







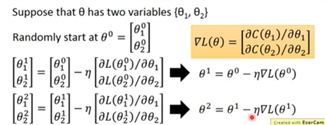
复习:
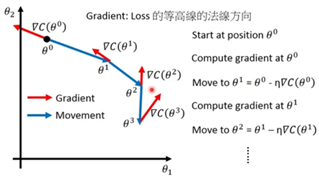
Tip1:小心调整learning rate,有必要将learning rate与loss function的图画出来
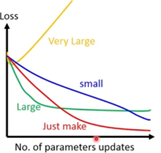
Learning rate的调整
由于初始位置距离梯度为0的地方比较远,所以通常情况下,随着数据更新,learning rate越来越小,我们就可以设置r(t)=r/sqrt(1+t).
但是最好的情况是不同参数有不同的learning rate。
Tip2 不同的梯度下降法
Adagrad
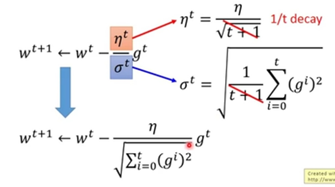
gt是loss function对w的偏导。
思考:这里的gt和下面的分母是否矛盾,因为一个使跨度大,一个使跨度小?

只考虑一个参数的情况:算出来的微分越大,就离原点越远,最好的步伐是跟微分的大小刚好成正比。
Stochastic gradient Descent(随机梯度下降)
相比于普通的梯度下降,随机梯度下降update for each example

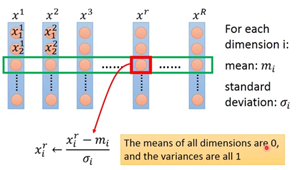
Tip3 Feature scaling
假如y=b+w1x1+w2x2
使不同的feature有同样的scaling
目的:使得改变w1和改变w2时,w1和w2对y的影响差距不要太大
做法:
梯度下降法缺点:
- 容易卡在偏导为0和local minima处
- 在偏导接近于0处运行缓慢















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









