







目录
简介
本文详细讲解了大模型流式输出的源码实现,包括TextStreamer 基础流式输出和TextIterateStreamer 迭代器流式输出。此外,还提供了两种主流Web框架(Streamlit和Gradio)的部署方案,设计前端界面进行大模型流式输出对话演示。模型提供了本地加载以及vllm部署两种方法,帮助读者快速应用部署大模型。
TextStreamer 基础流式输出
先定义一个基础版流式输出的加载模型并生成的代码
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer, Qwen2ForCausalLM
device = "cuda" # the device to load the model onto
model_path = 'Qwen/Qwen2.5-1.5B-Instruct'
model: Qwen2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(model_path)
text = [
{"role": "system", "content": "你是一个人工智能助手"},
{"role": "user", "content": '写一个谜语'}
]
text = tokenizer.apply_chat_template(text, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(text, return_tensors="pt").to(device)
# 定义基础版的流式输出
# skip_prompt参数决定是否将prompt打印出来
# skip_special_tokens是解码参数,决定tokenizer.decode解码时是否忽略特殊字符,例如<|im_end|>
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generated_ids = model.generate(
max_new_tokens=64,
do_sample=True,
streamer=streamer, # 传入model.generate
**model_inputs,
)
generated_ids1 = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids1, skip_special_tokens=True)[0]
print("最终结果:", response)
输出的结果如下,第一行是流式输出打印的结果,他是一个字一个字打印出来的。第二行是代码最后一行的print,打印最终的所有输出。
注意:这里第一行的打印除了传入streamer以外,没有其他的操作,也就是streamer内部自行一个字一个字打印了。

TextStreamer源码
在 transformers\generation\streamers.py文件中写了流式输出类的源码。
首先定义了一个BaseStreamer类,用于其他子类的继承。BaseStreamer类定义了put和end的抽象方法,表示子类在继承的时候必须重写这两个方法,否则这个类无法使用。
from queue import Queue
from typing import TYPE_CHECKING, Optional
if TYPE_CHECKING:
from ..models.auto import AutoTokenizer
class BaseStreamer:
def put(self, value):
raise NotImplementedError()
def end(self):
raise NotImplementedError()
为什么必须实现这两个方法,我们来看transformers源码是在哪里调用它们的。
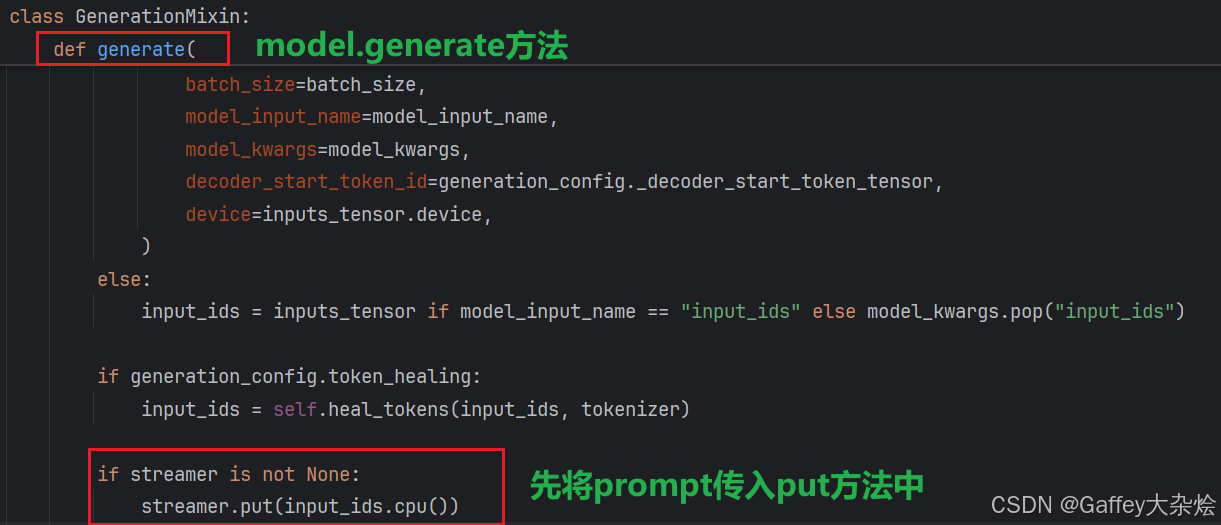
首先进入model.generate函数,也就是我们模型常用的生成函数,最开始先调用streamer.put将prompt传入进去,此时需要注意两点。
- 验证当前
batch是否为1,如果大于1会弹出异常,因为流式输出只能传入单个序列。 - 如果传入了
skip_prompt=True,则表示忽略打印prompt,否则在流式输出打印的时候会将prompt也打印出来。
然后在实际采样的时候也会调用,在每个step预测下一个token的时候,会将该token_id传入streamer.put,在内部解码后打印出来。
在整个序列全部生成结束后,调用streamer.end方法,此时会打印剩下缓存中的所有字符。
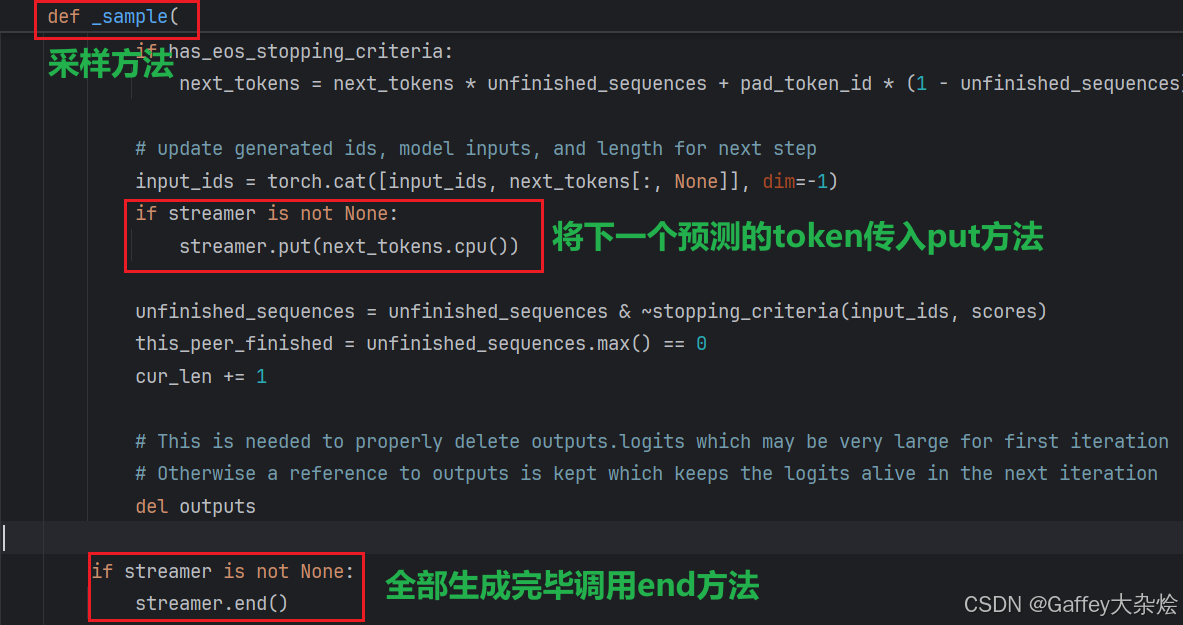
综上所述,.put()和.end()是TextStreamer的两个核心方法,所以子类必须重写。
下面为TextStreamer类的源码,.put方法接收开始的prompt和下一个预测的token,代码中有详细注释,总结起来的流程如下:
- 验证输入的
batch是否等于1,否则弹出异常 - 如果是第一次输入,则视为
prompt,用参数skip_prompt决定是否打印prompt,并直接返回 - 将下一个
token加入缓存序列中,使用tokenizer.decode解码序列,用4、5、6步决定如何打印 - 如果最后一个字符为换行符,则清空缓存序列,直接打印结尾字符
- 如果最后一个字符是中文,则直接打印
- 如果最后一个字符是英文,则解码出空格之后再打印空格前的字符
- 如果调用
end方法,则打印缓存中剩余的所有token
注:打印方法为print,直接将字符打印到标准输出上stdout
class TextStreamer(BaseStreamer):
def __init__(self, tokenizer: "AutoTokenizer", skip_prompt: bool = False, **decode_kwargs):
self.tokenizer = tokenizer
self.skip_prompt = skip_prompt # 是否打印prompt
self.decode_kwargs = decode_kwargs # 解码参数
# 用于记录流式输出过程中的变量
self.token_cache = [] # 缓存token
self.print_len = 0 # 记录上次打印位置
self.next_tokens_are_prompt = True # 第一次为True,后续为False,记录当前调用put()时是否为prompt
def put(self, value):
"""
传入token后解码,然后在他们形成一个完整的词时将其打印到标准输出stdout
"""
# 这个类只支持 batch_size=1
# 第一次运行.put()时,value=input_id,此时检测batch大小,input_id.shape:(batch_size, seq_len)
if len(value.shape) > 1 and value.shape[0] > 1:
raise ValueError("TextStreamer only supports batch size 1")
# 如果输入batch形式,但是batch_size=1,取第一个batch序列
elif len(value.shape) > 1:
value = value[0]
# 第一次输入的视为prompt,用参数判断是否打印prompt
if self.skip_prompt and self.next_tokens_are_prompt:
self.next_tokens_are_prompt = False
return
# 将新token添加到缓存,并解码整个token
self.token_cache.extend(value.tolist())
text = self.tokenizer.decode(self.token_cache, **self.decode_kwargs)
# 如果token以换行符结尾,则清空缓存
if text.endswith("\n"):
printable_text = text[self.print_len :]
self.token_cache = []
self.print_len = 0
# 如果最后一个token是中日韩越统一表意文字,则打印该字符
elif len(text) > 0 and self._is_chinese_char(ord(text[-1])):
printable_text = text[self.print_len :]
self.print_len += len(printable_text)
# 否则,打印直到最后一个空格字符(简单启发式,防止输出token是不完整的单词,在前一个词解码完毕后在打印)
# text="Hello!",此时不打印。text="Hello! I",打印Hello!
else:
printable_text = text[self.print_len : text.rfind(" ") + 1]
self.print_len += len(printable_text)
self.on_finalized_text(printable_text)
def end(self):
"""清空缓存,并打印换行符到标准输出stdout"""
# 如果缓存不为空,则解码缓存,并打印直到最后一个空格字符
if len(self.token_cache) > 0:
text = self.tokenizer.decode(self.token_cache, **self.decode_kwargs)
printable_text = text[self.print_len :]
self.token_cache = []
self.print_len = 0
else:
printable_text = ""
self.next_tokens_are_prompt = True
self.on_finalized_text(printable_text, stream_end=True)
def on_finalized_text(self, text: str, stream_end: bool = False):
# flush=True,立即刷新缓冲区,实时显示,取消缓冲存在的延迟
# 如果stream_end为True,则打印换行符
print(text, flush=True, end="" if not stream_end else None)
def _is_chinese_char(self, cp):
"""检查CP是否是CJK字符"""
# 这个定义了一个"chinese character"为CJK Unicode块中的任何内容:
# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
# 我们使用Unicode块定义,因为这些字符是唯一的,并且它们是所有主要语言的常见字符。
# 注意,CJK Unicode块不仅仅是日语和韩语字符,
# 尽管它的名字如此,现代韩语的Hangul字母是另一个块,
# 日语的Hiragana和Katakana也是另一个块,
# 那些字母用于写space-separated words,所以它们不被特别处理,像其他语言一样处理
if (
(cp >= 0x4E00 and cp <= 0x9FFF)
or (cp >= 0x3400 and cp <= 0x4DBF) #
or (cp >= 0x20000 and cp <= 0x2A6DF) #
or (cp >= 0x2A700 and cp <= 0x2B73F) #
or (cp >= 0x2B740 and cp <= 0x2B81F) #
or (cp >= 0x2B820 and cp <= 0x2CEAF) #
or (cp >= 0xF900 and cp <= 0xFAFF)
or (cp >= 0x2F800 and cp <= 0x2FA1F) #
):
return True
return False
TextIterateStreamer 迭代器流式输出
定义一个迭代器版流式输出的加载模型并生成的代码,与基础版的区别是需要单独启动一个线程调用,并且不会默认使用print打印到标准输出,需要将其视为迭代器循环取出字符。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer, Qwen2ForCausalLM
device = "cuda" # the device to load the model onto
model_path = 'Qwen/Qwen2.5-1.5B-Instruct'
model: Qwen2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(model_path)
text = [
{"role": "system", "content": "你是一个人工智能助手"},
{"role": "user", "content": '写一个谜语'}
]
text = tokenizer.apply_chat_template(text, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(text, return_tensors="pt").to(device)
# 定义迭代版的流式输出,输入参数与基础版相同
# skip_prompt参数决定是否将prompt打印出来
# skip_special_tokens是解码参数,决定tokenizer.decode解码时是否忽略特殊字符,例如<|im_end|>
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generation_kwargs = dict(model_inputs, streamer=streamer, max_new_tokens=100)
# 在单独的线程中调用.generate()
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
# 启动线程之后生成结果会阻塞,此时可以在任何地方调用streamer迭代器取出输出结果
# 当前将其取出后使用print打印,也可以自定义显示方法,例如下文使用gradio或streamlit显示
generated_text = ""
for new_text in streamer:
print(new_text, end="", flush=True)
TextIteratorStreamer 源码
TextIteratorStreamer继承了TextStreamer类,也就是说复用了TextStreamer类中的.put()和.end()方法,只是在输出的时候重写了on_finalized_text()方法。
这意味着不再使用print将文本打印到标准输出,而是放到一个队列中。并且将对象本身也包装成了一个迭代器,每次调用时从队列中取出文本并返回,根据用户自己定义的方式去进行输出。
总结起来的流程如下(基于TextStreamer):
model.generate()中的put()方法依然使用TextStreamer中定义的,只不过在最后一行调用on_finalized_text()方法时,将该文本放入Queue队列中- 如果调用了
end()方法,将一个停止信号(设为None)也放入Queue队列中 - 定义
__iter__方法将自身包装成迭代器 - 每次循环调用迭代器,执行
__next__方法,从队列中取出一段文本返回
from queue import Queue
from typing import TYPE_CHECKING, Optional
class TextIteratorStreamer(TextStreamer):
"""
将打印就绪的文本存储在队列中的流式处理器,可以被下游应用程序作为迭代器使用。这对于需要以非阻塞方式访问生成文本的应用程序很有用
(例如在交互式 Gradio 演示中)。
Parameters:
tokenizer (`AutoTokenizer`):
The tokenized used to decode the tokens.
skip_prompt (`bool`, *optional*, defaults to `False`):
Whether to skip the prompt to `.generate()` or not. Useful e.g. for chatbots.
timeout (`float`, *optional*):
文本队列的超时时间。如果为`None`,队列将无限期阻塞。当在单独的线程中调用`.generate()`时,这对于处理异常很有用。
decode_kwargs (`dict`, *optional*):
Additional keyword arguments to pass to the tokenizer's `decode` method.
"""
def __init__(
self, tokenizer: "AutoTokenizer", skip_prompt: bool = False, timeout: Optional[float] = None, **decode_kwargs
):
super().__init__(tokenizer, skip_prompt, **decode_kwargs)
self.text_queue = Queue() # 文本队列
self.stop_signal = None # 停止信号
self.timeout = timeout # 队列超时时间
def on_finalized_text(self, text: str, stream_end: bool = False):
"""Put the new text in the queue. If the stream is ending, also put a stop signal in the queue."""
# 将新文本放入队列
self.text_queue.put(text, timeout=self.timeout)
# 如果流结束,则将停止信号放入队列
if stream_end:
self.text_queue.put(self.stop_signal, timeout=self.timeout)
# 调用自己,返回迭代器
def __iter__(self):
return self
def __next__(self):
# 调用一次迭代器,就从队列中获取一段文本,如果超时则抛出异常,默认self.timeout,表示不限时长
value = self.text_queue.get(timeout=self.timeout)
# 如果获取到停止信号,则抛出StopIteration异常表示迭代结束
if value == self.stop_signal:
raise StopIteration()
# 否则返回获取到的文本
else:
return value
本地代码模型加载并前端展示
streamlit 输出显示
使用streamlit定义一个简单的对话界面,在streamlit程序中进行模型加载,并支持流式输出。
import streamlit as st
import random
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer, Qwen2ForCausalLM
from threading import Thread
device = "cuda" # the device to load the model onto
st.title("大模型流式输出测试")
if "messages" not in st.session_state:
st.session_state.messages = [{"role": "system", "content": "你是一个人工智能助手"}]
model_path = 'D:\learning\python\pretrain_checkpoint\Qwen2.5-1.5B-Instruct'
st.session_state.model: Qwen2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map="cuda")
st.session_state.tokenizer = AutoTokenizer.from_pretrained(model_path)
for message in st.session_state.messages[1:]:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if prompt := st.chat_input("请输入问题"):
with st.chat_message("user"):
st.markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
text = st.session_state.tokenizer.apply_chat_template(st.session_state.messages, tokenize=False, add_generation_prompt=True)
model_inputs = st.session_state.tokenizer(text, return_tensors="pt").to(device)
streamer = TextIteratorStreamer(st.session_state.tokenizer, skip_prompt=True, skip_special_tokens=True)
generation_kwargs = dict(model_inputs, streamer=streamer, max_new_tokens=1024)
# 在单独的线程中调用.generate()
thread = Thread(target=st.session_state.model.generate, kwargs=generation_kwargs)
thread.start()
with st.chat_message("assistant"):
message_placeholder = st.empty()
generated_text = ""
for new_text in streamer:
generated_text += new_text
message_placeholder.markdown(generated_text)
st.session_state.messages.append({"role": "assistant", "content": generated_text})
if st.button("清空"):
st.session_state.messages = [{"role": "system", "content": "你是一个人工智能助手"}]
st.rerun()
下图为实际展示的界面,可以在下方输入框输入问题,大模型会流式输出回答。简单定义了一个清空历史消息的按钮,用于重新开启对话。

gradio 输出显示
使用gradio定义一个简单的对话界面,在gradio程序中进行模型加载,并支持流式输出。
import gradio as gr
from threading import Thread
from typing import List
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer, Qwen2ForCausalLM
device = "cuda" # the device to load the model onto
model_path = 'D:\learning\python\pretrain_checkpoint\Qwen2.5-1.5B-Instruct'
model: Qwen2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(model_path)
def chat(question, history):
message = [{"role": "system", "content": "你是一个人工智能助手"}]
if not history:
message.append({"role": "user", "content": question})
else:
for i in history:
message.append({"role": "user", "content": i[0]})
message.append({"role": "assistant", "content": i[1]})
message.append({"role": "user", "content": question})
text = tokenizer.apply_chat_template(message, tokenize=False, add_generation_prompt=True)
encoding = tokenizer(text, return_tensors="pt").to(device)
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generation_kwargs = dict(encoding, streamer=streamer, max_new_tokens=1024)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
response = ""
for text in streamer:
response += text
yield response
demo = gr.ChatInterface(
fn=chat,
title="聊天机器人",
description="输入问题开始对话"
)
demo.queue().launch()
下图为实际展示的界面
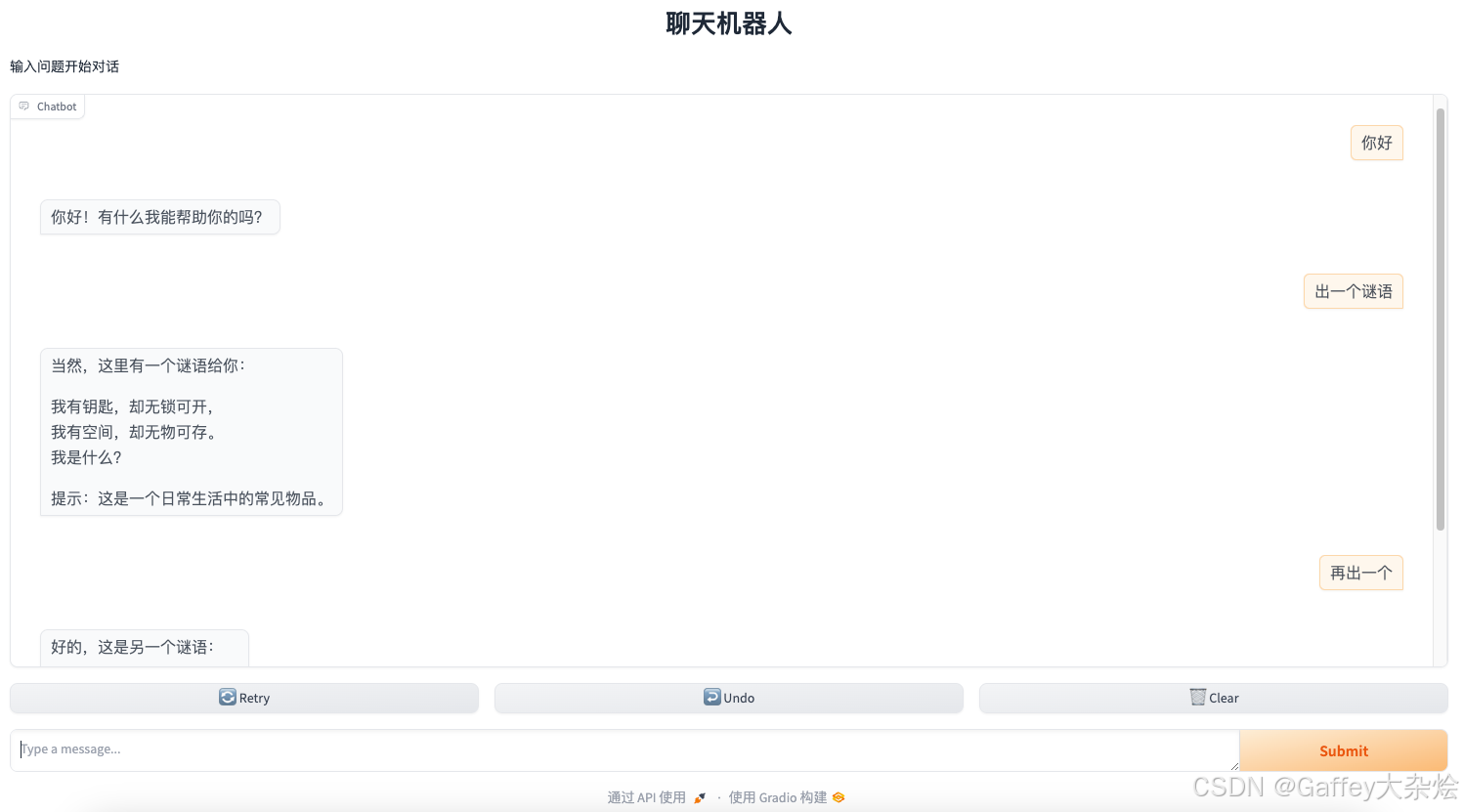
vllm 部署模型并前端展示
使用如下命令启动部署一个模型,注意以下参数
CUDA_VISIBLE_DEVICES:指定GPU索引python:先conda进入你的环境,再启动--host 0.0.0.0 --port 5001:指定ip+端口--served-model-name:启动服务的名字,也就是下面调用client.chat.completions.create时输入的model名字--model:模型权重的存储位置--tensor_parallel_size:使用几个GPU加载模型,与前面CUDA_VISIBLE_DEVICES要对应上--gpu-memory-utilization:kv cache占用显存比例,使用默认0.9就好
CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 5001 --served-model-name qwen2.5 --model /data0/zejun7/model_checkpoint/Qwen2.5-1.5B-Instruct --tensor_parallel_size 1 --gpu-memory-utilization 0.9
streamlit 输出显示
使用streamlit定义一个简单的对话界面,在streamlit调用vllm部署的模型,并支持流式输出。
import streamlit as st
import random
import time
import torch
from openai import OpenAI
st.title("大模型流式输出测试")
def get_response(message):
openai_api_key = "EMPTY"
openai_api_base = "http://0.0.0.0:5001/v1" # 换成自己的ip+端口
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
response = client.chat.completions.create(
model="qwen2.5",
messages=message,
stream=True,
)
for chunk in response:
if chunk.choices[0].delta.content is None:
yield ""
else:
yield chunk.choices[0].delta.content
if "messages" not in st.session_state:
st.session_state.messages = [{"role": "system", "content": "你是一个人工智能助手"}]
for message in st.session_state.messages[1:]:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if prompt := st.chat_input("请输入问题"):
with st.chat_message("user"):
st.markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("assistant"):
message_placeholder = st.empty()
generated_text = ""
for new_text in get_response(st.session_state.messages):
generated_text += new_text
message_placeholder.markdown(generated_text)
st.session_state.messages.append({"role": "assistant", "content": generated_text})
if st.button("清空"):
st.session_state.messages = [{"role": "system", "content": "你是一个人工智能助手"}]
st.rerun()

gradio 输出显示
使用gradio定义一个简单的对话界面,在gradio中调用vllm部署的模型,并支持流式输出。
import gradio as gr
from openai import OpenAI
def chat(question, history):
message = [{"role": "system", "content": "你是一个人工智能助手"}]
if not history:
message.append({"role": "user", "content": question})
else:
for i in history:
message.append({"role": "user", "content": i[0]})
message.append({"role": "assistant", "content": i[1]})
message.append({"role": "user", "content": question})
openai_api_key = "EMPTY"
openai_api_base = "http://0.0.0.0:5001/v1" # 换成自己的ip+端口
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
response = client.chat.completions.create(
model="qwen2.5",
messages=message,
stream=True,
)
response_text = ""
for chunk in response:
if chunk.choices[0].delta.content is None:
response_text += ""
yield response_text
else:
response_text += chunk.choices[0].delta.content
yield response_text
demo = gr.ChatInterface(
fn=chat,
title="聊天机器人",
description="输入问题开始对话"
)
demo.queue().launch(
server_name="0.0.0.0", # 如果不好使,可以尝试换成localhost或自身真正的ip地址
share=True,
)
下图为实际展示的界面

备注
如需使用此代码,注意替换中间的模型等参数,文中所有代码放置于github

















 5347
5347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









