







双阶段
1. RCNN:

双阶段目标检测鼻祖,也是第将CNN引入目标检测任务的里程碑工作。
流程:
1. 使用selective search算法生成大概2000个region proposal区域推荐(2000*4)。
——selective search思路:先将图片分成很多小区域,按照相似度准则合并相邻区域直到 最后合并成一个区域,这个过程中出现过的所有区域就是region proposal。
2. 将所有region proposal缩放到227*227。
3. 缩放后的所有proposal送入Alexnet提取特征。
4. 将每个特征送入多个SVM(每个class对应一个SVM,判断是否属于该class)分类以及一个线性回归模型进行预测框偏移量的回归,bbx的损失为L2,分类和回归并行。
5. 非极大值抑制(分类别独立进行)。
2. SPPNet
1. 主要解决输入的图像要统一缩放成固定尺寸的,SPP使得不同的图像输出维度是固定的。
2. 另外改变RCNN的做法,生成region proposal后,先对图像整体进行特征提取,在通过映射的方式将proposal映射到特征图上,节省了时间。
做法就是在最后一层卷积层后添加SPP层,SPP层通过将特征进行不同尺度的池化后在进行拼接得到固定尺寸的特征,详情可见该博主的网站:
SPP空间金字塔池化技术的直观理解 - you-wh - 博客园
2. FAST—RCNN
解决之前目标检测的速度慢问题。
1. 实现了大部分的端到端训练(除了proposal),不需要磁盘存储特征,并且将SVM的分类和bbx的回归联合起来在CNN阶段训练(通过两个fc接两个softmax完成,bbx为smooth l1loss),网络的输入为整张图像和proposal的坐标。
2. 提出ROIpooling层,即单尺度版本的SPP层,单尺度在牺牲少量精度的情况下增大了速度。
3. 提出训练方式为:将一张图片的proposals作为一批进行学习,坐标直接映射到conv5上,相当于一个batch训练一张图片。
3. Faster—RCNN

1. 提出RPN区域建议网络提取候选框:图像经过backbone提取到特征层后,一方面被送入RPN区域建议网络中,RPN构成为3*3的卷积后接两个1*1卷积,一路1*1卷积通道为18,可以分解为2*9,2表示该区域是否包含目标,9表示先验框的数量为9;另一路1*1卷积通道为36,可以分解为4*9,4表示每个先验框的四个属性的变化情况,9表示先验框的数量为9。
2. 对所有先验框进行调整,对置信度较低的框进行初步滤除,在进行非极大值抑制,在进一步筛选得到建议框。
3. 对所有建议框进行ROIpooling使得所有建议框尺寸一致,再送入都后续分类和回归网络。
单阶段:
单阶段网络没有proposal过程,其代表为SSD和YOLO系列。
1. SSD
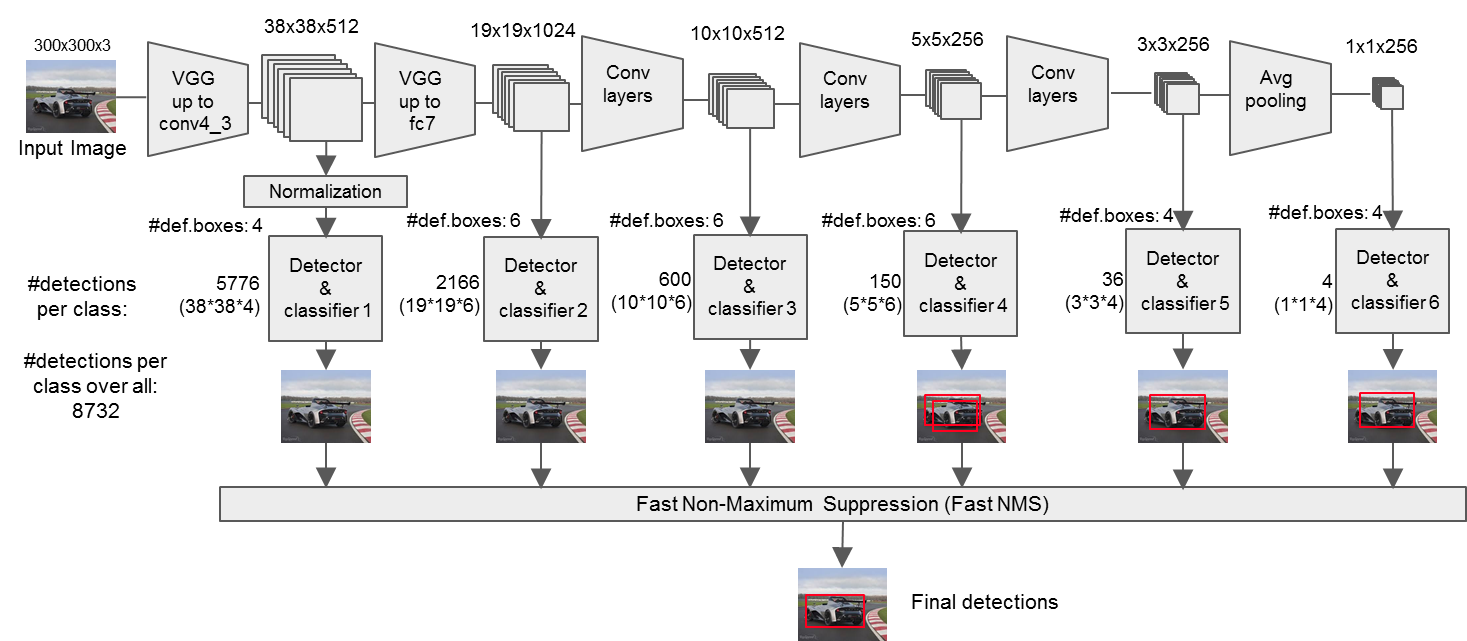
可以看到特征提取网络将特征图形状变成了38*38,19*19,10*10,5*5,3*3,1*1,事实上相当于将图像分割成了对应的网格,其中网格数较多的用来检测小目标,网格数较少的用来检测大目标,物体中心落在哪个网格上就由该网格来负责该物体的检测:

每个网格都有若干个先验框,在ssd中,尺寸不同,每个网格的先验框个数不同。通过训练这些先验框的调整参数,得到最终的检测结果。
对于六个有效特征层提取到的每一个特征,我们需要对其进行两个操作:
1. 进行num_anchors*4的卷积,目的是获得先验框的调整参数;
2. 进行num_anchors*num_cls的卷积,用于得到种类;
采用了FPN。
2. YOLO系列
yolov1:
yolov1发布比ssd早,ssd思想与yolov1差不多,但是用了FPN特征金字塔,利用了多尺度的特征层,而yolov1只用了单尺度。
yolov2:
解决yolov1定位准确率的问题,主要是用了大量的tricks提升准确率。
yolov3:
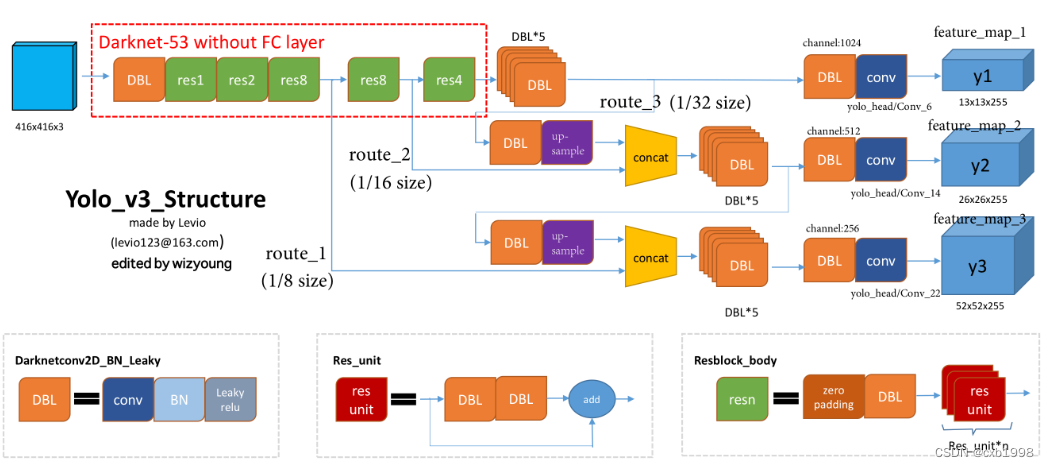
yolov3相对前两版改动较大,将darknet19扩展成darknet53,引入了残差块加深网络同时保留特征,并且采用了多尺度,引出了三个有效特征层进行融合。
yolov5:
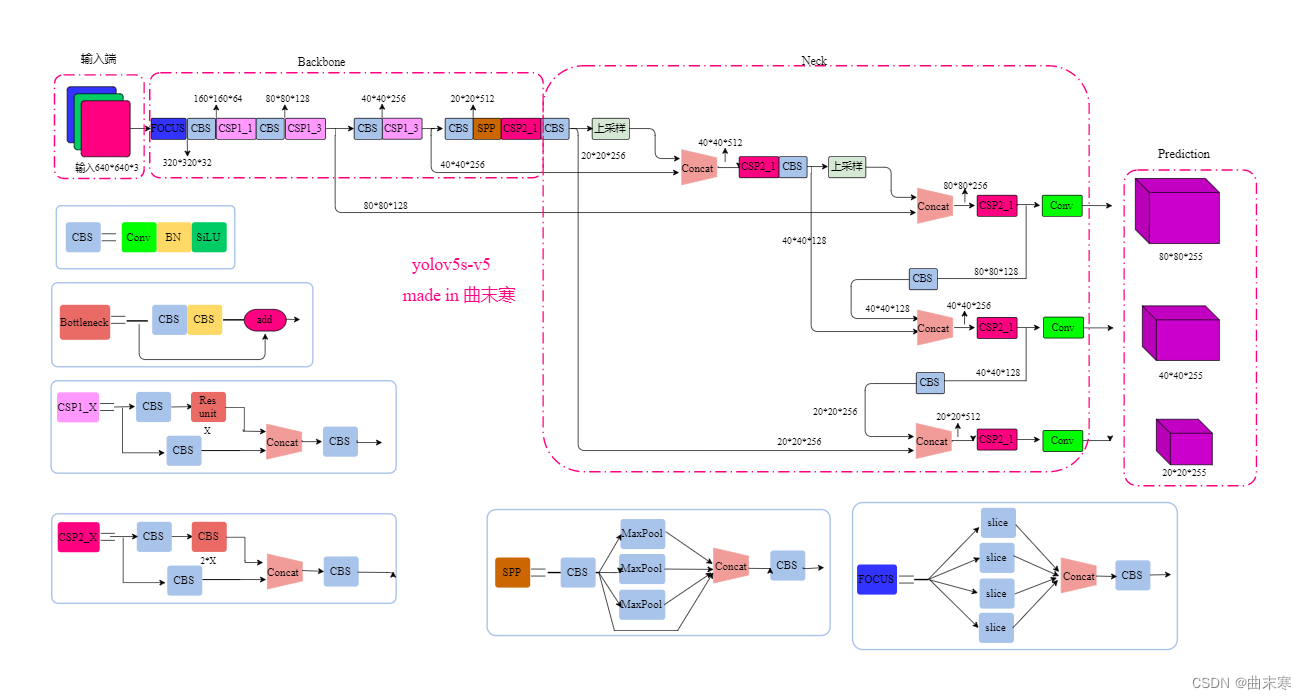
结构差异不大,增加了focus层并引入了SPP结构。
focus就是切片操作,将高分辨图拆成若干个低分辨图在进行拼接,减小图像尺寸的同时保留特征信息:

yolox:
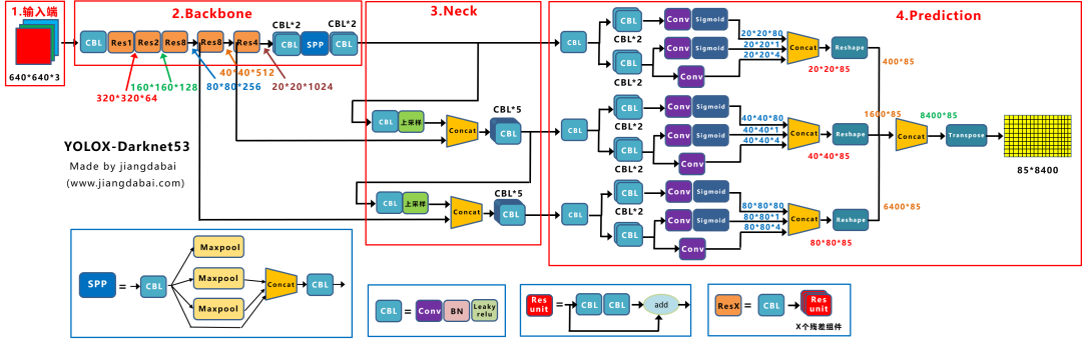
主要是prediction的改变:
1. 解耦头Decoupled Head
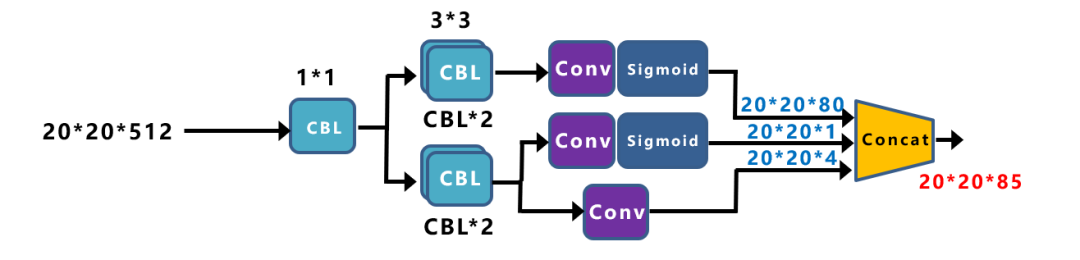
就是将检测头解耦,将种类,置信度以及位置回归分开卷积再合并,实验发现这样不仅增加了map收敛速度也提升了,再讲concat后的20*20*85 reshape成400*85,同理将另外两个尺度相同处理得到1600*85以及600*85,最后再concat成8400*85。
2. Anchor Free
前几版yolo用的都是Anchor Based,即用锚框与真实标注进行比对来减小损失函数调整锚框。

注意到w和h的预测不再和Anchor的长宽相乘,与Anchor无关。
3. 正负样本匹配SimOTA
将正负样本匹配转化成最优传输问题。

cost只计算GTbox或者固定中心区域的样本块anchor point。















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









