







Traffic Flow Prediction via Spatial Temporal Graph Neural
参考材料
-
图卷积基本知识:https://blog.csdn.net/qq_41727666/article/details/84622965
-
文中所用图卷积方法:https://blog.csdn.net/qq_41727666/article/details/84640549
1. ABSTRACT
- 传统方法在时间和空间的依赖性捕捉上有明显的不足
- 本文提出一个新的时空图神经网络,它可以全面的捕捉时空关系,该网络提供一个可学习的位置注意力机制
- 提出一个顺序组件,该组件可以利用局部和全局的依赖性
2. INTRODUCTION
2.1 交通预测问题存在的难题
- 交通预测依赖于车辆流量在时间维度上的波动性和不确定性:车流量在很长一段时间内通常是周期性的,但是短期存在很大不确定性。
- 道路和车辆在空间维度上的复杂关系也起着重要的作用
2.2 现有工作
-
传统的基于知识驱动的方法
-
主要方法:排队理论,行为模拟器和机器学习的方法
-
具体例子:向量自动回归(VAR),支持向量回归(SVR)
-
不足 :这些方法基于理想的平稳假设,这在复杂的交通中通常不成立
关于时空数据的平稳性:时空数据的方差和均值不随时间改变。通俗来讲就是时空数据在一定周期内是有规律的。
-
-
基于RNN的方法
- 主要方法:基于RNNs的一些改进网络,主要是基于LSTM和GRU模块
- 具体例子:PredRNN,PredRNN++,MIM(最近还有将注意力机制引入的方法论文阅读量还不够以后补充)
- 不足 :将不同路段的信息视为独立的个体,不能很好的利用交通数据中的空间信息
-
结合图神经网络和循环神经网络
- 具体例子:T-GCN,DCRNN,GaAN
- 不足 :
- 这些方法通过道路网络的边缘来转换和聚集信息。然而,一条道路上的交通对其他道路的影响是动态的,不能简单地通过它们之间的静态空间邻近性来建模。
- 这些模型采用循环神经网络捕捉序列信息使时,信息经过很长一段路径的传播会丢失
2.3 本文主要贡献
- 提出了一个新的图形神经网络层与位置方向的关注机制,以更好地聚集信息的交通流量从邻近的道路
- 结合了一个递归网络和一个转换器层来捕捉局部和全局时间相关性
3. 问题陈述
给定交通网络G=(V, E)和历史交通信息y=(Y1,Y2,…,Yn),我们的目的是建立一个模型f,可以将一个长度为T的新序列X=(X1,…,XT)作为输入,预测未来T’个时间步的交通信息Xpred=(XT+1,…,XT+T’)。
4.方法
整个网络框架大致由三部分组成:
- 空间图神经网络层:捕捉空间依赖
- GRU layer:捕捉时间依赖
- transformer layer:捕捉长期时间依赖
4.1 空间依赖性建模方法
(1)图卷积操作运算
提出于论文:Semi-Supervised Classification with Graph Convolutional Networks
主要思想:输入 X i n ∈ R N × d i n X_{in} \in \R^{N\times d_{in}} Xin∈RN×din经过GNN模型将数据转换为 X o u t ∈ R N × d o u t X_{out} \in \R^{N\times d_{out}} Xout∈RN×dout
转换公式: X o u t = σ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 X i n W ) X_{out}=\sigma(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}X_{in}W) Xout=σ(D~−1/2A~D~−1/2XinW)其中 A ~ \tilde{A} A~和 D ~ \tilde{D} D~分别是加上自边的临界矩阵和加权度量矩阵,其中在图神经网络中引入了注意力机制以学习邻居节点对于中心节点的贡献度,但是稍微不同于图注意力神经网络GAT,在这里的注意力计算的所需参数更少。注意力计算的公式如下所示:
其中 ϕ \phi ϕ代表一种激活函数,pi和pj代表不同节点i和j的潜空间特征。Score( )是一种评分函数,在本文中没有像GAT中使用参数化的方法计算评分函数,而是直接用pi和pj的点积区去计算。在这里仍然采用了与GAT中相同的mask机制用计算得到的权重值替换原邻接矩阵中的非零元素。
4.2 时间依赖性
(1)使用GRU捕捉局部时间依赖
GRU的作用是捕捉每个空间节点在时间维度上的短时依赖,在这里每个GRU单元的输入Xt-1和隐藏层输出Ht-1都要经过S-GNN的计算:
X
t
~
=
f
a
(
A
,
X
t
)
\tilde{X_t}=f_a(A,X_t)
Xt~=fa(A,Xt)
H t − 1 ~ = f a ( A , H t − 1 ) \tilde{H_{t-1}}=fa(A,H_{t-1}) Ht−1~=fa(A,Ht−1)
文中GRU公式与普通GRU公式区别不大,但是输入和隐藏状态都需要先经过S-GNN用以捕捉空间依赖
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G4VNurMN-1622122912512)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210524194007638.png)]
(2)使用Transform捕捉长期空间依赖
Transformer是一种适合学习长序列的神经网络模型,弥补了RNN系列模型在误差积累,梯度爆炸,长时记忆等方面的短板,其作用是捕捉每个空间节点在时间维度上的长时依赖。这里的Transformer层与一般的Transformer基本结构别无二致,分别由位置编码机制,多头注意力层和前馈输出层组成。Transformer层的输入为GRU层中每个循环单元的输出。
Transformer中最核心的还是自注意力机制。本文中的单个自注意力计算与原始的自注意力计算公式一致,分别为查询向量Q、键向量K和值向量V组成:
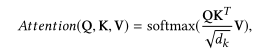
查询向量Q、键向量K和值向量V分别由一个节点特征进行映射得到:
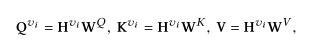
在Transform的后面假设了一个Prediction层,一个普通的前馈神经网络














 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









