




 本文详细介绍了使用卷积神经网络(CNN)进行图像分类的实际应用,以猫狗图片分类为例,从数据准备到模型构建,再到训练和评估,全程解析CNN的工作流程。展示了如何通过Keras库实现CNN,并达到训练集100%准确率,但测试集准确率仅为75%,揭示了过拟合的问题。
本文详细介绍了使用卷积神经网络(CNN)进行图像分类的实际应用,以猫狗图片分类为例,从数据准备到模型构建,再到训练和评估,全程解析CNN的工作流程。展示了如何通过Keras库实现CNN,并达到训练集100%准确率,但测试集准确率仅为75%,揭示了过拟合的问题。
一、卷积神经网络
-
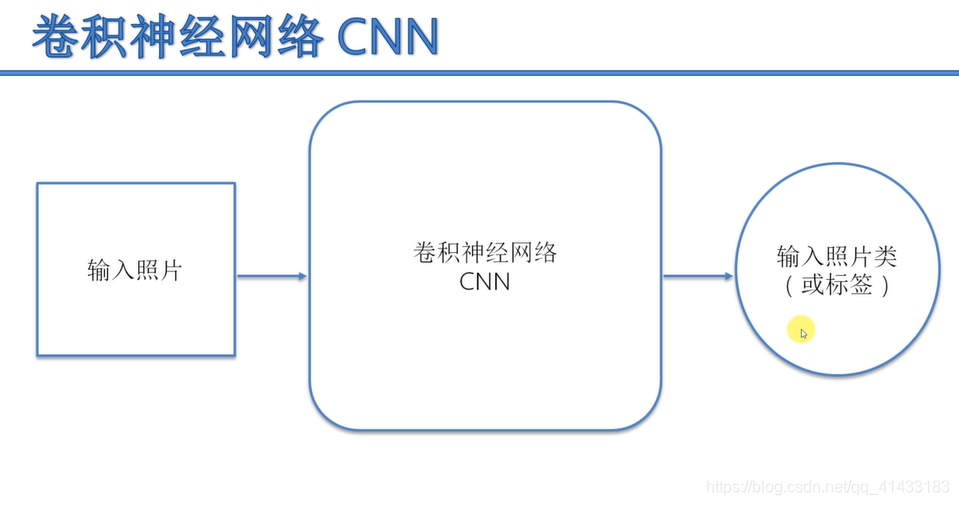
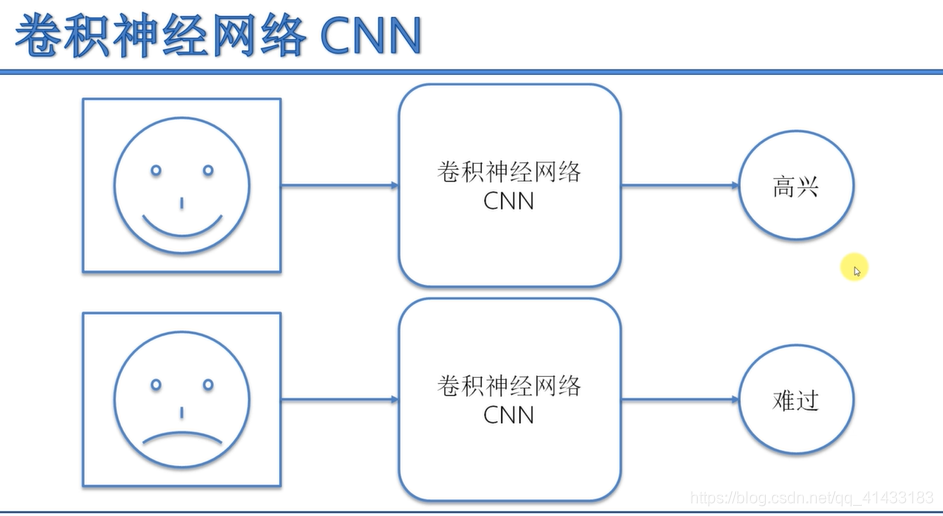
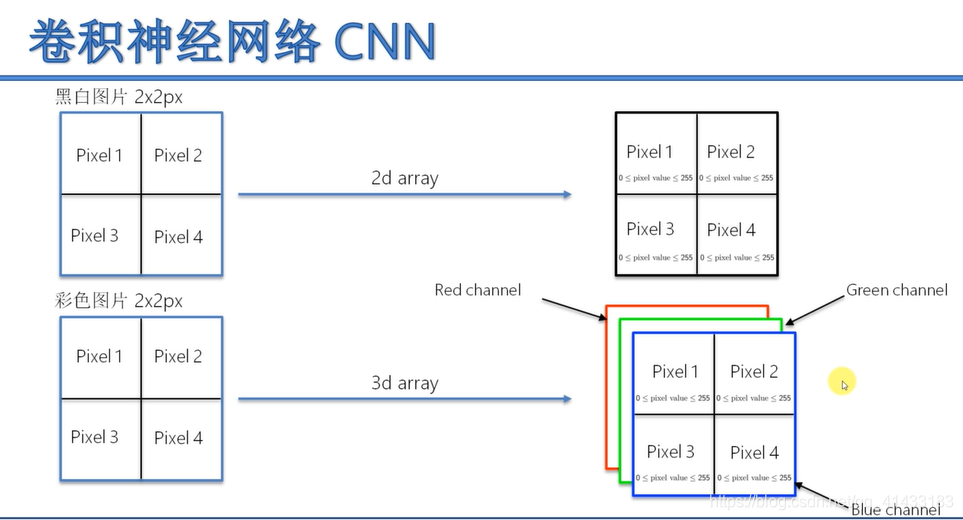
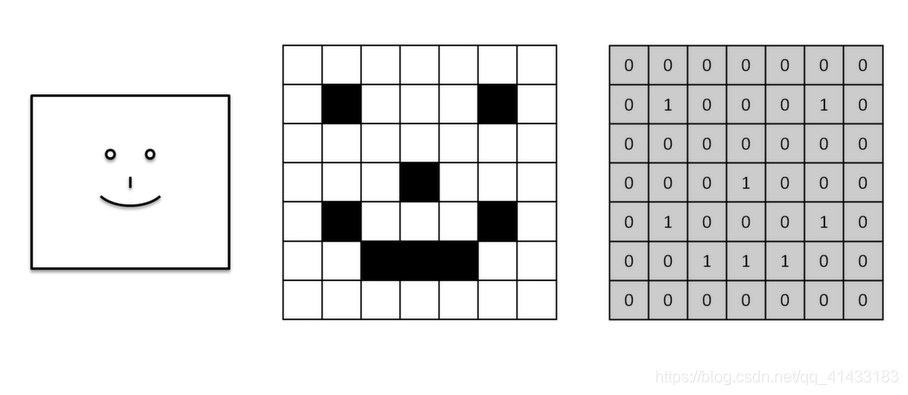
卷积神经网络介绍

学习资料


-
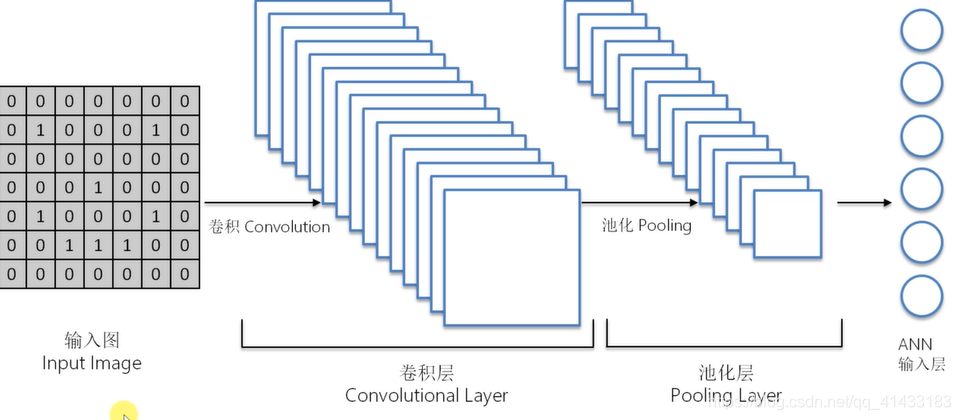
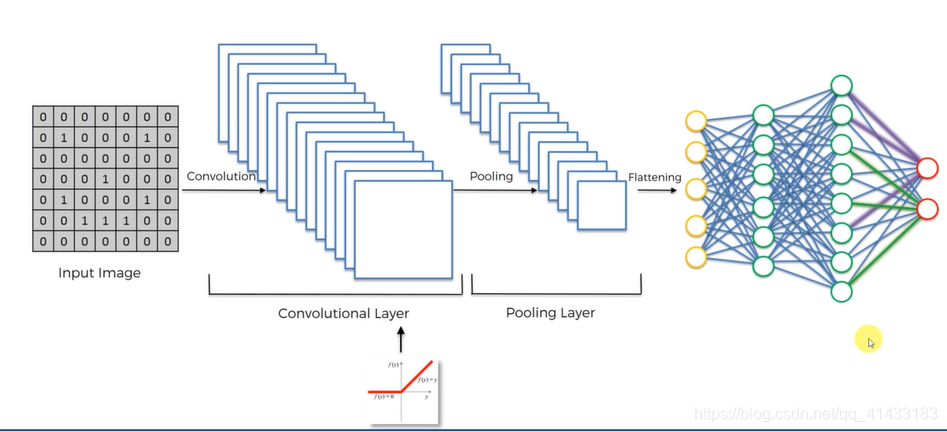
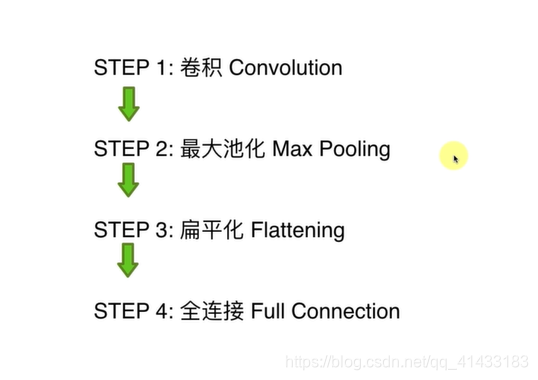
卷积神经网络流程分解
(1)卷积:

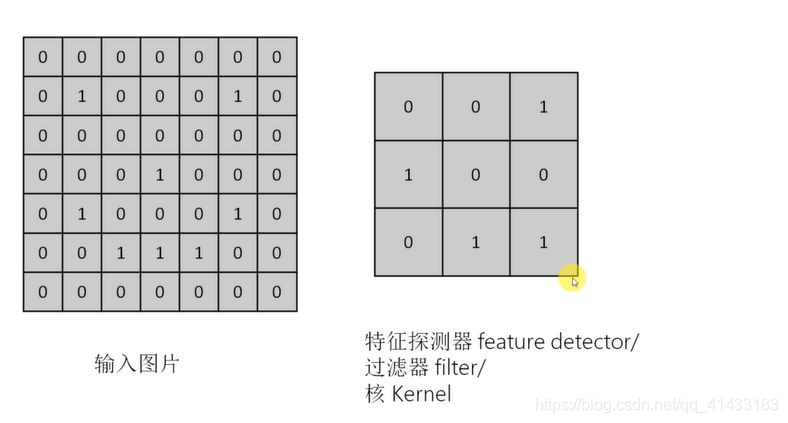
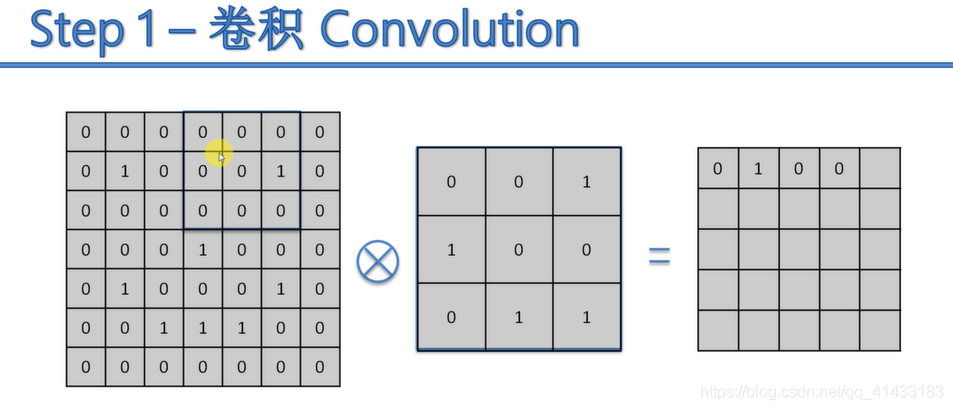
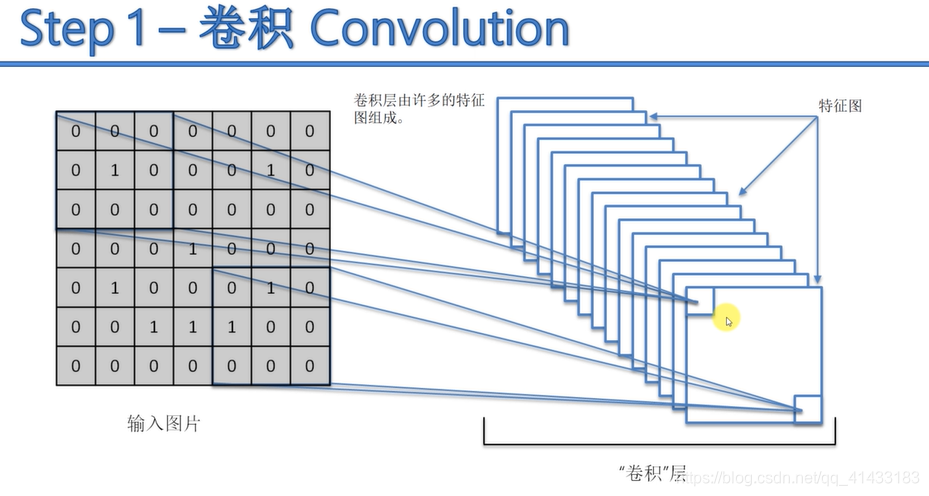
卷积后的几种照片展示图:
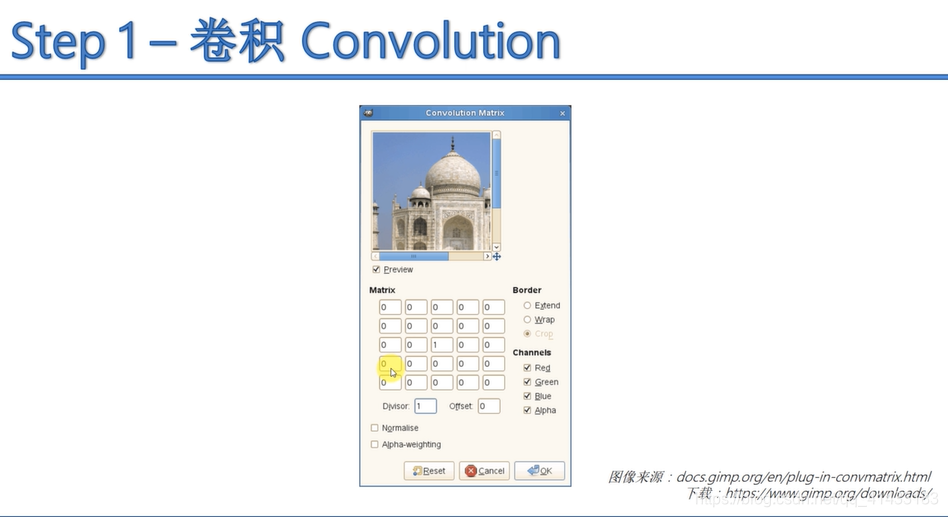



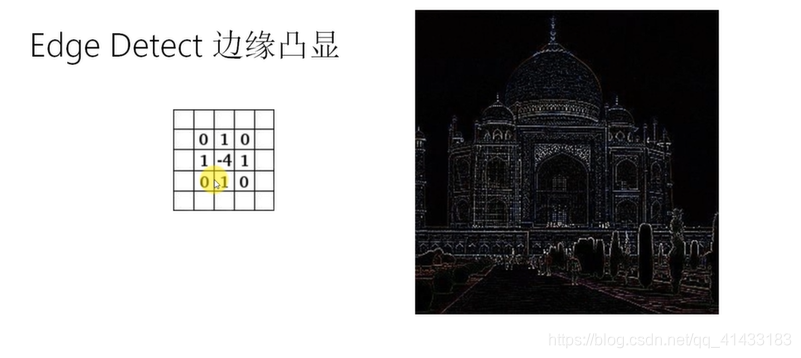

(2)最大池化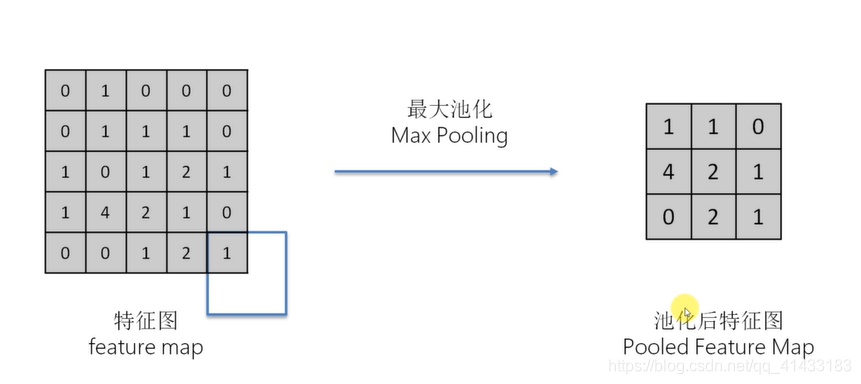
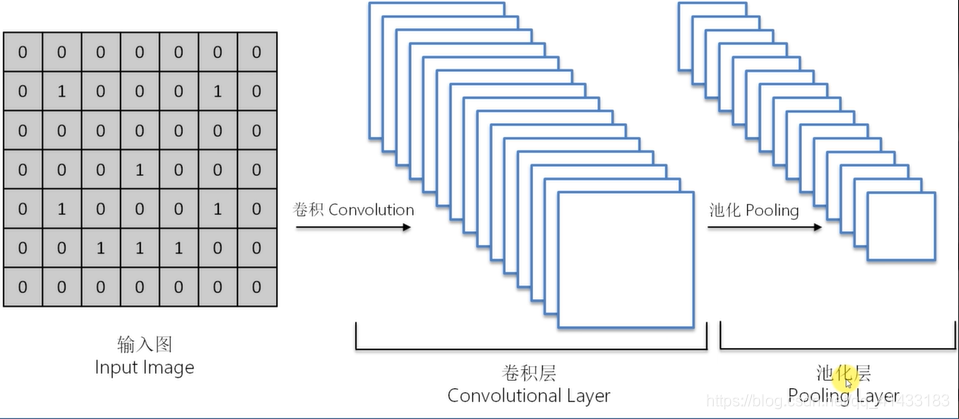
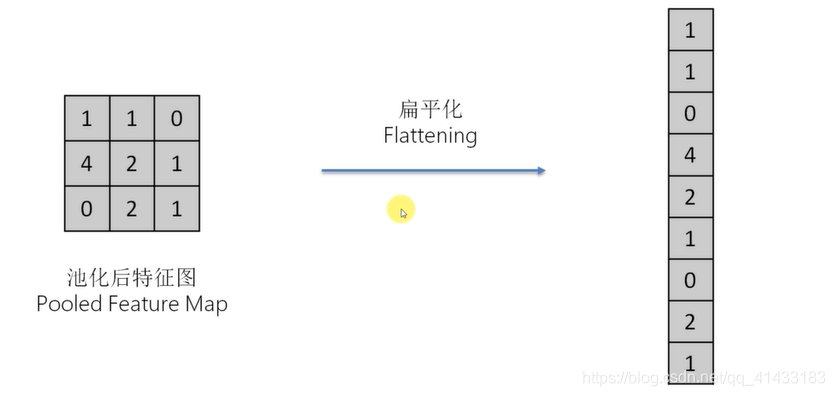
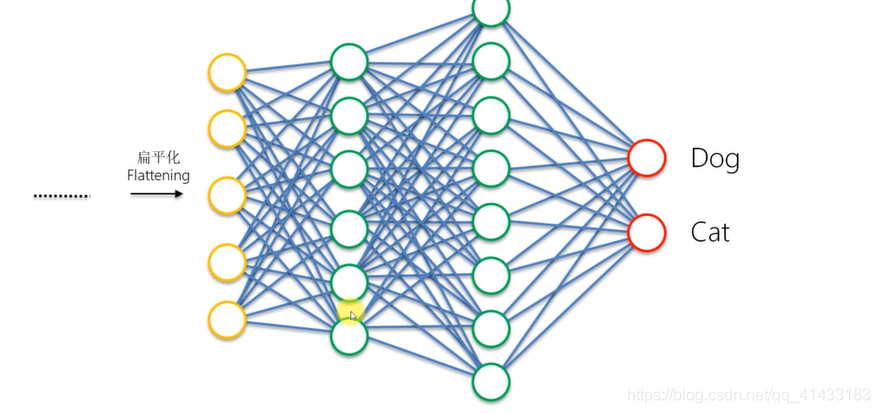
(3)扁平化
(4)全连接层
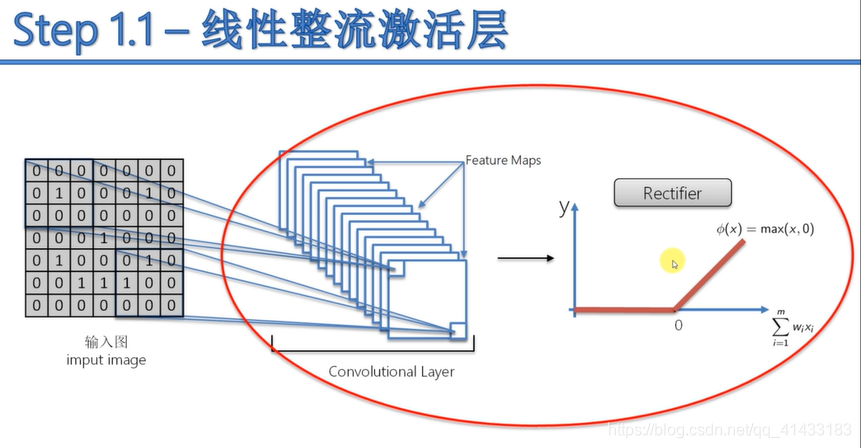
-
线性整流激活层



线性整流层资料
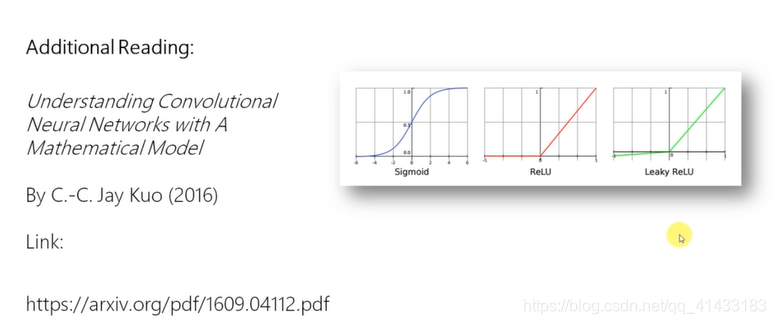
-
总结
-
代码实现
数据集:
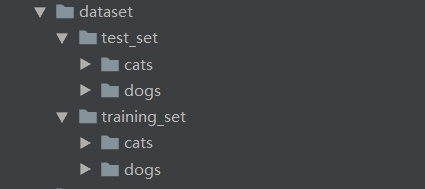
测试集和训练集中是包含小猫,小狗的照片,训练集中小猫小狗图片各4000张,测试集中小猫小狗图片各1000张步骤:
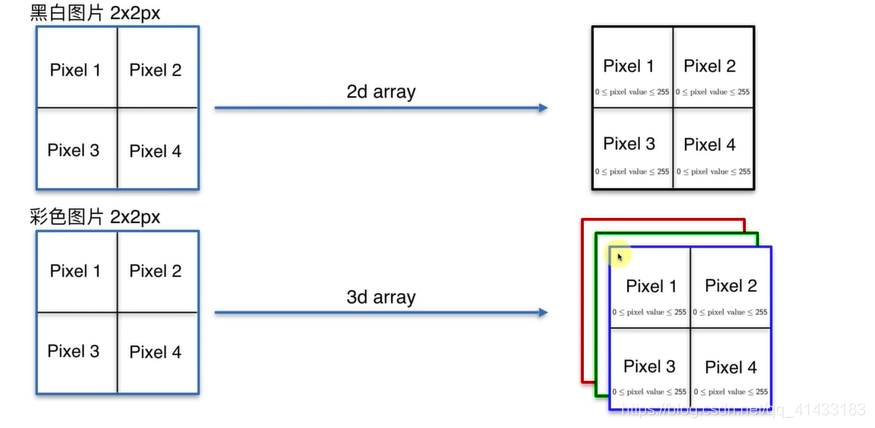
图片转化
代码:from keras.preprocessing.image import ImageDataGenerator # 对图片进行预处理 # 初始化卷积神经网络 classifier = Sequential() # 添加卷积层 classifier.add(Convolution2D(filters=32, kernel_size=(3, 3), activation="relu", input_shape=(64, 64, 3))) # filters:是用多少个特征探测器, kernel_size: 特征探测器用一个多少乘多少的矩阵, activation: 激活函数为线性整流函数,input_shape: (图片长,图片宽,图片三原色) # 添加最大池化层(缩减特征图的大小,降维操作) classifier.add(MaxPooling2D(pool_size=(2, 2))) # pool_size最大池化的窗口大小 # #######添加第二个卷积层######## classifier.add(Convolution2D(filters=32, kernel_size=(3, 3), activation="relu")) # filters:是用多少个特征探测器, kernel_size: 特征探测器用一个多少乘多少的矩阵, activation: 激活函数为线性整流函数,input_shape: (图片长,图片宽,图片三原色) classifier.add(MaxPooling2D(pool_size=(2, 2))) # pool_size最大池化的窗口大小 # 扁平化 classifier.add(Flatten()) # 全连接层(加一层人工神经网络) classifier.add(Dense(units=128, activation="relu")) # 输入层,隐藏层 classifier.add(Dense(units=1, activation="sigmoid")) # 输出层,因为输出结果为一个的概率,所以选激活函数为sigmoid # 编译人工神经网络其实就是配置模型参数(优化器<优化算法>, loss function(损失函数),metrics(性能评估器)) classifier.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"]) # 拟合神经网络 train_datagen = ImageDataGenerator( rescale=1./225, # 将图片每个像素点乘 1/255 shear_range=0.2, # 将图像素点左右平移0.2成平行四边形 zoom_range=0.2, # 选取0.2个大小 horizontal_flip=True # 图片进行反转 ) # 训练集模型 test_datagen = ImageDataGenerator(rescale=1./225) # 测试集模型 training_set = test_datagen.flow_from_directory( 'dataset/training_set', # 训练集图片存放路径 target_size=(64, 64), # 输入图片的大小 batch_size=32, # 每批图片处理的数量 class_mode="binary" # 因为次测试只有猫和狗两个类,所以采用"binary", 若有多个类的化选择"categorica" ) test_set = test_datagen.flow_from_directory( 'dataset/test_set', # 测试集图片存放路径 target_size=(64, 64), # 输入图片的大小 batch_size=32, # 每批图片处理的数量 class_mode="binary" # 因为次测试只有猫和狗两个类,所以采用"binary", 若有多个类的化选择"categorica" ) print("开始训练了。。。。。。") classifier.fit_generator( generator=training_set, # 拟合数据 steps_per_epoch=250, # 做一期训练的时候总共有多少部 为: 训练集数据个数 / 每批图片处理的数量,若输入更大的数量多出来的图片是由图片生成器产生的 epochs=25, # 训练的期数 validation_data=test_set, # 测试集数据 validation_steps=62.5 # 和steps_per_epoch类似为: 测试集数据个数 / 每批图片处理的数量 )输出结果:
... 235/250 [===========================>..] - ETA: 3s - loss: 0.0015 - accuracy: 1.0000 236/250 [===========================>..] - ETA: 2s - loss: 0.0015 - accuracy: 1.0000 237/250 [===========================>..] - ETA: 2s - loss: 0.0015 - accuracy: 1.0000 238/250 [===========================>..] - ETA: 2s - loss: 0.0015 - accuracy: 1.0000 239/250 [===========================>..] - ETA: 2s - loss: 0.0015 - accuracy: 1.0000 240/250 [===========================>..] - ETA: 2s - loss: 0.0015 - accuracy: 1.0000 241/250 [===========================>..] - ETA: 1s - loss: 0.0015 - accuracy: 1.0000 242/250 [============================>.] - ETA: 1s - loss: 0.0015 - accuracy: 1.0000 243/250 [============================>.] - ETA: 1s - loss: 0.0015 - accuracy: 1.0000 244/250 [============================>.] - ETA: 1s - loss: 0.0015 - accuracy: 1.0000 245/250 [============================>.] - ETA: 1s - loss: 0.0015 - accuracy: 1.0000 246/250 [============================>.] - ETA: 0s - loss: 0.0015 - accuracy: 1.0000 247/250 [============================>.] - ETA: 0s - loss: 0.0015 - accuracy: 1.0000 248/250 [============================>.] - ETA: 0s - loss: 0.0015 - accuracy: 1.0000 249/250 [============================>.] - ETA: 0s - loss: 0.0015 - accuracy: 1.0000 250/250 [==============================] - 58s 232ms/step - loss: 0.0015 - accuracy: 1.0000 - val_loss: 0.0221 - val_accuracy: 0.7500 此结果中训练集准确率达100%,测试集准确率为75%,可见训练集对数据过渡拟合,测试、训练结果相差太大,对于图像处理来说,这结果不是很好

















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









