






一、梯度产生和更新
import torch
import torch.optim as optim
from torch.autograd import Variable
x = torch.FloatTensor([2,3,4,5])
x = Variable(x,requires_grad=True)
y = x**2
opt = optim.SGD([x],lr=0.1,weight_decay=0)
y.backward(torch.ones(4))
opt.step()
y
=
x
2
y=x^2
y=x2
x的梯度公式为
d
y
d
x
=
2
x
\frac{dy}{dx}=2x
dxdy=2x,因为
x
=
[
2
,
3
,
4
,
5
]
x=[2,3,4,5]
x=[2,3,4,5],所以x的梯度
g
r
a
d
=
[
4
,
6
,
8
,
5
]
grad=[4,6,8,5]
grad=[4,6,8,5],那么x在优化器为SGD的情况下,进行梯度更新的公式为
x
n
e
w
=
x
−
l
r
∗
g
r
a
d
=
[
2
,
3
,
4
,
5
]
−
0.1
∗
[
4
,
6
,
8
,
10
]
=
[
1.6
,
2.4
,
3.2
,
4.0
]
x_{new}=x-lr*grad=[2,3,4,5]-0.1*[4,6,8,10]=[1.6,2.4,3.2,4.0]
xnew=x−lr∗grad=[2,3,4,5]−0.1∗[4,6,8,10]=[1.6,2.4,3.2,4.0]
二、代码执行情况
- 前向运算
x = torch.FloatTensor([2,3,4,5])
x = Variable(x,requires_grad=True)
y = x**2
经过前向运算后,
x
=
[
2
,
3
,
4
,
5
]
x=[2,3,4,5]
x=[2,3,4,5],
y
=
[
4
,
9
,
16
,
25
]
y=[4,9,16,25]
y=[4,9,16,25]
2. 计算梯度
y.backward(torch.ones(4))
backward计算路径上张量的梯度,执行完这一步后,得到x.grad
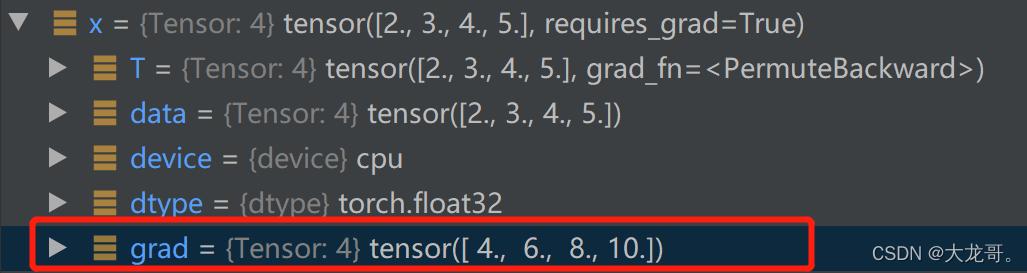
3. 权重更新
opt.step()
该步骤的目的是利用backward计算得到的梯度,优化路径上的张量的权重。SGD优化公式为
x
n
e
w
=
x
−
l
r
∗
g
r
a
d
x_{new}=x-lr*grad
xnew=x−lr∗grad
其中lr为学习率,grad为上一步计算得到的梯度,更新后的梯度如下

三、总结:
- 前向传播之后使用backward进行梯度计算,接着使用opt.step进行权重更新。
- 不同的优化器有不同的更新公式,在这里为了简化理解并未涉及weight_decay的影响。
- 上面x的权重全部更新,没有体现SGD的随机性。目前主流框架中所谓的SGD实际上都是Mini-batch Gradient Descent (MBGD,亦成为SGD)。对于含有N个训练样本的数据集,每次参数更新,仅依据一部分数据计算梯度。小批量梯度下降法既保证了训练速度,也保证了最后收敛的准确率。优化器SGD的内部只是根据梯度进行更新原有权重,并不能体现随机性,真正体现随机性的是我们传入的batch_data都是随机产生的。(第3问答案摘自https://ask.csdn.net/questions/7398069)
for epoch in range(N):
for batch in data_loader: # <== 随机获取一部分数据是由你构造的data_loader实现的
optimizer.zero_grad()
output = model(batch) # <== 此处输入即为随机的一部分数据














 647
647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









