






 该文章介绍了一个Python脚本,用于抓取特定漫画网站上的图片。脚本首先通过requests库获取页面,然后利用lxml和正则表达式提取所需参数。接着,它构造get请求,从chapterimage.ashx获取加密的JS代码,通过js2py库解码并提取图片链接,最后下载并保存图片。
该文章介绍了一个Python脚本,用于抓取特定漫画网站上的图片。脚本首先通过requests库获取页面,然后利用lxml和正则表达式提取所需参数。接着,它构造get请求,从chapterimage.ashx获取加密的JS代码,通过js2py库解码并提取图片链接,最后下载并保存图片。
漫画的图片页是ajax加载的,所以无法直接从源码中获取,在js中打上断点可以看到它是用get方式从chapterimage.ashx获取的链接
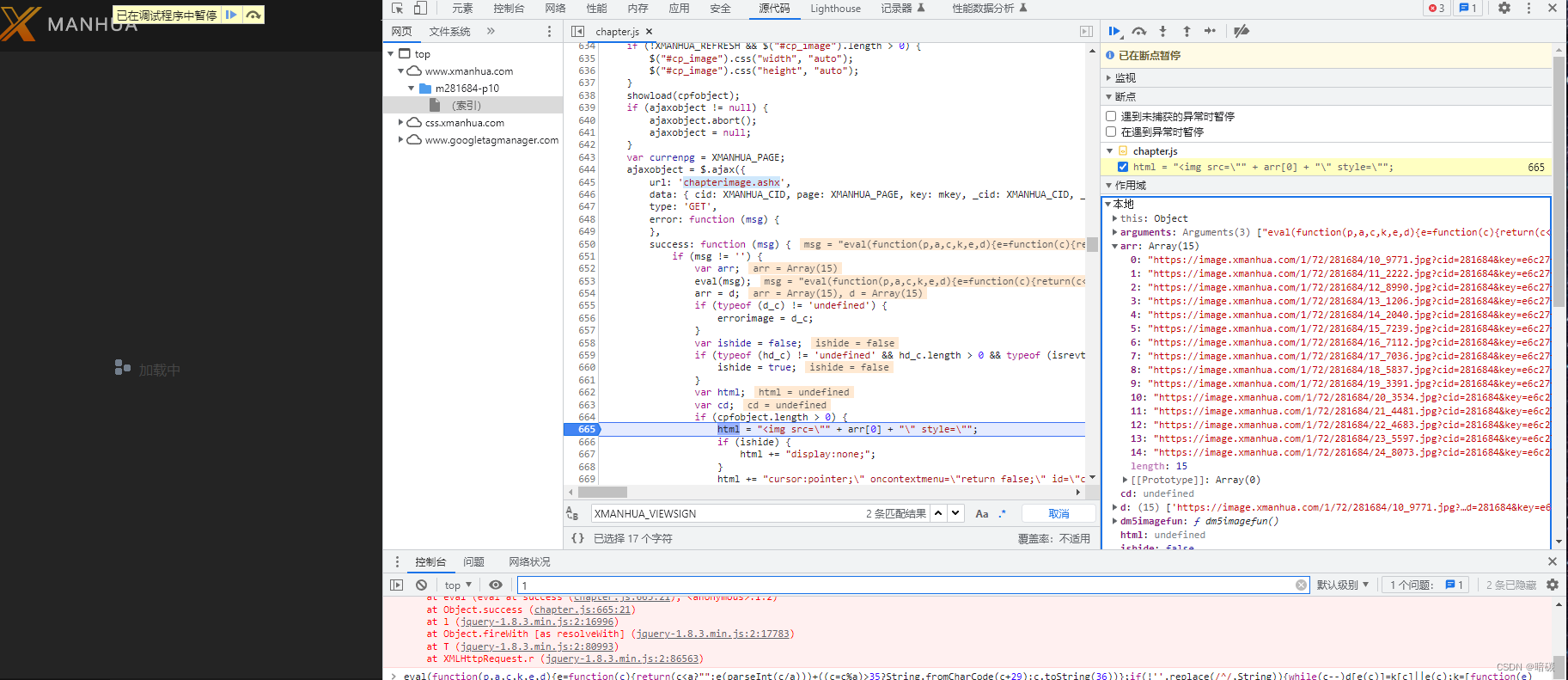
所需的请求参数可以从源码中获得,cid: XMANHUA_CID, page: XMANHUA_PAGE, key: mkey, _cid: XMANHUA_CID, _mid: XMANHUA_MID, _dt: XMANHUA_VIEWSIGN_DT, _sign: XMANHUA_VIEWSIG,需要这几个
然后构筑请求访问 章节url/chapterimage.ashx 可以得到一长串eval开头的js代码,用js2py.eval_js()运行会返回一个列表,列表的第一个就是当前页面的图片链接,然后下载保存即可
eval(function(p,a,c,k,e,d){e=function(c){return(c<a?"":e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)d[e(c)]=k[c]||e(c);k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1;};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p;}('e 9(){2 6=4;2 5=\'a\';2 7="g://j.h.f/1/b/4";2 3=["/c.8","/k.8"];pix|jpg|dm5imagefun|7407d43934b8cae5301d06a41c3f8301|72|1_5846||function|com|https|xmanhua||image|2_5069|length|uk|return|for'.split('|'),0,{}))

代码
import requests
import os
from lxml import etree
import re
import js2py
url = 'https://www.xmanhua.com/72xm/'#漫画详情页
header0={
'cookie': 'ComicHistoryitem_zh=; MANGABZ_MACHINEKEY=8c23b915-d06f-46f7-9463-8b3dee9bc31e; _ga=GA1.1.1601108167.1683357623; SL_G_WPT_TO=zh; SL_GWPT_Show_Hide_tmp=1; SL_wptGlobTipTmp=1; _ga_RV4ME3C1XE=GS1.1.1683372284.3.1.1683372284.0.0.0'
, 'referer': 'https://www.xmanhua.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
}
def main(url):
response = requests.get(url)
# print(response.text)
html = etree.HTML(response.text)
manga_title = html.xpath('/html/body/div[3]/div/div/p[1]/text()')#漫画标题
manga_title=manga_title[0].replace(' ','')
print(manga_title)
chapter_links=html.xpath('/html/body/div[5]/div[2]/a/@href')#章节链接
chapter_links = ['https://www.xmanhua.com' + link for link in chapter_links] # 将前缀添加到每个链接
print(chapter_links)
chapter_names=html.xpath('/html/body/div[5]/div[2]/a/text()')#章节名
chapter_names=[names.replace(' ','') for names in chapter_names]
chapter_names = list(filter(None, chapter_names))#删除空元素
print(chapter_names)
chapter_img_count=html.xpath('/html/body/div[5]/div[2]/a/span/text()')#章节图片数
chapter_img_count = [re.sub(r'\D', '', count) for count in chapter_img_count] # 保留每个元素中的数字
chapter_img_count = [int(count) for count in chapter_img_count] # 将每个元素转换为整数类型
print(chapter_img_count)
x=1
while x<len(chapter_img_count):
manga_path=f'd:/manga/{manga_title}/{chapter_names[x]}'
if not os.path.exists(manga_path): # 如果当前章节的文件夹不存在
os.makedirs(manga_path) # 创建当前章节的文件夹
x_url=chapter_links[x]+'chapterimage.ashx'
print(x_url)
xx=1
print('开始',chapter_names[x])
while xx<chapter_img_count[x]:
chapter_img_url=chapter_links[x]+f'#ipg{xx}'#每页链接
print(f'{chapter_names[x]}第{xx}/{chapter_img_count[x]}张图{chapter_img_url}')
chapter_img_response = requests.get(chapter_img_url)
chapter_img_response_text=chapter_img_response.text
#提取请求参数
XMANHUA_VIEWSIGN=re.findall('XMANHUA_VIEWSIGN="(.*?)"',chapter_img_response_text)[0]
XMANHUA_CID=re.findall('XMANHUA_CID=(\d+);',chapter_img_response_text)[0]
XMANHUA_MID=re.findall('XMANHUA_MID=(\d+);',chapter_img_response_text)[0]
XMANHUA_VIEWSIGN_DT = re.findall('XMANHUA_VIEWSIGN_DT="(.*?)"',chapter_img_response_text)[0].replace(' ','+').replace(':','%3A')
mkey=''
XMANHUA_PAGE=xx
# print(XMANHUA_CID,XMANHUA_VIEWSIGN,XMANHUA_MID,XMANHUA_VIEWSIGN_DT)
#构筑
data={
'cid':XMANHUA_CID,
'page':xx,
'key':'',
'_cid': XMANHUA_CID,
'_mid':XMANHUA_MID ,
'_dt':XMANHUA_VIEWSIGN_DT,
'_sign': XMANHUA_VIEWSIGN
}
x_url1=f"{x_url}?cid={XMANHUA_CID}&page={xx}&key=&_cid={XMANHUA_CID}&_mid={XMANHUA_MID}&_dt={XMANHUA_VIEWSIGN_DT}&_sign={XMANHUA_VIEWSIGN}"
# print(x_url1)
header={
'cookeie':'MANGABZ_MACHINEKEY=80604737-62e4-494b-95b4-93f916e81d0e; _ga=GA1.1.1400277016.1683338448; mangabzcookieenabletest=1; mangabzimgcooke=281684%7C24%2C10310%7C8; mangabzimgpage=281684|1:1,10310|1:1,287606|1:1; firsturl=https%3A%2F%2Fwww.xmanhua.com%2Fm281684%2F; firsturl=https%3A%2F%2Fwww.xmanhua.com%2Fm281684%2F; readhistory_time=1-72-281684-1; ComicHistoryitem_zh=History=72,638189927018997152,281684,1,0,0,0,112|31270,638189832630312415,287606,1,0,0,0,1&ViewType=0; image_time_cookie=281684|638189927019417558|13,10310|638189906257562255|7,287606|638189832630732832|0; _ga_RV4ME3C1XE=GS1.1.1683364851.5.1.1683367105.0.0.0',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
,'referer':chapter_links[x]
}
eval_response1=requests.get(x_url,headers=header,data=data)
if len(eval_response1.text)<20:
print(eval_response1.text,'报错')#可能会因为cookie的原因获取不对js代码,请换成你的cookie
else:
eval_text=str(eval_response1.text)
img_urls=js2py.eval_js(eval_text)#用js2py获取js代码运行的结果
# print(img_urls)
img_url=img_urls[0]
#下载图片
print('图片链接:',img_url)
img_response=requests.get(img_url,headers={'Referer': 'https://www.xmanhua.com/'})
with open(f'{manga_path}/{xx}.jpg','wb') as f:
f.write(img_response.content)
xx+=1#章节内第xx张图
x+=1#第x章
main(url)

















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









