







使用python调用pytorch中的clip模型时报错:AttributeError: partially initialized module ‘clip’ has no attribute ‘load’ (most likely due to a circular import)
现象
在使用pyton调用pytorch中的clip模型获取图片的关键词时,根据官方文档的代码描述,代码内容如下
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("C:/Users/HLY/Desktop/3.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
根据官方文档安装pytorch,clip等版本后,报错,报错信息如下
Traceback (most recent call last):
File "D:\WorkTest\pythonProject\resnetTest\clip.py", line 2, in <module>
import clip
File "D:\WorkTest\pythonProject\resnetTest\clip.py", line 6, in <module>
model, preprocess = clip.load("ViT-B/32", device=device)
^^^^^^^^^
AttributeError: partially initialized module 'clip' has no attribute 'load' (most likely due to a circular import)
解决方案
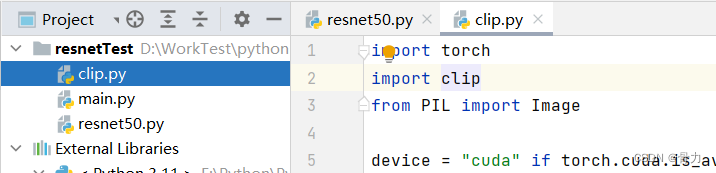
一、查看项目中是否有为clip名的文件
如果项目中有clip.py名文件,import clip会默认为引入自己,则会出现上述所说循环导入的问题。
将clip.py文件更名即可
二、查看clip是否安装成功
如果上述方案没有解决,查看是否为clip安装的问题
1、先调用如下命令,卸载已安装的clip
pip uninstall clip
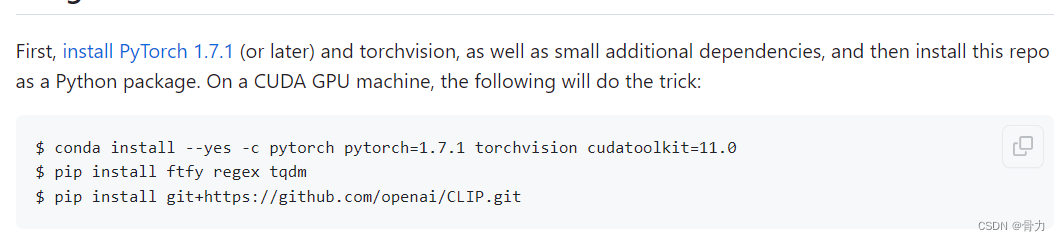
2、再根据官方文档的介绍,重新安装clip
3、如果重新安装后也无效,尝试卸载后以如下命令
pip install openai-clip
如有其他疑问欢迎留言
















 9273
9273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









