







(跟着B站“刘二大人”pytorch学习第二课,实现一个简单的线性函数,给出三组数据值,预测第四组的值。)
1、梯度下降算法:通过迭代找到目标函数的最小值,或者收敛到最小值
(梯度下降算法不一定能得到最优解,但是能得到局部最优,满足大部分需求。其中a为学习率,取得值要小一些,可以处理出现鞍点的情况)
由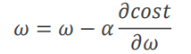 得到
得到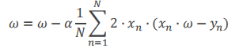
#使用梯度下降算法
import numpy as np
import torch
import matplotlib.pyplot as plt
w=1.0
# 定义数据集
x_data= [1.0, 2.0, 3.0]
y_data=[2.0, 4.0, 6.0]
# 定义前向传播
def forward(x):
return x* w
#定义损失函数
def cost(xs, ys):
cost=0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost+= (y_pred- y)**2
return cost/len(xs)
#定义梯度下降函数/优化器
def gradient(xs, ys):
grad= 0
for x, y in zip(xs, ys):
grad+= 2*x*(forward(x)-y) #求梯度
return grad/len(xs)
print("训练之前预测4",4,forward(4))
# 训练数据
epoch_list=[]
cost_list= []
for epoch in range(100):
cost_val= cost(x_data, y_data)
grad_val= gradient(x_data, y_data)
w= w- 0.01*grad_val
print("Epoch=", epoch, " w=", w, " cost=", cost_val)
epoch_list.append(epoch)
cost_list.append(cost_val)
# 预测
print("训练之后预测", 4, forward(4))
plt.plot(epoch_list, cost_list)
plt.show()得到结果:

2、随机梯度下降算法:每次的权重更新只利用数据集中的一个样本来完成。
w= w- a*2x*(x*w- y)
代码实现部分:
import numpy as np
import matplotlib.pyplot as plt
import torch
x_data=[1.0, 2.0, 3.0]
y_data=[2.0, 4.0, 6.0]
w= 1.0
# 前向传播
def forward(x):
return x* w
# 损失函数
def loss(x, y):
y_pred= forward(x)
return (y_pred- y)**2
# 梯度下降(反向传播)
def gradient(x, y):
return 2*x*(forward(x)-y)
# 训练
w_list=[]
cost_list=[]
for epoch in range(100):
for x, y in zip(x_data, y_data):
cost_val= loss(x, y)
grad= gradient(x, y)
w= w- 0.01* grad
w_list.append(w)
cost_list.append(cost_val)
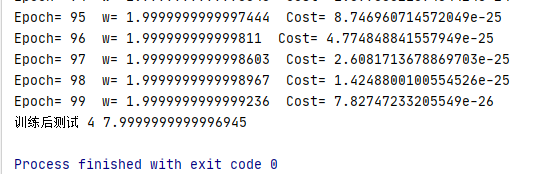
print("Epoch=",epoch, " w=", w, " Cost=", cost_val)
print("训练后测试",4, forward(4))
plt.plot(w_list, cost_list)
plt.xlabel("w_val")
plt.ylabel("cost_val")
plt.show()
结果:由图可以看出,当权重趋于2时,损失值趋于0
















 1161
1161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









