义sort排序规则
std::sort(boxes.begin(),boxes.end(),[](Box& a,Box& b){return
a.confidence>b.confidence;});
//定义remove_flags标记boxes中哪些框是需要保留的,哪些框是要删除的
vector<bool> remove_flags(boxes.size());
//用来存储抑制后的结果框
vector<Box> box_result;
//预分配内存,防止不断动态分配内存带来的耗时
box_result.reserve(boxes.size());
//iou计算函数
auto iou = [](const Box& a,const Box& b){
//获取相交矩形的左上、右下坐标
float cross_left = std::max(a.left,b.left);
float cross_top = std::max(a.top,b.top);
float cross_right = std::min(a.right,b.right);
float cross_bottom = std::min(a.bottom,b.bottom);
//计算相交矩形的面积
float cross_area = std::max(0.0f, cross_right-cross_left)
* std::max(0.0f, cross_bottom-cros_top));
//计算相并面积
float union_area = std::max(a.right-a.left,0.0f) * std::max(a.bottom-a.top,0.0f)
+ std::max(b.right-b.left,0.0f) * std::max(b.bottom-b.top,0.0f)
- cross_area;
if(cross_area || union_area == 0) return 0.0f;
return cross_area / union_area;
};
for(int i=0;i<boxes.size();++i){
//重复的非最大置信度的预测框将会被置true去除
if(remove_flags[i] continue;
auto& ibox = boxes[i];
//没有标记的框被存入结果框中
box_result.emplace_back(ibox);
for(int j=i+1;j<boxes.size();++j){
if(remove_flags[j]) continue;
auto& jbox = boxes[j];
//ibox和jbox类别一致时才进行抑制,因为要去除的重复框是同位置同类别的框
if(ibox.label == jbox.label){
//当两个预测框的交并比大于给定阈值,则打上移除标记
if(iou(ibox,jbox) >= nms_thres){
remove_flags[j] = true;
}
}
}
}
return box_result;
}CUDA编程到GPU端,在CPU上做一定的修改:
//参数域cpu含义相同
vector<Box> gpu_decode(float* predict, int rows, int cols, float con_thres=0.25f, float
nms_thres = 0.45f){
vector<Box> box_result;
//创建流,一般在开头就创建,这里为了演示说明,在这里创建
cudaStream_t stream=nullptr;
checkRuntime(cudaStreamCreate(&stream));//checkRuntime为略作修改的检查代码,检查正常创建
//显卡上的传入预测框
float* predict_device = nullptr;
//显卡上处理后的结果
float* output_device = nullptr;
//显卡上处理后的结果传到host上
float* output_host = nullptr;
int max_objects = 1000;
int NUM_BOX_ELEMENT = 7;//left,top,right,bottom,confidence,class,keepflag(是否去除的flag
//分配global memory用来接收从host传过来的predict
checkRuntime(cudaMalloc(&predict_device, rows*cols*sizeof(float));
//分配global memory用来存储处理后的目标信息
checkRuntime(cudaMalloc(&output_device, max_objects * NUM_BOX_ELEMENT + sizeof(float));
//分配pinned memory用来从设备到host
checkRuntime(cudaMallocHost(&output_host, max_objects*NUM_BOX_ELEMENT+sizeof(float));
//异步复制
checkRuntime(cudaMemAsync(predict_device,predict,rows*cols**sizeof(float),
cudaMemcpyHostToDevice,stream)
//框解码和nms核函数的启动函数
decode_kernel_invoker(
predict_device,rows,cols-5,conf_thres,nms_thres,nullptr,output_device,
max_objects,NUM_BOX_ELEMENT,stream
);
//将gpu上的预测框拷贝到host
checkRuntime(cudaMemcpyAsync(output_host,output_device,
sizeof(int)+max_objects*NUM_BOX_ELEMENT*sizeof(float),
cudaMemcpyDeviceToHost,stream
));
checkRuntime(cudaStreamSynchronize(stream));
int num_boxes = min((int)output_host[0],max_objects);
//将结果框存入box_result
for(int i=0;i<num_boxes;i++{
float* ptr=output_host + 1 + NUM_BOX_ELEMENT*i;
int keep_flag = ptr[6];
if(keep_flag){
box_result.emplace_back(ptr[0],ptr[1],ptr[2],ptr[3],ptr[4],ptr[5]);
}
}
//释放流和内存
checkRuntime(cudaStreamDestroy(stream));
checkRuntime(cudaFree(predict_device));
checkRuntime(cudaFree(output_device));
checkRuntime(cudaFreeHost(output_host));
return box_result;
}
//核函数的启动函数
void decode_kernel_invoker(
float* predict,int num_bboxes,int num_classes,float conf_thres,float nms_thres,
float* invert_affine_matrix,float* parray,int max_objects,int NUM_BOXELEMENT,
cudaStream_t stream){
//确定线程的配置参数,开启线程数为num_bboxes个数
auto block = num_bboxes>512 ? 512:num_bboxes;//block一般取1024下较大的32倍数
//相当于向上取整,要达到的目的是grid*block大于等于num_bboxes且被整除
auto grid = (num_bboxes + block - 1) / block;
//调用框解码核函数
decode_kernel<<<grid,block,0,stream>>>(
predict, num_bboxes, num_classes, conf_thres,invert_affine_matrix,parray,
max_objects,NUM_BOX_ELEMENT
);
//确定线程的配置参数,开启线程数为max_objects个数
auto block = num_bboxes>512 ? 512:max_objects;//block一般取1024下较大的32倍数
//相当于向上取整,要达到的目的是grid*block大于等于num_bboxes且被整除
auto grid = (max_objects+ block - 1) / block;
//进行多线程nms
fast_nms_kernel<<<grid,block,0,stream>>>
(parray,max_objects,nms_thres,NMU_BOX_ELEMENT);
//parray中的count可能会超出max_objects,因为线程所有线程会一直执行到那一步,虽然会不符合条
件从而不往下走,但count会一直累加,因此后面要取最小值
}
static __global__ void decode_kernel(
float* predict,int num_bboxes,int num_classes,float conf_thres,
float* invert_affine_matrix,float* parray,int max_objects,int NUM_BOXELEMENT
){
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= num_bboxes) return;
//获取每个框(对应一个线程)的首地址
float* pitem = predict+(5+num_classes)*position;
//获取有无目标的置信度
float objectness = pitem[4];
if(objectness < conf_thres) return;
//获取表示类别信息的地址
float* class_confidence = pitem+5;
//获取当前对于当前指向类别的置信度,并指向下一个类别
float confidence = *class_confidence++;
int label=0;
//其实是在找类别中最大置信度的作为预测的类别
for(int i=1;i<num_classes;++i,++class_confidence){
if(*class_confidence > confidence){
confidence = *class_confidence;
label = i;
}
}
confidence* = objectness;
if(confidence < conf_thres) return;
//能执行到这说明得到了置信度足够的目标框,需要对这个框进行解码,并将解码信息存入parray
//parray = count,box1,box2,box3
//atomicAdd -> count+=1 返回的是old_count,新的值被存入内存中
int index = atomicAdd(parray,1);//
if(index >= max_objects) return;
//获取坐标信息并转化
float cx = *pitem++;
float cy = *pitem++;
float width = *pitem++;
float height = *pitem++;
float left = cx-0.5f*width;
float top = cy-0.5f*height;
float right = cx+0.5f*width;
float bottom = cy+0.5f*height;
//将转换后的left,top,right,bottom,confidence,class,keepflag填入parray
float* pout_item = parray + 1 + index * NUM_BOX_ELEMENT;
*pout_item++ = left;
*pout_item++ = top;
*pout_item++ = right;
*pout_item++ = bottom;
*pout_item++ = confidence;
*pout_item++ = label;
*pout_item++ = 1;//keepflag为1时表示保持,不删除
}
//测试mAP用cpuNMS
//日常推理可用GPU
//GPU上的NMS其实相当于开了框数量个线程,每个线程循环了框数量次(进行比较)
static __global__ void fast_nms_kernel(float* bboxes,int max_objects,float thres,
int NUM_BOX_ELEMENT){
int position = blockDim.x*blockIdx.x+threadIdx.x;
//即decode中的index,剩下的框个数,多余的线程不需要工作
int count = min((int)*bboxes,max_objects);
if(position >= count) return;
//获取当前框,对flag的操作一定在pcurrent上完成,因为pcurrent对应的是当前线程,而不是pitem
float* pcurrent = bboxes + 1 + position * NUM_BOX_ELEMENT;
//去除条件:重叠度高、类别相同、置信度低小于已有的
for(int i=0;i<count;i++){
float* pitem = bboxes + 1 + i*NUM_BOX_ELEMENT;
if(i == position || pitem[5]!=pcurrent[5]) continue;
//如果存在其他的框比当前线程表示的框置信度大,就要考虑是否保留当前线程的框了
if(pitem[4] >= pcurrent[4]){
//其他框置信度与当前框相同并且其为当前框之前的框,那么当前框保留,因为之前的框在其他
线程中与当前框的比较中被执行到下一步进行了筛选,可能被打上了移除的印记,所有线程统
一为默认保留后面的框,这样要删除的话前面的框已经被打上删除记号了
if(pitem[4]==pcurrent[4] && i<position) continue;
//计算iou
float iou = box_iou(
pcurrent[0],pcurrent[1],pcurrent[2],pcurrent[3],
pitem[0],pitem[1],pitem[2],pitem[3]
)
//重叠度过高,删除
if(iou > thres){
pcurrent[6] = 0;
return;
}
}
}
}
//只能在gpu中调用设备函数
static __device__ float box_iou(
float aleft,float atop,float aright,float abottom,
float bleft,float btop,float bright,float bbottom){
//获取相交矩形的坐标
float cleft = max(aleft,bleft);
float ctop = max(atop,btop);
float cright = min(aright,bright);
float cbottom = max(abottom,bbottom);
//相交矩形的面积
float c_area = max(cright-cleft,0.0f) * max(cbottom-ctop,0.0f);
if(c_area==0.0f) return 0.0f;
//并
float a_area = max(0.0f, aright-a_left)*max(0.0f,abottom-atop)
float b_area = max(0.0f, bright-b_left)*max(0.0f,bbottom-btop)
return c_area/(a_area+b_area-c_area);
}
以上核函数入口、核函数和设备函数需要nvcc编译,单独写cu文件不在cpp中。















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









