







Spark Shuffle
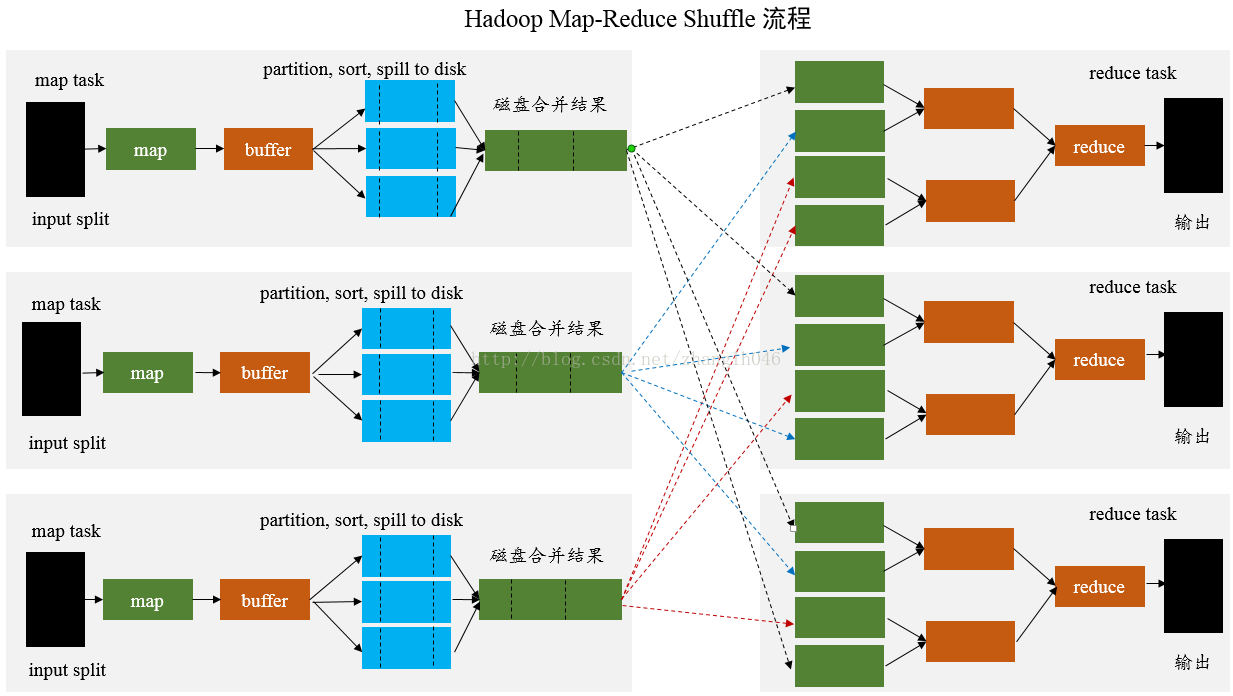
- 在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以shuffle性能的高低也直接决定了整个程序的性能高低。
一、HashShuffle机制
1.1 HashShuffle概述
Spark1.6版本之前使用的是HashShuffle。
Spark运行分为两个部分:一是驱动程序,核心是SparkContext;
二是Worker节点上的Task
程序运行的过程中,Driver和Executor进程相互交互,Driver会分配Task到Executor ,Task的数据要从上游的Task抓取。其中下一个Stage向上一个Stage要数据的这个过程就是Shuffle
- 未优化之前
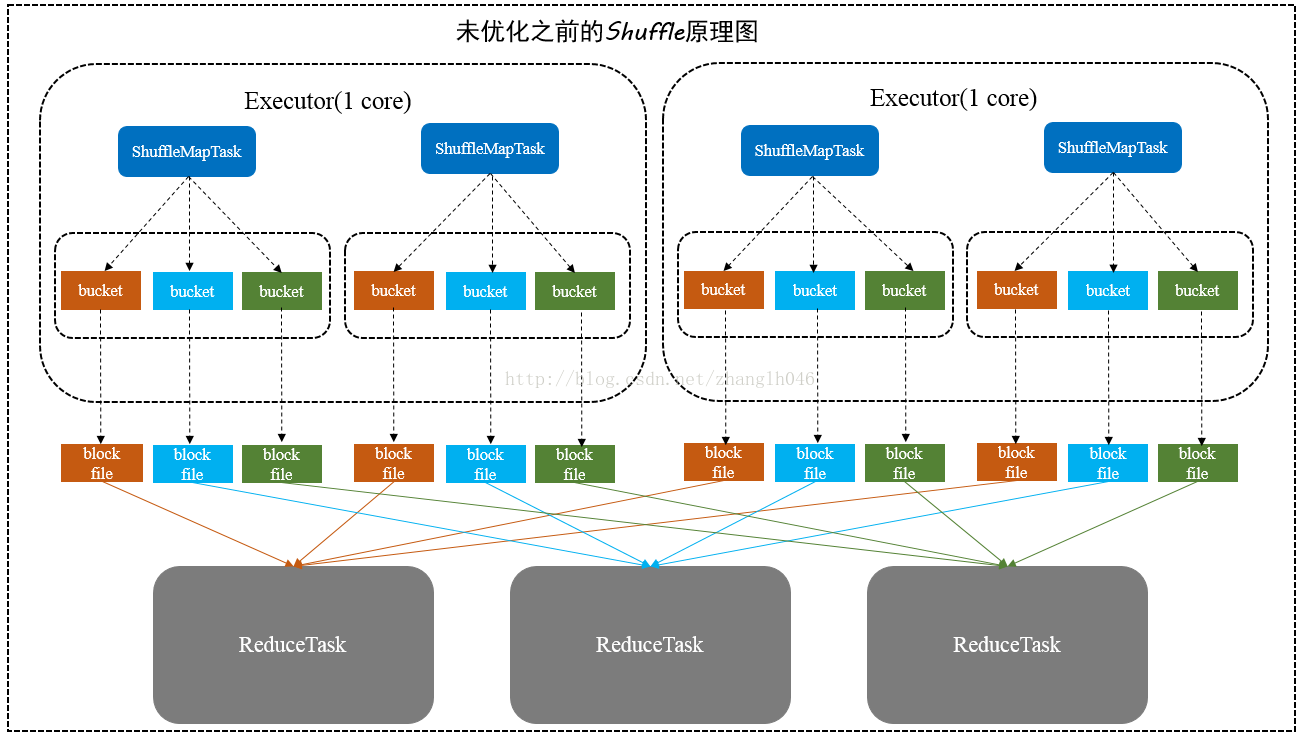
- 每一个ShuffleMapTask会为每一个ReduceTask创建一个bucket缓存和一个block文件(数据经过HashPartitioner之后找到对应的bucket)
- ShuffleMapTask将输出作为MapStatus发送到DAGScheduler的MapOutputTrackerMaster,每一个MapStatus包含每一个ReduceTask要拉去的数据的位置和大小。
- ReduceTask利用MapStatus提供的信息,将数据拉取过来。形成一个内部的ShuffleRDD
- 缺点
- 数据量大的时候 会生成M*R个小文件
- bucket缓存,要将所有的MapTask的数据写入到bucket才能刷写到磁盘,这样的话可能造成内存溢出;
- 优化之后
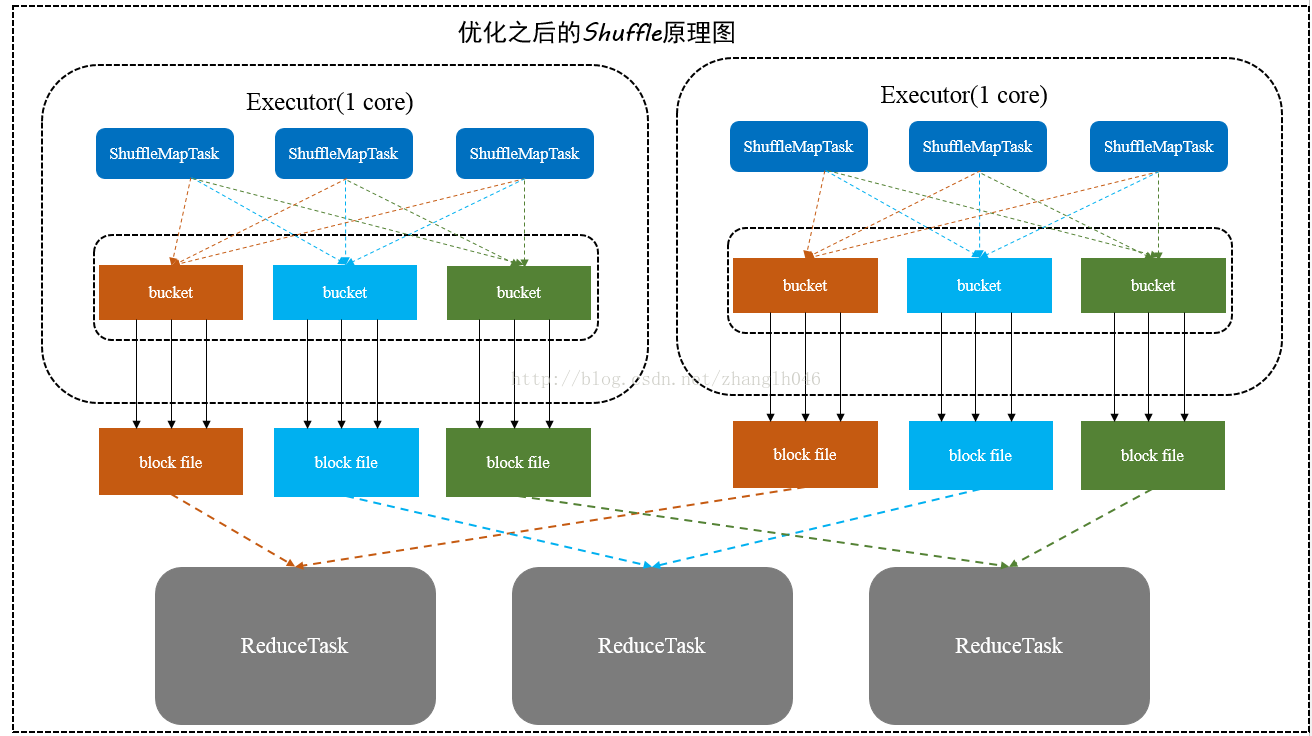
- 每一个Excutor进程根据核数决定Task的并发数
- ShuffleMapTask根据Task的数量创建R个bucket,按照key进行hash放到不同的bucket中(每一个bucket中对用一个block)
- 下一个Task创建的时候,就不用再创建新的Bucket和Block直接复用之前的就行。
- 优缺点
- 减少了小文件的数量(优点)
- 如果Reduce端并行任务过多的话或者是数据分片过多的话,还有有很多的小文件产生
1.2 Sorted-Based Shuffle
目的:缓解Shuffle过程中小文件过多的问题
方法:引入类似于Hadoop的Map-Shuffle机制
- 每一个ShuffleMapTask不会创建单独的文件,而是将所有的Task的结果写入到同一个文件,并且生成对应的索引文件。
- 之前是所有的数据都要写入到内存(可能出现内存溢出),现在内存写不下的数据可以进行磁盘溢写
-
Sort-Base Shuffle几种不同的策略:BypassMergeSortShuffleWrite。SortShuffleWriter和UnsafeSortShuffleWriter
- 对于BypassMergeSortShuffleWriter,使用这个模式特点:
- 适用于Reducer任务 比较少的情况
- 适用于处理不需要排序和聚合的Shuffle操作,数据直接写入文件
- 将每一个分区写入到单独的文件,最后进行合并,减少文件的数量,但是需要并发打开多个文件,对内存的消耗比较大
- 对于SortShuffleWriter
- 适用于数据量很大的场景或者是集群规模很大的场景
- 引入外部排序器,可以支持在Map端进行本地聚合或者不聚合
- 外部排序器enable了Spill功能,内存不够用的时候就会将数据溢写到本地磁盘,最后将本地磁盘和内存进行合并
- 对于UnsafeShuffleWriter由于需要谨慎使用,我们暂不做分析















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









