







1、Elasticsearch简介
ElasticSearch:智能搜索,分布式的搜索引擎
是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana。
E:EalsticSearch 搜索和分析的功能
L:Logstach 搜集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统
K:Kibana 数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台
假如一个分布式系统有 1000 台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,是不是很麻烦;如果日志接入了 ELK 系统就不一样,比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入 ELK 系统中,我们直接在 Kibana 就能看到日志情况;如果再接入一些实时计算模块,还能做实时报警功能;这都依赖ES强大的反向索引功能,这样我们根据关键字就能查询到关键的错误日志了。
1.1、搜索
- 百度,谷歌,必应。我们可以通过他们去搜索我们需要的东西。但是我们的搜索不只是包含这些,还有京东站内搜索啊。
- 互联网的搜索:电商网站。招聘网站。新闻网站。各种APP(百度外卖,美团等等)
- windows系统的搜索,OA软件,淘宝SSM网站,前后台的搜索功能
1.2、全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
1.3、倒排索引
以前是根据ID查内容,倒排索引之后是根据内容查ID,然后再拿着ID去查询出来真正需要的东西。
- 正排索引
- 优点:工作原理非常的简单。
- 缺点:检索效率太低,只能在一起简单的场景下使用。
正排索引也称为"前向索引",这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。他适合根据文档ID来查询对应的内容。但是在查询一个keyword在哪些文档里包含的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。

- 倒排索引
根据切分的关键词表去找含有这个关键词的文档ID
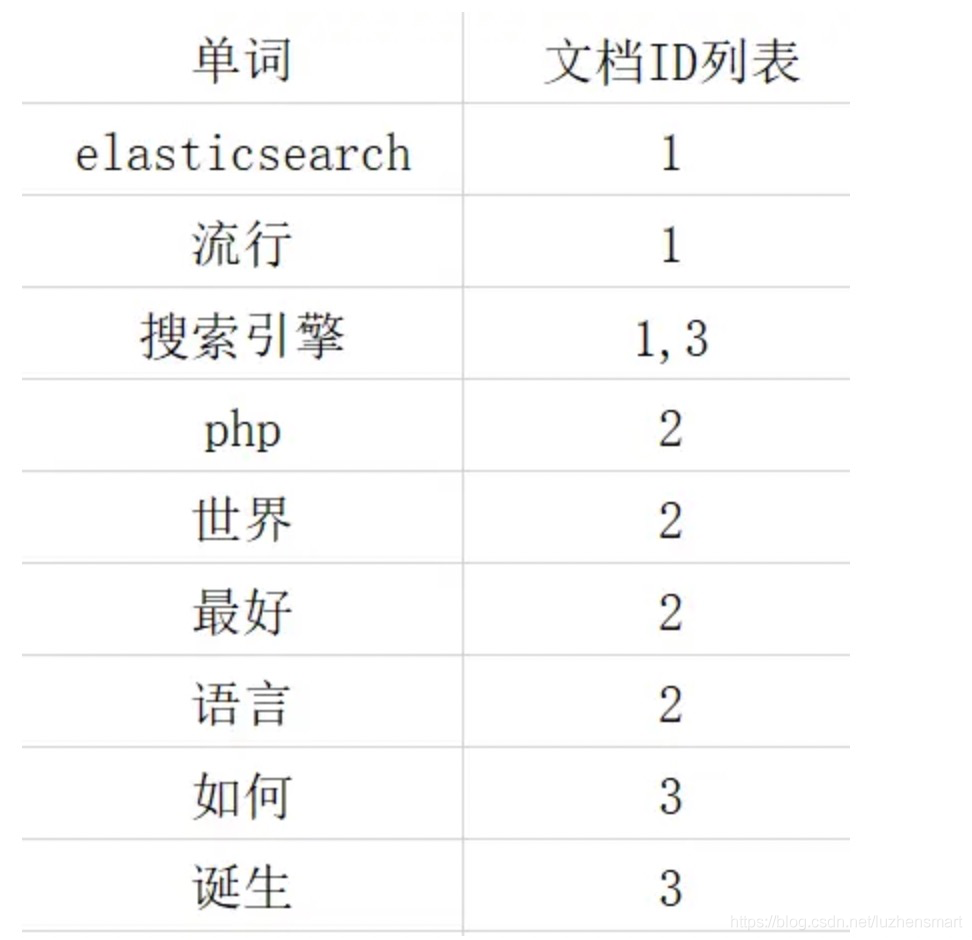
单词编号(Word ID):与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。
单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
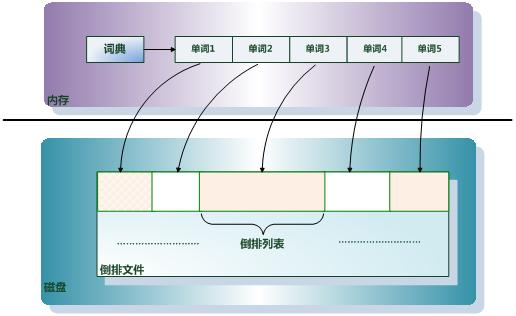
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
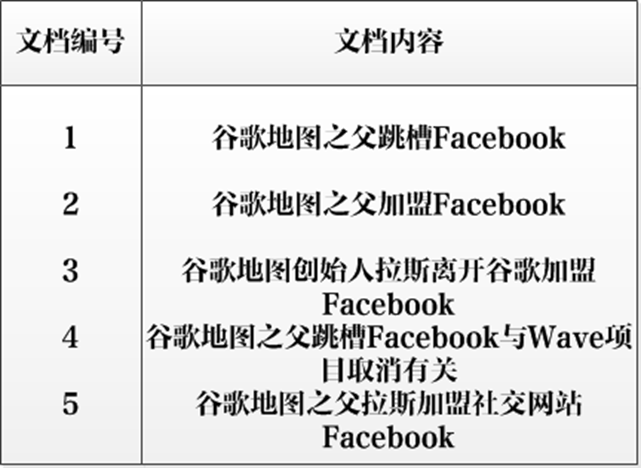
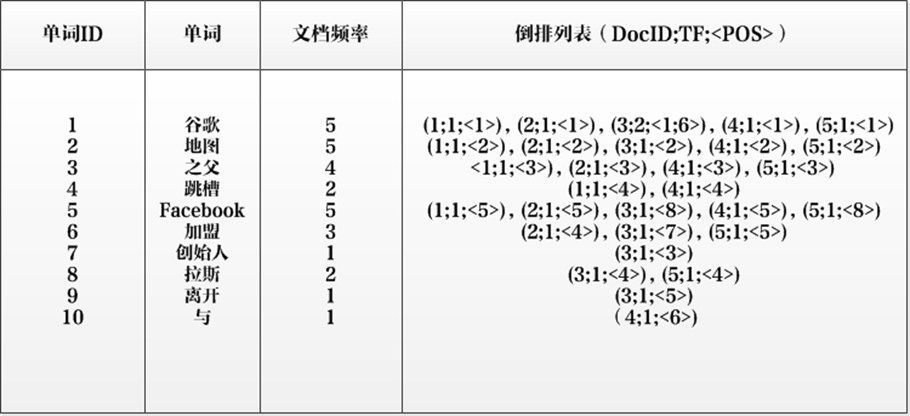
- 单词ID:记录每个单词的单词编号;
- 单词:对应的单词;
- 文档频率:代表文档集合中有多少个文档包含某个单词
- 倒排列表:包含单词ID及其他必要信息
- DocId:单词出现的文档id
- TF:单词在某个文档中出现的次数
- POS:单词在文档中出现的位置
- ES中文分词:IK中文分词器
安装IK插件
docker cp /home/kali/Desktop/elasticsearch-analysis-ik-6.3.2.zip es:/usr/share/elasticsearch/plugins/ik 复制指定版本的IK分词器到容器内目录下
解压压缩包
重启es容器IK分词器有两种分词模式
- k_max_word:会将文本做最细粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌」,会穷尽各种可能的组合
- ik_smart:会将文本做最粗粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」
1.4、ES的优点
- 分布式的功能
- 数据高可用,集群高可用
- API更简单
- API更高级。
- 支持的语言很多
- 支持PB级别的数据
- 完成搜索的功能和分析功能,基于Lucene,隐藏了Lucene的复杂性,提供简单的APIES的性能比HBase高,咱们的竞价引擎最后还是要存到ES中的。
搜索引擎原理
- 反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。
- 搜索引擎原理就是建立反向索引。
- Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎。
- Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行。
- Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份。
- Elasticsearch 一个典型应用就是 ELK 日志分析系统。
2、Elasticsearch核心概念
- index 索引(索引库)
我们为什么使用ES?因为想把数据存进去,然后再查询出来。
我们在使用Mysql或者Oracle的时候,为了区分数据,我们会建立不同的数据库,库下面还有表的。
其实ES功能就像一个关系型数据库,在这个数据库我们可以往里面添加数据,查询数据。
ES中的索引非传统索引的含义,ES中的索引是存放数据的地方,是ES中的一个概念词汇。
index类似于我们Mysql里面的一个数据库 create database user; 好比就是一个索引库
- type类型
类型是用来定义数据结构的
在每一个index下面,可以有一个或者多个type,好比数据库里面的一张表。
相当于表结构的描述,描述每个字段的类型。
- document:文档
文档就是最终的数据了,可以认为一个文档就是一条记录。
是ES里面最小的数据单元,就好比表里面的一条数据
- Field 字段
好比关系型数据库中列的概念,一个document有一个或者多个field组成。
- shard:分片
一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
kafka:为什么支持分布式的功能,因为里面是有topic,支持分区的概念。所以topic A可以存在不同的节点上面。就可以支持海量数据和高并发,提升性能和吞吐量
- replica:副本
一个分布式的集群,难免会有一台或者多台服务器宕机,如果我们没有副本这个概念。就会造成我们的shard发生故障,无法提供正常服务。
我们为了保证数据的安全,我们引入了replica的概念,跟hdfs里面的概念是一个意思。
可以保证我们数据的安全。
在ES集群中,我们一模一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)
当我们去查询数据的时候,我们数据是有备份的,它会同时发出命令让我们有数据的机器去查询结果,最后谁的查询结果快,我们就要谁的数据(这个不需要我们去控制,它内部就自己控制了)
3、Elasticsearch命令
- elasticsearch新增
curl -H "Content-Type: application/json" -XPUT 'http://192.168.187.201:9200/store/books/1?pretty' -d '{
"title": "Elasticsearch: The Definitive Guide",
"name" : {
"first" : "Zachary",
"last" : "Tong"
},
"publish_date":"2015-02-06",
"price":"49.99"
}'注:curl是linux下的http请求,-H "Content-Type: application/json"需要添加,否则会报错{"error":"Content-Type header [application/x-www-form-urlencoded] is not supported","status":406}
加"pretty"与不加"pretty"的区别就是返回结果工整与不工整的差别
- elasticSearch删除
curl -XDELETE 'http://hadoop1:9200/store/books/1?pretty'
-
elasticSearch更新
curl -H "Content-Type:application/json" -XPUT 'http://hadoop1:9200/store/books/1?pretty' -d '{
"title": "Elasticsearch: The Definitive Guide",
"name" : {
"first" : "Zachary",
"last" : "Tong"
},
"publish_date":"2016-02-06",
"price":"99.99"
}'- "q=*"表示匹配索引中所有的数据,一般默认只返回前10条数据
curl 'hadoop1:9200/bank/_search?q=*&pretty'
#等价于:
curl -H "Content-Type:applicatin/json" -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} }
}'-
匹配所有数据,但只返回1个
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {"match_all": {}},
"size": 1
}'注:如果size不指定,则默认返回10条数据。
-
返回从11到20的数据(索引下标从0开始)
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {“match_all”: {}},
"from": 10,
"size": 10
} -
匹配所有的索引中的数据,按照balance字段降序排序,并且返回前10条(如果不指定size,默认最多返回10条)
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {"match_all": {}},
"sort": {"balance":{"order": "desc"}}
}'-
返回特定的字段(account_number balance)
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {"match_all": {}},
"_source": ["account_number", "balance"]
}'-
返回account_humber为20的数据
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {"match": {"account_number":20}}
}'-
返回address中包含mill的所有数据
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {"match":{"address": "mill"}}
}'-
返回地址中包含mill或者lane的所有数据
curl -H "Content_Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
“query": {"match": {"address": "mill lane"}}
}'-
与第8不同,多匹配(match_phrase是短语匹配),返回地址中包含短语"mill lane"的所有数据
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {"match_phrase": {"address": "mill lane"}}
}'bool过滤查询,可以做组合过滤查询、嵌套查询等
filter:过滤
must:条件必须满足,相当于and
should:条件可以满足也可以不满足,相当于or
must_not:条件不需要满足,相当于not
- filter指定单个值
# SELECT * FROM books WHERE price = 35.99
# filtered 查询价格是35.99的
curl -H "Content-Type:application/json" -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{
"query" : {
"bool" : {
"must" : {
"match_all" : {}
},
"filter" : {
"term" : {
"price" : 35.99
}
}
}
}
}'- filter指定多个值
curl -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{
"query" : {
"bool" : {
"filter" : {
"terms" : {
"price" : [35.99, 99.99]
}
}
}
}
}'- must、should、must_not与term结合使用
curl -H "Content-Type:application/json" -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{
"query" : {
"bool" : {
"should" : [
{ "term" : {"price" : 35.99}},
{ "term" : {"price" : 99.99}}
],
"must_not" : {
"term" : {"publish_date" : "2016-06-06"}
}
}
}
}'- must、should、must_not与match结合使用
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {
"bool": {
"must_not": [
{"match": {"address": "mill"}},
{"match": {"address": "lane"}}
]
}
}
}'
返回age年龄大于40岁、state不是ID的所有数据:
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {
"bool": {
"must": [
{"match": {"age": "40"}}
],
"must_not": [
{"match": {"state": "ID"}}
]
}
}
}'- bool嵌套查询
# 嵌套查询
# SELECT * FROM books WHERE price = 35.99 OR ( publish_date = "2016-02-06" AND price = 99.99 )
curl -H "Content-Type:application/json" -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{
"query" : {
"bool" : {
"should" : [
{ "term" : {"price" : 35.99 }},
{ "bool" : {
"must" : [
{ "term" : {"publish_date" : "2016-06-06"}},
{ "term" : {"price" : 99.99}}
]
}
}
]
}
}
}' - filter的range范围过滤查询
查找price价钱大于20的数据:
# SELECT * FROM books WHERE price >= 20 AND price < 100
# gt : > 大于
# lt : < 小于
# gte : >= 大于等于
# lte : <= 小于等于
curl -H "Content-Type:application/json" -XGET 'http://hadoop1:9200/store/books/_search?pretty' -d '{
"query" : {
"bool" : {
"filter" : {
"range" : {
"price" : {
"gt" : 20.0,
"boost" : 4.0
}
}
}
}
}
}'
使用布尔查询返回balance在20000到30000之间的所有数据:
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"query": {
"bool": {
"must": {"match_all": {}},
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}'-
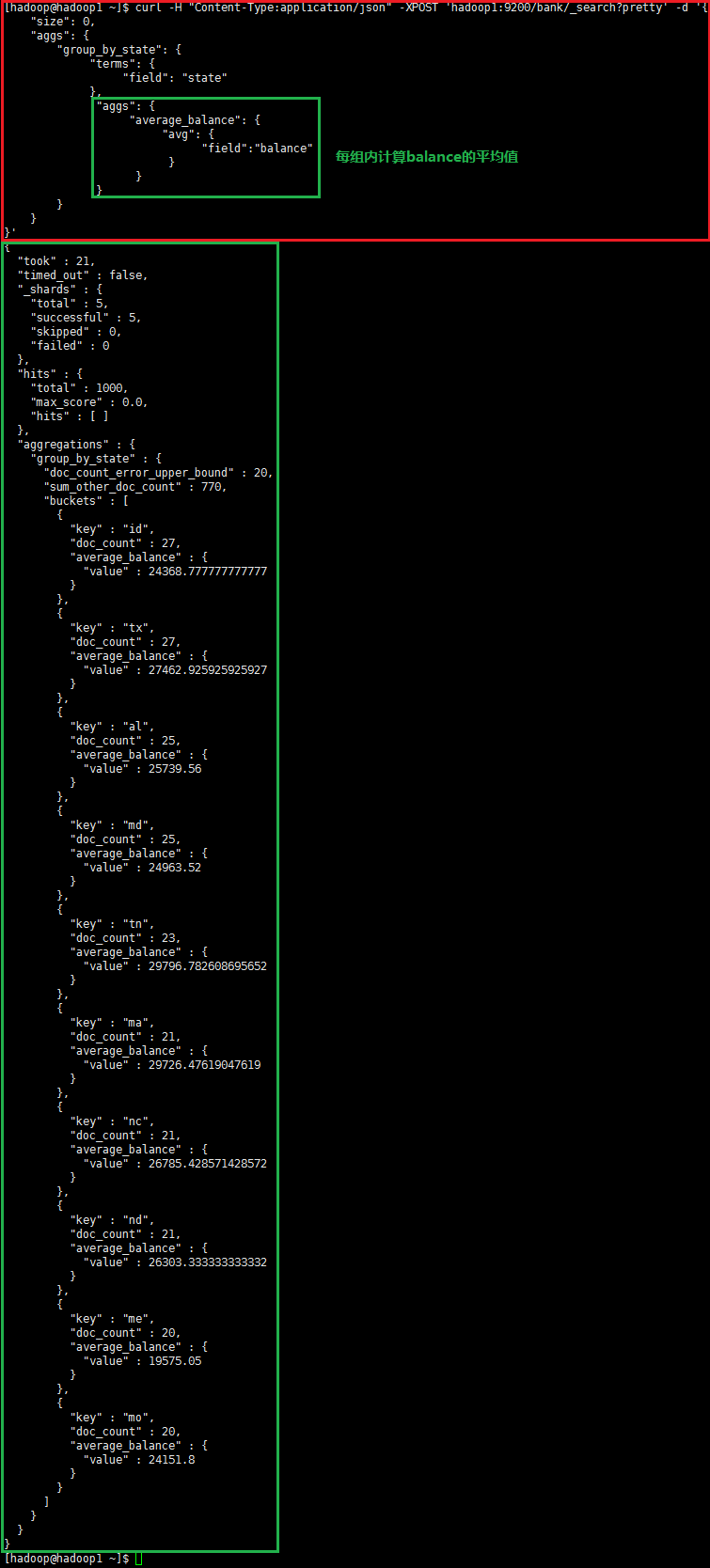
elasticSearch聚合查询
将所有的数据按照state分组(group),降序排序,计算每组balance的平均值并返回(默认)
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/_search?pretty' -d '{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state"
},
"aggs": {
"average_balance": {
"avg": {
"field":"balance"
}
}
}
}
}
}'
- 导入数据集
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/account/_bulk?pretty' --data-binary "@accounts.json"
curl -H "Content-Type:application/json" -XPOST 'hadoop1:9200/bank/account/_bulk?pretty' --data-binary "@/home/hadoop/accounts.json"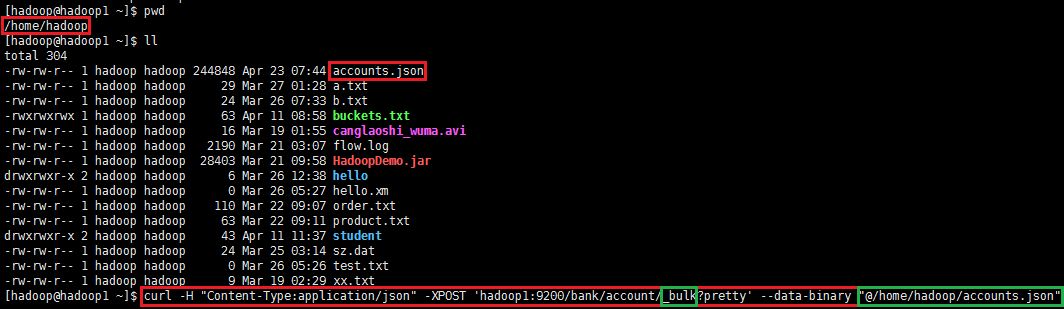
注:_bulk表示批量处理,"@accounts.json"或者"@/home/hadoop/accounts.json"可以用相对路径或者绝对路径表示。
查看accounts.json导入情况,使用 curl 'hadoop1:9200/_cat/indices?v'

4、Kibana
为了方便我们去操作ES,如果不安装去操作ES很麻烦,需要通过shell命令的方式。
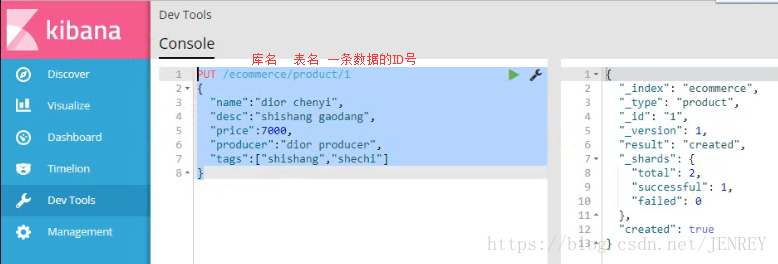
- 插入一条商品数据
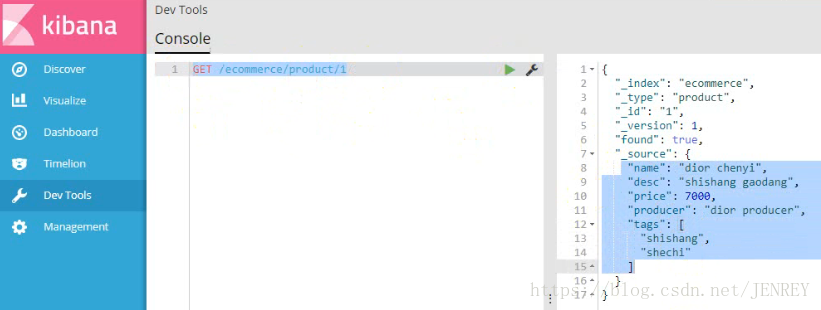
- 查询商品数据
- 修改商品数据
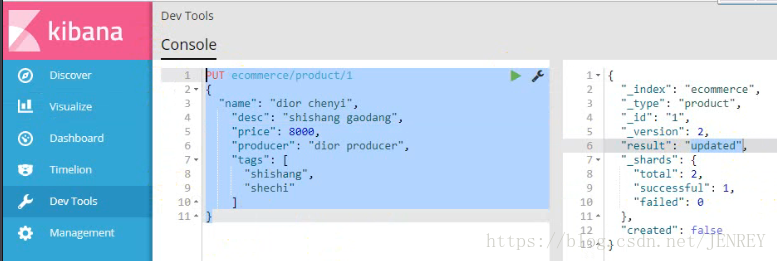
- 删除商品数据
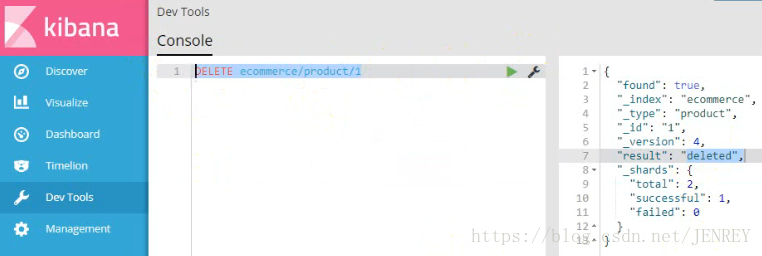
- 我们要进行全表扫描使用DSL语言,查询所有的商品

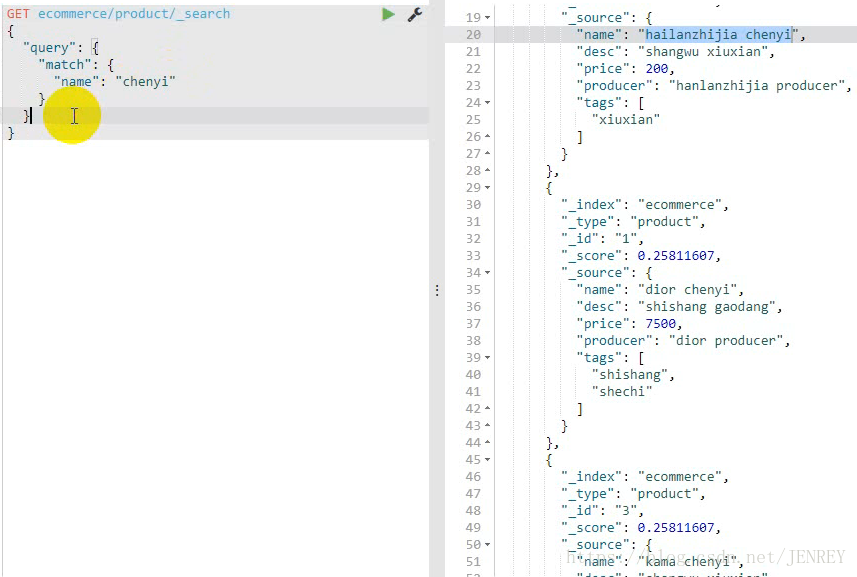
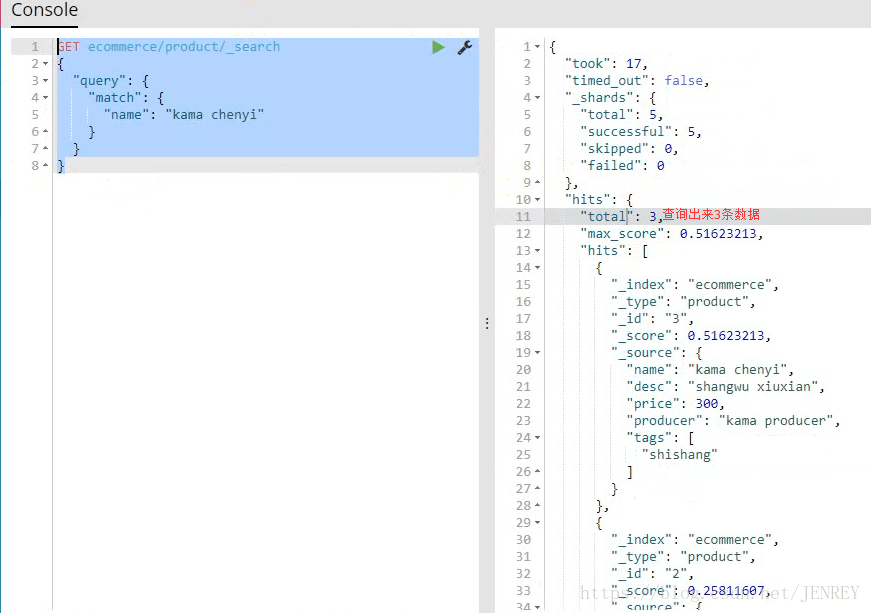
- 查询所有名称里面包含chenyi的商品,同时按价格进行降序排序
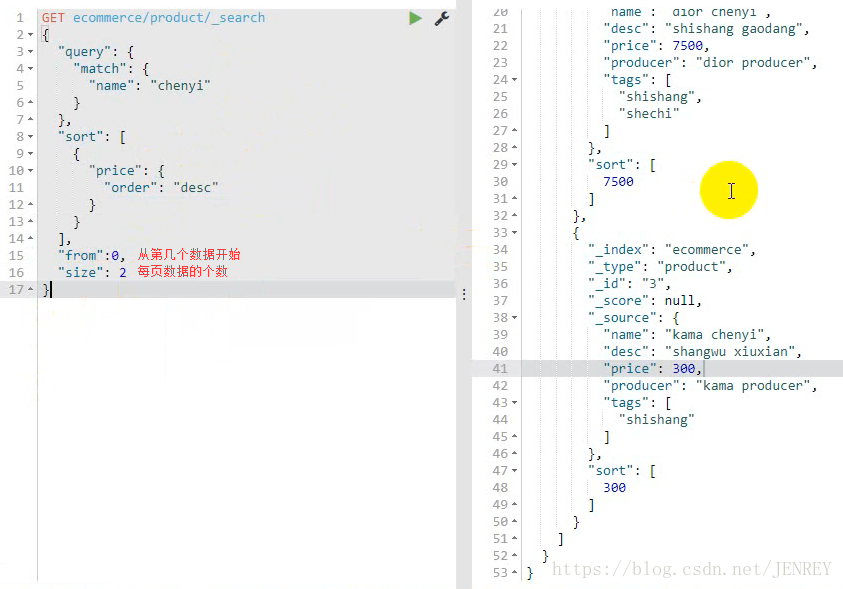
- 实现分页查询
- 进行全表扫面,但返回指定字段的数据
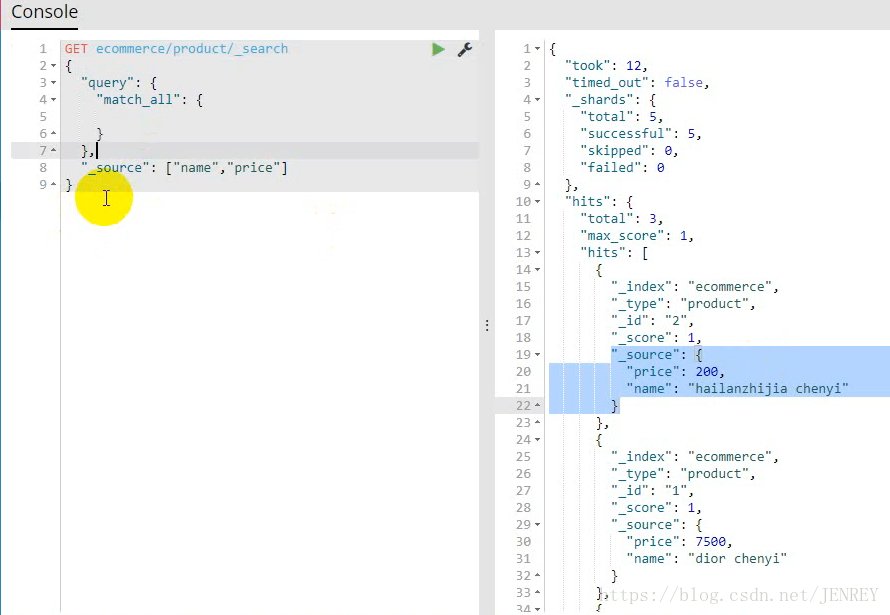
- 搜索名称里面包含chenyi的,并且价格大于250元的商品
相当于 select * form product where name like %chenyi% and price >250;
因为有两个查询条件,我们就需要使用下面的查询方式
如果需要多个查询条件拼接在一起就需要使用bool
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含以下操作符:
must :: 多个查询条件的完全匹配,相当于 and。
must_not :: 多个查询条件的相反匹配,相当于 not。
should :: 至少有一个查询条件匹配, 相当于 or。
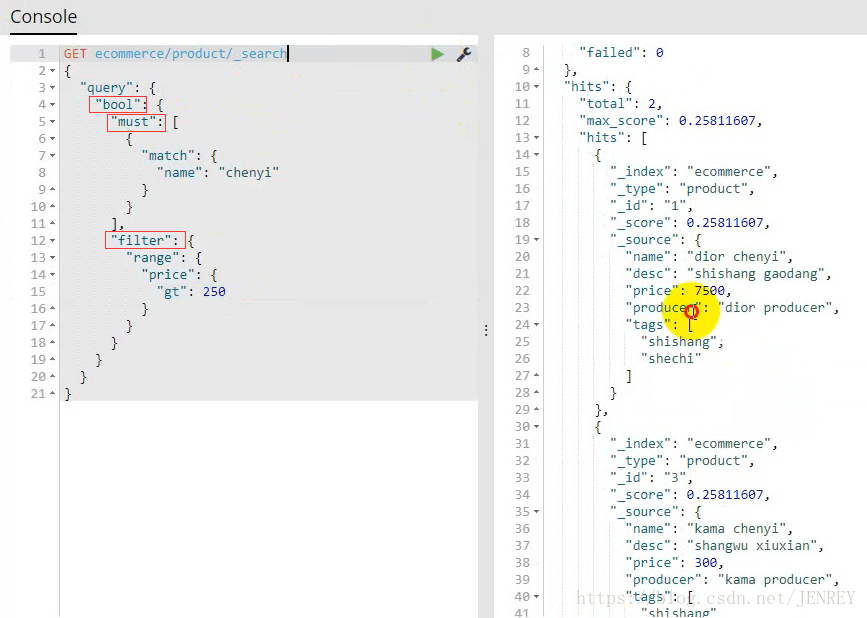
- 展示一个全文检索的效果
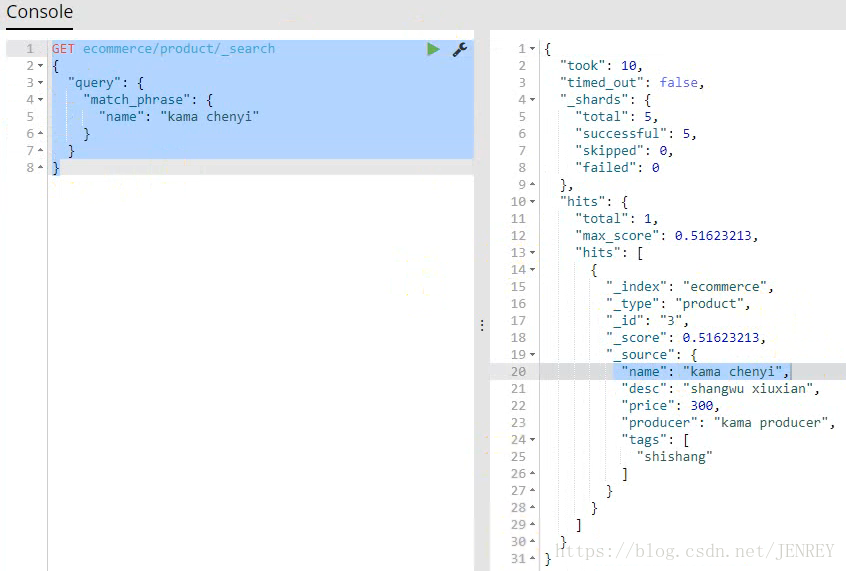
- 不要把条件分词,要精确匹配
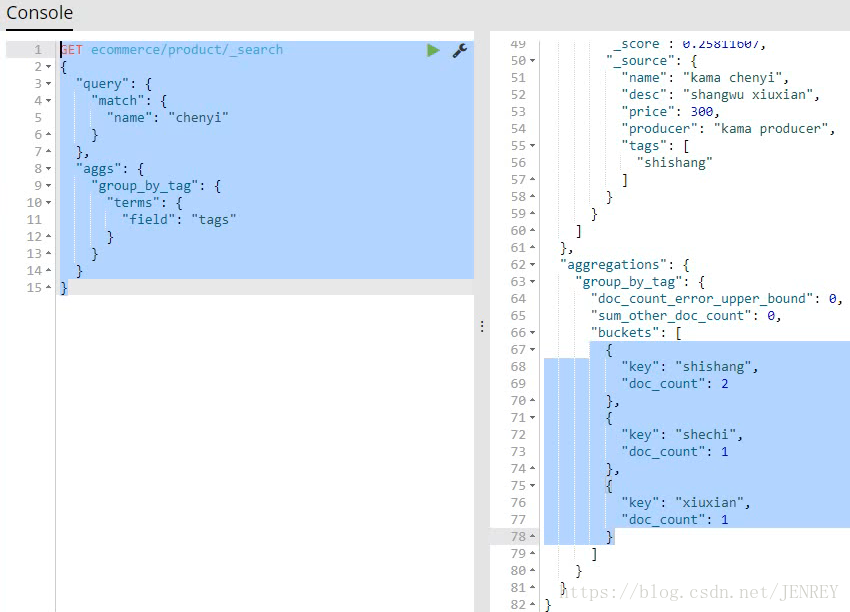
- 对商品名称里面包含chenyi的,计算每个tag下商品的数量
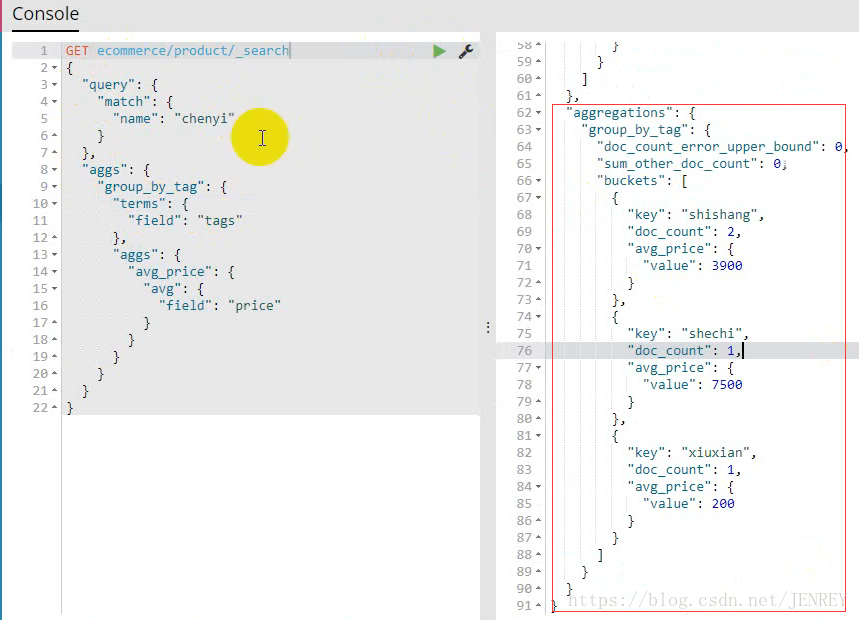
- 查询商品名称里面包含chenyi的数据,并且按照tag进行分组,计算每个分组下的平均价格
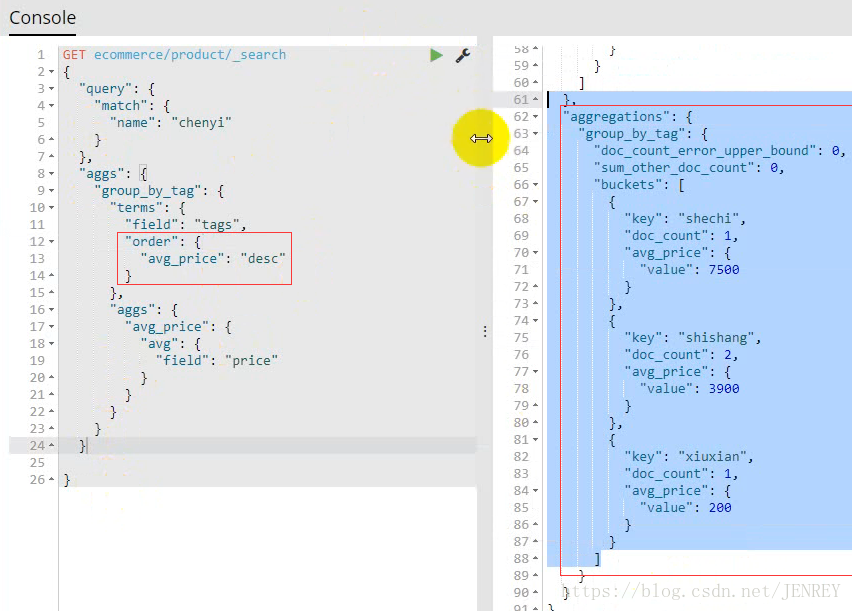
- 查询商品名称里面包含chenyi的数据,并且按照tag进行分组,计算每个分组下的平均价格,按照平均价格进行降序排序
- 查询出producer里面包含producer的数据,按照指定的价格区间进行分组,在每个组内再按tag进行分组,分完组以后再求每个组的平均价格,并且按照降序进行排序
















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









