







一、数据分析步骤
1、提出问题——明确数据分析目的
2、理解数据——理解数据列名的意义
3、数据清洗——统一格式内容
4、构建模型——思考用什么样的表现形式把数据呈现出来
5、数据可视化——把数据转化成图
二、提出问题
首先要明确这次数据分析的目的是什么?也就是为了解决什么问题?(提出的问题要能用很明确的指标和数字来衡量,切勿模棱两可)
提出问题:
1、在哪些城市找到数据分析师工作的机会比较大?
2、数据分析师的薪水如何?
3、根据工作经验的不同,薪酬是怎样变化的?
三、理解数据
也就是理解表格中的各个字段表示的什么意思
![]() 城市: 用于比较不同城市对数据分析师的需求如何
城市: 用于比较不同城市对数据分析师的需求如何
职位所属:分析以后的工作岗位
职位ID:表示职位的唯一表示,也就是每一行数据的唯一标识------用于去掉重复ID
薪水:比较不同城市、和所属领域的薪水区别
工作年限:从时间轴上对比薪资涨幅
四、数据清洗
数据清洗即数据预处理,目的是去掉无效、重复数据,以取得符合我们要求的数据。
数据清洗的基本步骤:

1、选择子集
只选择对数据分析有意义的字段,无意义的字段选择隐藏,即隐藏不需要分析的列(尽量不删,保证数据的完整性)。这里隐藏公司ID和公司全名,保留职位ID和公司简称。

2、列名重命名
将不合适的列名更改为我们容易理解的形式。
3、删除重复值
对重复数据进行删除,这里我们对【职场ID】列进行删除重复值处理:
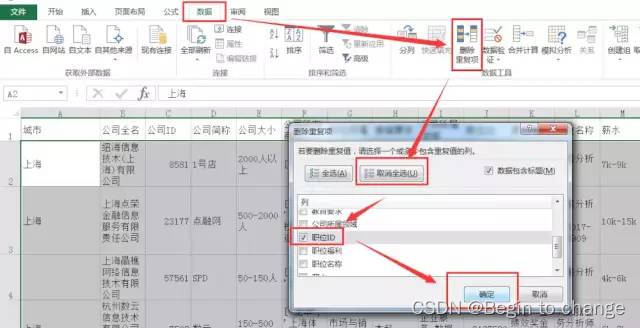
4、缺失值处理
先检查数据是否存在缺失值,先查看完整数据列的计数:

再选择其他列查看是否缺失数据:

可以看出【城市】这一列缺失2条数据。
一般对缺失值的处理有4种方法,根据情况灵活使用:
① 通过人工手动补全(缺失值较少,并且可以根据其他信息确定该值)
② 删除缺失的数据(无法判断该位置填写何值,或者删除的数据对分析无大的影响
③ 用平均值代替缺失值
④ 用统计模型计算出的值去代替缺失值
这里对【城市】这一列的处理
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









